OpenMP Based Fast Data Searching with Multithreading
| ✅ Paper Type: Free Essay | ✅ Subject: Computer Science |
| ✅ Wordcount: 2215 words | ✅ Published: 09 Apr 2018 |
V.Karthikeyan, Dr. S.Ravi and S.Flora Magdalene
Abstract
The multiprocessor cores with multithreaded capability are continuing to gain a significant share and offer high performance. The use of OpenMP applications on two parallel architectures can identify architectural bottlenecks and introduces high level of resource sharing in multithreading performance complications. An adaptive run-time mechanism provides additional but limited performance improvements on multithreading and is maximized the efficiency of OpenMP multithreading as required by the runtime environment and the programming interface. This paper handles the task of data searching efficiently and a comparative analysis of performance with and without OpenMP is made. Experimental result shows accelerated performance over the existing methods in terms of various performance criteria.
Keywords: OpenMP (Open Multi Processing), Multithreading, Fast Data Searching, Multicore
Introduction
OpenMP is an adopted shared memory parallel programming interface providing high level programming constructs that enable the user to easily expose an application task and loop level parallelism. The range of OpenMP applicability is significantly extended by the addition of explicit tasking features.OpenMP is used for enhanced portability computation, where a dynamic workload distribution method is employed for good load balancing. However, the search network involved in the Viterbi beam search is reported by [5] statically partitioned into independent subtrees to reduce memory synchronization overhead. It improves the performance of a workload predictive thread assignment strategy and a false cache line sharing prevention method is required. OpenMP is a collection of compiler directives and library functions that are used to create parallel programs for shared-memory computers. It combines with C, C++ or Fortranto create a multithreaded program where the threads share the address space and make easier for programmers to convert single-threaded code to multithreaded. It has two key concepts namely;
Sequential equivalence: Executes using one thread or many threads.
Incremental parallelism: A programming that evolves incrementally from a sequential program to a parallel program.
OpenMP has an advantage in synchronization over hand-threading where it uses more expensive system calls than present in OpenMP or the code efficient versions of synchronization primitives. As a shared-memory programming paradigm, OpenMP is suitable for parallelizing applications on simultaneous multithreaded and multicore processors as reported in [11]. It is an API (application program interface) used for explicitly direct multi-threaded, shared memory parallelism to standardize programming extensions for shared memory machines is shown in Figure 1.
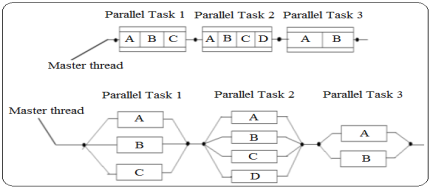
Figure1:Model for OpenMP Program using threading
At high-end, the microprocessors encompass aggressive multithreading and multicore technologies to form powerful computational building blocks for the super computers. The evaluation uses detailed performance measurements and information from hardware performance counters to architectural bottlenecks of multithreading and multicore processors that hinder the scalability of OpenMPin which OpenMP implementations can be improved to better support execution on multithreading processors. The thread scheduling based model with kernel and user space is shown in Figure 2.OpenMP applications can efficiently exploit the execution contexts of multithreading processors. The multi-threading models are;
- Master-Slave model,
- Worker-Crew model and
- Pipeline model

