Text-based Gender Prediction for Cyberbullying Detection and Online Safety Monitoring
| ✅ Paper Type: Free Essay | ✅ Subject: Computer Science |
| ✅ Wordcount: 4017 words | ✅ Published: 18 May 2020 |
Text-based Gender Prediction for Cyberbullying Detection and Online Safety Monitoring
Abstract— This digital world is an invention of friendships through social networks, communication done electronically and online relationships. One may have thousands of ‘friends’ without even seeing them or knowing their real life. In this kind of set up, it is fairly easy to provide a false name, age, gender and location to hide one’s true identity. It is therefore useful if social networking profiles could be cross verified and monitored for false identities on the basis of automated text analysis. This paper aims to provide detailed methods of the various text-based analysis performed which includes streaming twitter trending data, preprocessing the data, extracting various text features and classifying them based on gender for machine learning. Here, five models have been compared across a range of training and test dataset to determine which model performs best certain combinations using evaluation methods.
Keywords— cyberbullying, twitter streaming, machine learning, classifiers, safety monitoring, harmful tweets
I. Introduction
In recent years, social networking sites have taken a tremendous rise in people’s interests. Websites like Twitter, Facebook and Quora have expanded well enough to grab the interests of people irrespective of gender. However, it is also easy for many people to provide false identities like false age, gender, location and name. It is easy for online criminals, bullies and human traffickers to target their victims without the worry of getting caught. Online Law enforcement agencies and social network moderators find it difficult to track down the criminals manually as it is quite impossible to identify them due to a number of fake profiles posing as adolescents. It therefore, become necessary to use automated techniques to help narrow down the search. This can not only be limited to social media general data, it can also be used for something called as authorship characterization [1]. This method helps find variation between authors to maybe detect plagiarism or authenticity in their work. This is an altogether separate and interesting field of study with some common techniques used in this paper.
The importance of cyberbullying and author profiling is quite a serious matter and about 10% to 40% online users are victims of it. Most recently in October 2017, a Swedish model Arvida Bystrom was cyberbullied to the extent of receiving rape threats after she appeared in an advertisement with hairy legs [2]. These kind of trolling and cyberbullying is being laughed upon by common media and users but the impact it can have on the victim could be terrifying and painful.
Natural language processing has enabled many researchers to detect bullying and aggressive behaviour in recent years. In this paper, we focus these phenomena on Twitter and it could be further spread out to other social networking sites with a different dataset. There are a few obstacles while using Twitter: Firstly, Twitter has a short word count and may have many grammatical mistakes. Secondly, despite spam detection twitter has many spam accounts and filtering them out may be a difficult, manual task for now. Thirdly, each tweet provides fairly little context. So, taken on its own, a mean or aggressive tweet may not seem aggressive unless read along with other comments on the similar context. Finally, the speed at which the chat language is developing, one of the most ongoing challenge would be to constantly train the algorithms to pick up new variations in the language used online.
The rest of the paper is organized as follows. Section II provides a short literature survey on studies on cyberbullying and twitter gender analysis. Section III provides a presentation of the dataset and solutions to some limitations. Section IV gives a detailed description of the pre-processing involved in putting together a ready to model dataset. Section V would help analyse the sentiment analysis performed on tweets pertaining to their subjectivity and polarity. Section VI has some visualization of the most commonly used words in the dataset by males and females using word clouds. Section VII and VII get into detail about feature extraction and model generation. Section IX runs some evaluation procedures performed. Section X has explanation about a basic application on python that uses logistic regression to predict live data by taking an input by the user. Finally, concluding with the measures taken by social networking companies to curb fake profiles in XI.
II. related work
A number of researchers have demonstrated the extraction of gender using text-based analysis. Below are a few ones that encouraged me with their techniques and clarity to take on this as my research topic.
In [3] the authors have used personality traits for gender classification. They go on to implement something called the Big Five Personality Model which are Openness to experience, Conscientiousness, Extroversion, Agreeableness and Emotional Stability. The use of Stylometry is another interesting study used for author profiling described in [4]. The author also explains the impact of an unbalanced dataset which quite probably will affect any kind of dataset streamed on social media. Supervised learning approach was used by [5] where they used a Support Vector Machine classifier using WEKA [6]. In [2] the authors have used Deep Neural Networks namely CNN, LSTM and BLSTM across three social media platforms. They use dropout layers to tackle overfitting and all models were trained using backpropagation where the neural networks signal the data forward to completion and ten back propagates information about any error to alter any parameters. The author in [7] writes extensively on author profiling and its usage in personality recognition. He explains which part of the brain controls the social skills, which part of the brain produces speech and how these can be used in reading facial expressions in people. This is the very area of the brain responsible for processing style words in a person. In [8] the author explains the importance of awareness on cyberbullying. He explains the types of cyber bullying to be online flaming, online harassment, denigration, impersonating, outing, trickery, exclusion and trolling. The author states that boys are more inclined to be involved in cyberbullying than girls. He mainly researched on Facebook, Twitter and MySpace.
How much of the internet is fake? According to an article by the Intelligencer [] about 60% of the internet is used by humans and the remaining is run over by bots. Also, about half of YouTube traffic is dominated by bots masquerading as people. This is pretty shaky as most of the validation YouTubers receive seem to be fake profiles.
III. datasets
Size of datasets plays a vital role in training machine learning algorithms. As mentioned earlier, it is pretty important to use latest datasets in order to keep up with the latest trend in online language. The model has to be trained with the latest data if it would be used to predict data that is relevant on this very day. So, instead of using already available data which could be pretty old and irrelevant, data could be streamed using Twitter streaming API [9]. This would ensure up to date language and also live streaming is an added knowledge. The data for my research is streamed using the Tweepy API. Firstly, Twitter needs to be logged in on developer’s mode and an app needs to be created. The app will provide a consumer key, consumer secret key, access key and access secret key. These credentials are then passed to Tweepy as given below:
auth=tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_key, access_secret)
api = tweepy.API(auth)
The columns required can be predefined so as to stream only necessary data.
Extra columns like location, co-ordinates and user description were streamed for further use. The tweet itself proved to be insufficient for processing as the maximum character count is merely 280 words. And the most common length of a tweet is 33 characters. We then combined the user description (if provided) along with the actual tweet for pre-processing. This increased the word count to an extent which was helpful. The data in the current dataset looks somewhat like the below graph in Fig. 3.1. It is unbalanced but this is real time data so an unbalanced set is expected.

Fig 3.1
IV. Pre-processing
Pre-processing is important when it comes to data taken from platforms like Twitter as the word count is short and people tend to use short forms of words. Along with this, there is the use of symbols, emoticons and punctuations which need to be filtered out. The NLTK library is used for filtering out certain stop words. A few techniques have been used to help increase the word count. nltk.corpus and nltk.tokenize were used to import stop words and for word tokenization respectively.
Basic tweet pre-processing can be done using a pre-processing library called Pre-processor which is a library for tweet data written in Python. Basic cleaning could be achieved using p.clean().
The tweets are further pre-processed using various steps.
Fake account removal: All the tweets were manually looked into and if they seemed to be fake accounts they were simply removed. If it was a business account or a general fan page, these were removed too. There could be multiple people running such accounts and it would be useless to use such accounts for training.
Stop words removal: The NLTK library comes to action where the stop words are removed. Stop words removal tend to take out the dimensionality of the data. The corpus is left with key words that are easier to identify. NLTK has a huge list of stop words which do not require us to provide these words manually. All we need to do is provide the language in which the tweets need to be rid of stop words which in this case would be English.
Extra twitter characters removal: Sometimes after tweepy pre-processing using Preprocessor, the colon after mentions is left along with a RT(re-tweet) sign at the beginning of the tweet that might look like this ‘‚Ķ. This is manually removed and replaced with null. Consecutive non-ASCII characters are removed and replaced with spaces.
Emoticons & punctuations: A set of happy emoticons and a set of sad emoticons are predefined. These emoticons are then concatenated and stored for further use explained later in this paragraph. The “re” module is used to work with regular expressions. A regular expression is a sequence of characters helps match, find or in our case compile a set of strings or even just a string. It uses a specialized syntax held in a pattern. Re.unicode is used for matching unicodes of emoticons, symbols & pictographs, transport & map symbols, flags in iOS phones.
The works are then tokenized and checked against stop words, the emoticons and punctuations. If none match the tweet is appended else filtered out.
Lemmatization: This is an essential morphological process of pre-processing module during feature extraction [10]. The lemma of a words is the base form and inflicted forms. For example, words like voting, voted, etc have vote as their lemma. Lemmatization need to have additional dictionary support as it would need a good amount of searching and indexing. In this research an automatic lemmatization model is used from the NLTK library, nltk.WordNetLemmatizer. This is a convenient, free and large lexical database for English.
V. Sentiment Analysis
When it comes to cyberbullying, filtering out negative tweets would be required. There are many tools available to classify the tweets based on sentiments like Vadar and SentiStrength [9]. It would be better to use some kind of tool for this task as the keywords or word database set by you would not be sufficient or relevant enough and will generate false polarities.
In this paper, TextBlob is used to determine the sentiment of the tweet. The cleaned tweet column is used as the input without the description of the user as that would falsify the results. TextBlob is yet another powerful natural language processing library in python. It built upon NLTK and provides an easy use interface with NLTK [11]. The filtered tweet is fed to TextBlob which returns with the tweet sentiment, subjectivity and polarity. Subjectivity is mainly a judgement shaped by personal opinion rather than any outside influences. Polarity is the sentiment orientation, which could be positive, negative or neutral. Below, graphs show the positive and negative polarity for male and female we could establish with out dataset. X-axis determines the range of positive or negative sentiment.
The polarity of the tweet could range from 0-25 from out data and the higher the number, the higher a negative or positive sentiment as shown in Fig 5.1 & 5.2. Similarly, subjectivity could be calculated as higher the value more subjective the tweet is an lower the float value, more objective the tweet is.
Ideally, its ideal to filter out negative tweets and use them for classification but when tried on the current dataset it significantly reduces the number of tweets and so, for now, the complete dataset was utilized.