Figure 2:Multithreading processors using Kernel and User space
OpenMP Issues with Multithreading Approach
OpenMP specification includes critical, atomic, flush and barrier directives for synchronization purposes as shown in Table 1.
Table 1:OpenMP synchronization specification
|
Functions |
Purposes |
|
User-inserted locks |
Analogous to mutex locks in threads library. |
|
Critical directive |
Associates with a name and all unnamed critical sections map to the same name. |
|
Flushes directive |
Avoid false sharing and placed on different cache lines contiguously. |
|
Ordered directive |
Perform I/O in a sequential order and a parallel loop is avoided in threads. |
Effects of OpenMP for Multithreading Process
The effects of OpenMP for multithreading process arelisted in Table 2.
Table 2:Effects of OpenMP
|
Context |
Utilization/Accomplished Strategy |
|
Scaling of OpenMP on multithreading |
Effortless by the effects of extensive resource sharing. |
|
Multicore architectures with multithreading cores |
Gain designs to achieve the balance between energy. |
|
Execute threads within multithreading |
Utilized a single level of parallelism. |
|
Optimization criteria |
Energy, die area and performance |
The multithreading is required a solution which is scalable in a number of dimensions and achieve speedups. An efficient parallel program usually limits the number of threads to the number of physical cores that create a large number of concurrent threads. It describes the low-level Linux kernel interface for threads and the programs are invoked by a fork system call which creates a process and followed by an exec system call and loads a program to starts execution. Threads typically end by executing an exit system call, which can kill one or all threads.
Related Works
Daniel, et al., [2010] presented the compilation of synchronous programs to multi-threaded OpenMP-based C programs and guarded actions which are a comfortable intermediate language for synchronous languages. J. Brandt and K. Schneider [2009] presented separate compilation of synchronous programs. The target deterministic single-threaded code directly executes synchronous programs on simple micro-controllers. K. Schneider [2009] proposed the problem to generate multi-threaded C-code from synchronous guarded actions, which is a comfortable intermediate format for the compilation of synchronous programs. PranavandSumit [2014] proposed the performances (speedup) of parallel algorithms on multi-core system using OpenMP. C.D. Antonopoulos, et al., [2005] proposed multigrain parallel delaunay mesh generation and opportunities for multithreaded architectures. H. Jin, et al., [1999] proposed the OpenMP implementation of NAS parallel benchmarks and its performance.
M. Lee, et al., [2004] presented peak performance of SPEC OMPL benchmarks using maximum threads demonstration and compared with a traditional SMP. Zaid, et al., [2014] presented to implemented the bubble sort algorithm using multithreading (OpenMP) and tested on two standard data sets (text file) with different sizeF. Liu and V. Chaudhary [2003] presented a system-on-chip (SOC) design integrates processors into one chip and OpenMP is selected to deal with the heterogeneity of CMP.M. Sato, et al., [1999] proposed the compiler is installed to support OpenMP applications and GCC acts as a backend compiler.T. Wang, et al., [2004] presented the current flat view of OpenMP threads is not able to reflect the new features and need to be revisited to ensure continuing applicability.Cristiano et al., [2008] proposed reproducible simulation of multi-threaded workloads for architecture design exploration.Vijay Sundaresan, et al., [2006] proposed experiences with multi-threading and dynamic class loading in a java just-in-time compiler. Priya, et al., [2014] proposed to compare and analyze the parallel computing ability offered by OpenMP for Intel Cilk Plus and MPI(Message passing Interface). Sanjay and Kusum [2012] presented to analyze the parallel algorithms for computing the solution of dense system of linear equations and to approximately compute the value of OpenMP interface. S.N. TirumalaRao [2010] focuses on performance of memory mapped files on Multi-Core processors and explored the potential of Multi-Core hardware under OpenMP API and POSIX threads.
Explicit Multithreading Using Multithreads
The Explicit multithreading is more complex compared to OpenMP and dynamic applications need to be implemented effectively so as to allow user control on performance. The explicit multithreading based multithreads with C coding are shown in Figure 3.

Figure3: Explicit multithreading based coding in C
Scheduling for OpenMP
OpenMP supports loop level scheduling that defines how loop iterations are assigned to each participating thread. The scheduling types are listed in Table 3.
Table 3: Scheduling Types
|
Scheduling Types |
Description |
|
Static |
Each thread is assigned a chunk of iterations infixed fashion (round robin). |
|
Dynamic |
Each thread is initialized with a chunk of threads, when each thread completes its iterations, it gets assigned the next set of iterations. |
|
Runtime |
Scheduling is deferred until run time. The schedule type and chunk size can be chosen by setting the environment variable OMP_SCHEDULE |
|
Guided |
Iterations are divided into pieces that successively decrease exponentially, with chunk being the smallest size. |
Pseudo code:
#pragma omp parallel sections
{
#pragma omp section
do_clustering(0);
#pragma omp section
do_clustering(1);
#pragma omp section
do_clustering(2);
#pragma omp section
do_clustering(3);
#pragma omp section
do_clustering(4);
}
Optimizing Execution Contexts on Multithreading Process
The selection of the optimal number of execution contexts for the execution of each OpenMP application is not trivial on multithread based multiprocessors. Thus, a performance-driven, adaptive mechanism which dynamically activates and deactivates the additional execution contexts on multithreading processors to automatically approximate the execution time of the best static selection of execution contexts per processor. It used a mechanism than the exhaustive search, which avoids modifications to the OpenMP compiler and runtime and identifies whether the use of the second execution context of each processor is beneficial for performance and adapts the number of threads used for the execution of each parallel region. The algorithm targets identification of the best loop scheduling policy which is based on the annotation of the beginning and end of parallel regions with calls to runtime. The calls can be inserted automatically, by a simple preprocessor. The run-time linking techniques such as dynamic interposition can be used to intercept the calls issued to the native OpenMP runtime at the boundaries of parallel regions and apply dynamic adaptation even to un modified application binaries. It modifies the semantics of the OpenMP threads environment variable,using it as a suggestion for the number of processors to be used instead of the number of threads.
Results and Discussion
The experimental results of data searching with OpenMP tools (multithreading) and without OpenMP (no multithreading) tools are shown in Figure 4and Figure 5 respectively. In both the cases search time for data is evaluated and established OpenMP based implementation which is fast compared to data searching done without OpenMP tools.