Fig 5.1

Fig 5.2
VI. Word Cloud
A word cloud was generated on R to look at what kind of words were used by males and females generally. The R package “wordcloud” could be used for this. ColorBrewer has some amazing palettes or variation in color. It could be one tone, multiple tones or color gradient as the word count reduces or increases. The word clouds below are randomly colored with a variation in size. The words with highest occurrence in each gender is the largest followed by the rest.

Fig 6.1 Female Word Cloud
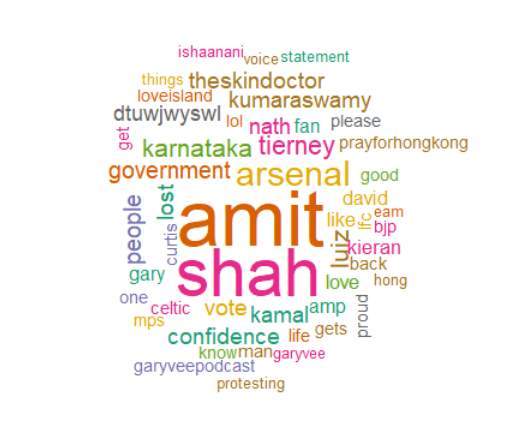
Fig 6.2 Male Word Cloud
VII. Feature extraction
When any kind of model is used Eg. Logistic regression, Random forest trees or Support Vector Machine we can only input numerical values. How could this be possible with the language we are using? This is where natural language processing comes into picture. It converts all the words i.e. take texts from our input, convert them into features and feed it to the model. Count Vectorization helps achieve feature extraction. It has a couple of important parameters that we use. The first is max_features() This is basically used to set up how many features or words would you intent CountVectorizer() to count. The most frequently used features will be dropped and the top number of features provided will be vectorized. We can also add a stop words list to CountVectorizer for better extraction. A train and transform can then be performed using CountVectorizer.fit_transform().
VIII. model generation and machine learning
Modeling is performed using sklearn model selection using five algorithms namely Naive Bayes, Random Forest Trees, Logistic Regression, Support Vector Machine and Decision Trees.
The algorithms have been modeled using Random Split and K-Fold methods. Let’s look further to see the difference in the models.
Naïve Bayes: Supervised learning algorithm which is one of the oldest and used quite frequently. It calculates the probability based on feature engineering and collects information quicker than other classifiers. The disadvantage that we face here is that it fails to understand interactions between criteria. For example, A person may like Bread and a person may like juice. But, it isn’t necessary a person may like bread and juice together. It is fast, and reliable if those are the things you are looking for. In this experiment, Naïve Bayes could gather about 78% accuracy for 40% training data and reduced as the training data was increased. Naïve Bayes proves to perform well on less amount of data. Fig 8.1 shows the evaluation and confusion matrix.

Fig 8.1
Random Forest: Random Forest Classifier is an estimator that can control over fitting and improve the predictive accuracy rate by averaging and sub-samples of dataset [12]. A random tree classifier is one of the most powerful algorithms we are using and yields good accuracy. It works in a way where it finds a number of decision tree classifiers and predicts a result by averaging them. It takes care of over fitting of data too. Fig 8.2 displays satisfying results.
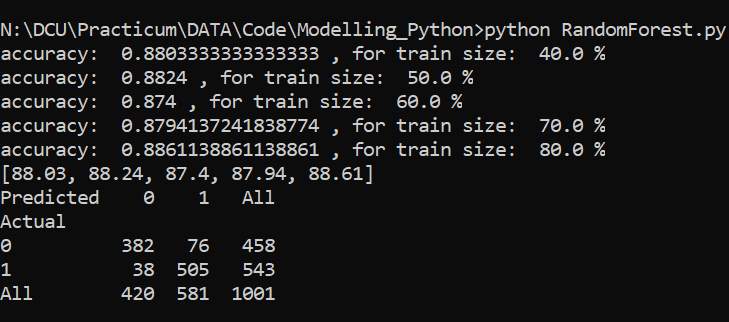
Fig 8.2
Logistic Regression: Logistical regression isknown to perform with high accuracies irrespective of the classes involved being linearly distinguishable. The input data, however, was not always linearly devisable, which is why kernel has been defined through the support vector machine classifier and places the data in a higher dimensional space where this classifier can easily categorize the data into the two stated divisible classes. The drawback, if you do specify one might be a problem where it might overfit the data. Fig 8.3 shows the evaluation and confusion matrix.

Fig 8.3
Support Vector Machine: Support Vector Machine or SVM is another powerful classifier which is a non-probabilistic classifier. It is a supervised linear learning algorithm and works in a nonlinear classification way. It creates or maps a separate space between the two categories with a new space, compares the two categories and creates it into a linear high-dimensional space. Figure 8.4 shows successful results.

Fig 8.4
Decision Trees: This is a fairly simple classifier and does not require the data to be linearly devisable. The male or female could be anywhere on the list and this would not affect the working of the classifier. They are super easy to understand and quick to give results. They have a good performance with this dataset as in Fig 8.5.

Fig 8.5
IX. Evaluation Setup
In the evaluation procedure five fold cross validation is used in order to determine if the data is in any way overfitting or underfitting. The folds of the dataset do contain unbalanced male and female counts but this is not always a bad thing. Especially when it comes to real time data, an unbalanced dataset is always expected. An accuracy graph was built that would show the difference in the five algorithms performance across various training & test datasets as shown in Fig 9.2.