Figure 4:Search time with OpenMP (Multithreading)

Figure5:Search time without OpenMP (No Multithreading)
The percentage of improvement in data searching with OpenMP (multithreading) tools is given in Table 4 and its graphical representation shown in Figure 6.
Table 4:Improvement with Multithreading
|
With OpenMP |
0.00046 |
0.00075 |
0.00758 |
|
Without OpenMP |
0.00049 |
0.00089 |
0.00949 |
|
Improvement Ratio (%) |
7 |
16 |
21 |

Figure6:Improvement in data Searching with OpenMP (in %)
The time elapsed to write data in file which is experimented with OpenMP and without OpenMP (search data) shown in Figure 7 and Figure 8 respectively.
Figure 7:Search datawith OpenMP

Figure 8:Search datawithout OpenMP
Conclusion
Searching a data in large data base has been a profound area for researchers. In this research work OpenMP Tools is used to perform multithreading based search. The motive to use OpenMP is that the user can specify a paralliazation strategy for a program. Here an experiment of data searching using multithreading is conducted for a data base. The experiments are conducted with and without OpenMP and their performance is presented. The results obtained shows that the time required for searching a data using OpenMP is less compared to data searching without OpenMP. The method presented shows improved performance over existing methods in terms of performance and parallaziation can be done in future. The main limitation of the research work is that its practical implementation requires same number of multicore units as that of the number of threads. Future research shall focus on use of parallel threads for high performance systems.
References
- Daniel Baudisch, Jens Brandt and Klaus Schneider, 2010, “Multithreaded Code from Synchronous Programs: Extracting Independent Threads for OpenMP”, EDAA.
- J. Brandt and K. Schneider, 2009, “Separate compilation of synchronous programs”, in Software and Compilers for Embedded Systems (SCOPES), ACM International Conference Proceeding Series, Vol. 320, pp. 1–10, Nice, France.
- K. Schneider, 2009, “The synchronous programming language Quartz”, Internal Report 375, Department of Computer Science, University of Kaiserslautern, Kaiserslautern, Germany.
- PranavKulkarni, SumitPathare, 2014, “Performance Analysis of Parallel Algorithm over Sequential using OpenMP”, IOSR Journal of Computer Engineering, Vol. 16, No. 2, pp. 58-62.
- C. D. Antonopoulos, X. Ding, A. Chernikov, F. Blagojevic, D. S. Nikolopoulos and N. Chrisochoides, 2005, “Multigrain Parallel Delaunay Mesh Generation: Challenges and Opportunities for Multithreaded Architectures”, in Proceeding of the 19thACM International Conference on Supercomputing (ICS’2005), Cambridge, USA.
- H. Jin, M. Frumkin and J. Yan, 1999, “The OpenMP Implementation of NAS Parallel Benchmarks and its Performance”, Technical Report NAS-99-011, NASA Ames Research Center.
- M. Lee, B. Whitney and N. Copty, 2004, “Performance and Scalability of OpenMP Programs on the Sun FireTM E25K Throughput Computing Server”, WOMPAT 2004, pp. 19-28.
- ZaidAbdiAlkareemAlyasseri, Kadhim Al-Attar and Mazin Nasser, 2014, “Parallelize Bubble Sort Algorithm Using OpenMP”, International Journal of Advanced Research in Computer Science and Software Engineering, Vol. 4, No. 1, pp. 103-110.
- F. Liu and V. Chaudhary, 2003, “Extending OpenMP for heterogeneous chip multiprocessors Parallel Processing”, Proceedings of International Conference on Parallel Processing, pp. 161-168.
- M. Sato, S. Satoh, K. Kusano and Y. Tanaka, 1999, “Design of OpenMP compiler for an SMP cluster”, Proc. of the 1st European Workshop on OpenMP, pp.32-39.
- T. Wang, F. Blagojevic and D. S. Nikolopoulos, 2004, “Runtime Support for Integrating Pre-computation and Thread-Level Parallelism on Simultaneous Multithreaded Processors”, the Seventh Workshop on Languages, Compilers, and Run-time Support for Scalable Systems, Houston, TX.
- Cristiano Pereira, Harish Patil and Brad Calder, 2008, “Reproducible simulation of multi-threaded workloads for architecture design exploration”, in Proceedings of the IEEE International Symposium on Workload Characterization, pp. 173-182.
- Vijay Sundaresan, Daryl Maier, PramodRamarao and Mark Stoodley, 2006, “Experiences with multi-threading and dynamic class loading in a java just-in-time compiler”, in International Symposium on Code Generation and Optimization, pp. 87–97, San Francisco, USA.
- Priya Mehta, Sarvesh Singh, Deepika Roy and M. Manju Sharma, 2014, “Comparative Study of Multi-Threading Libraries to Fully Utilize Multi Processor/Multi Core Systems”, International Journal of Current Engineering and Technology, Vol. 4, No. 4.
- Sanjay Kumar Sharma and Kusum Gupta, 2012, “Performance Analysis of Parallel Algorithms on Multi-core System using OpenMP”, International Journal of Computer Science, Engineering and Information Technology, Vol. 2, No. 5.
- S.N. TirumalaRao, E.V. Prasad, N.B. Venkateswarlu, 2010, “A Critical Performance Study of Memory Mapping on Multi-Core Processors: An Experiment with k-means Algorithm with Large Data Mining Data Sets”, International Journal of Computer Applications, Vol. 1, No. 9.
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


DMCA / Removal Request
If you are the original writer of this essay and no longer wish to have your work published on UKEssays.com then please click the following link to email our support team:
Request essay removal