Fig 9.1
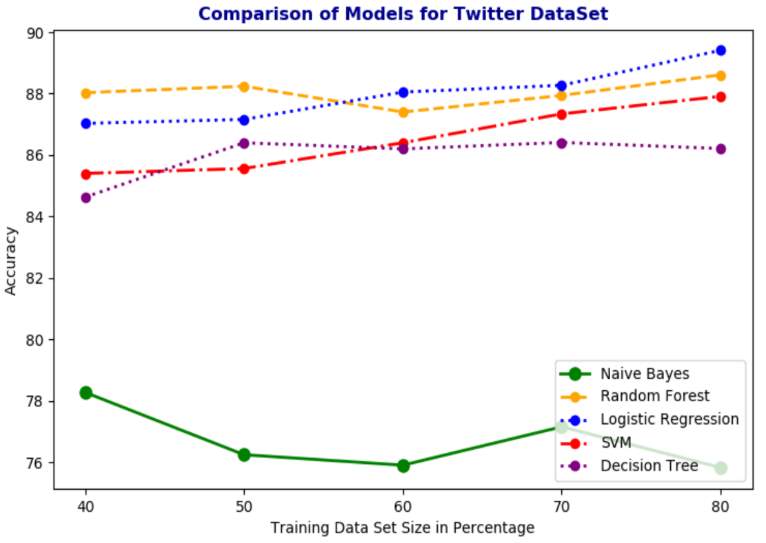
Fig 9.2
The top performers deduced were Logistic Regression, Support Vector Machine and Random Forest Classifiers. Hence, the evaluation is done on these classifiers. The Ten Fold cross validation was attempted, but it did not yield too different results and was extremely time consuming. The K Fold method results are displayed in Fig 9.3 below.

Fig 9.3
Stratified K fold evaluation technique has been used where the mean response value is approximately equal in all folds. There are about two types – Leave one out and K fold and among the two, K fold is more computationally challenging. The evaluation technique is to test how well the data has been trained upon and each data point comes to test [13].
X. Application potential
Using the Logistic Regression model a live prediction user friendly application could be developed using Python. The initial command line code is ready where the user has to put in the tweet and the model would retuen if it is a male or a female. Snapshots provided below.
Input Tweet and response for Male:

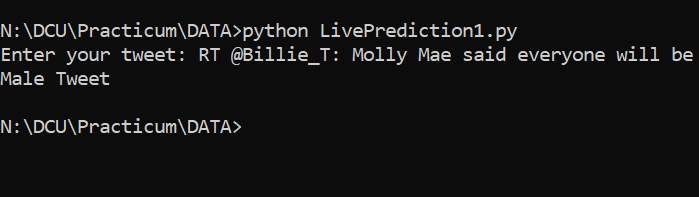
Input Tweet and response Female:

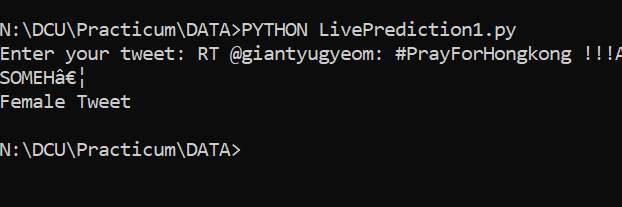
The data stored needs to be trained even more for 100% accuracy and this is still a work in progress but nevertheless, it is a raw working model that does the job.
This could be used for all social media platforms. The input could be a raw text with no cleaning done and straight out of the web page.
The future plan with this model is to use this data and take it to the next level to predict the age group of a person.
XI. Twitter reaction to aggression
It has gotten serious enough for social media platforms like Twitter, Facebook etc. to take matter in their own hands and try as much as possible to avoid impersonation and fake accounts. Twitter has impersonation policy where you can report a profile if you think it is fake or a spam account. Researchers claim that one out of 10 Twitter accounts are fake. If you do notice sometimes, when you click on an account it says, this account has been suspended. This might be a way for twitter to filter out abusive and fake accounts. According to an article, in 2017 and 2018, Facebook took down about 1.3 billion fake accounts over the past six months [14]. That is a whole lot of fake accounts to take down at one go. Facebook claims to have disabled the accounts within minutes of registration. Also, about 1.5 percent of these accounts were taken down after being flagged by users.
XII. conclusion
The rise on online activity has bought a rise in cyberbullyig and agression among users. The solution to just log out or delete an account is not a way to cope with this issue. The use of text base sentiment analysis and author profiling will help combat this situation to a great extent. Onling language will always be changing and diverse depending on age and gender making it a continuous piece of work. The algorithms used in varrious papers will help a great deal to conclude which one might be best along with its accuracy. Although the famous social networking sites do handle spam accounts in their own way, it becomes tedious as the users keep on increasing each day.
This part of resaerch will not only be used for detecting the gender but also personality recognition. It can be used for author profiling to detect fake personalities and check for plagarism. It can be used to further act as a predictive model where we could predict as to what topic might favour which gender among the audience.
From this reasearch, its dafe to conclude that Logistic Regression and Random Forest are the best algorithms for this model and they will be majorly studied for the age prediction as they seem to work well with the given dataset with its features. The dataset size also might not be enough to build a robust and good model with least error. The word count of each row should be increased so maybe focus on some other social networking sites too alonside Twitter. There were obstacles which were encountered during the research but nevertheless, this is an interesting area that will never go unused in the near future. It might be an initial stage to an AI that could detect false personalities and filter them out. Natural language processing is the current hot topic with unending real time data available. So yes, the opportnities for building knowledge and research in this area are endless.
XIII. Bibliography
|
[1] |
T. Kucukyilmaz, B. B. Cambazoglu, C. Aykanat and F. Can, “Chat Mining for Gender Prediction,” Bilkent University, Department of Computer Engineering, Turkey. |
|
[2] |
S. Agrawal and A. Awekar, “Deep Learning for Detecting Cyberbullying Across Multiple Social Media Platforms,” Indian Institute of Technology, Guwahati. |
|
[3] |
M. Arroju, A. Hassan and G. Farnadi, “Age, Gender and Personality Recognition using Tweets in a Multilingual Setting,” USA & Belgium. |
|
[4] |
J. van de Loo, G. De Pauw and W. Daelemans, “Text-Based Age and Gender Prediction for Online Safety Monitoring,” CLiPS – Computational Linguistics Group – University of Antwerp, Belgium. |
|
[5] |
M. Dadvar, F. de Jong, R. Ordelman and D. Trieschnigg, “Improved Cyberbullying Detection Using Gender Information,” Human Media Interaction Group, University of Twente, Netherlands. |
|
[6] |
A. Mohammad Rezaei, “Author Gender Identification from Text,” Eastern Mediterranean University , North Cyprus, July 2014. |
|
[7] |
F. Rangel and P. Rosso, “Use of Language and Author Profiling:Identification of Gender and Age,” Valencia & Madrid, Spain. |
|
[8] |
E. GUSTAFSSON, “GENDER DIFFERENCES IN CYBERBULLYING VICTIMIZATION AMONG ADOLESCENTS IN EUROPE.”. |
|
[9] |
D. Chatzakou, N. Kourtellis, J. Blackburn, E. De Cristofaro, G. Stringhini and A. Vakali, “Mean Birds: Detecting Aggression and Bullying on Twitter,” 12 May 2017. |
|
[10] |
M. Zubair Asghar, A. Khan, S. Ahmad and F. Masud Kundi, “A Review of Feature Extraction in Sentiment Analysis”. |
|
[11] |
U. Malik, “Python for NLP: Introduction to the TextBlob Library,” 15 April 2019. [Online]. Available: https://stackabuse.com/python-for-nlp-introduction-to-the-textblob-library/. |
|
[12] |
S. Ahmed, S. Hossain, G. Chowdhury and M. Mehnaz, “A Voice Signal Based Gender Prediction Model Using Random Forest Classifier”. |
|
[13] |
“Researchgate,” [Online]. Available: https://www.researchgate.net/post/What_is_the_purpose_of_performing_cross-validation. |
|
[14] |
“Facebook has disabled almost 1.3 billion fake accounts over the past six months,” Vex, 2018. [Online]. Available: https://www.vox.com/2018/5/15/17349790/facebook-mark-zuckerberg-fake-accounts-content-policy-update. |
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


DMCA / Removal Request
If you are the original writer of this essay and no longer wish to have your work published on UKEssays.com then please click the following link to email our support team:
Request essay removal