Improving the Performance of Overbooking
| ✅ Paper Type: Free Essay | ✅ Subject: Computer Science |
| ✅ Wordcount: 2569 words | ✅ Published: 18 Apr 2018 |
Improving the Performance of Overbooking by Application Collocate Using Affinity Function
ABSTRACT: One of the main features provided by clouds is elasticity, which allows users to dynamically adjust resource allocations depending on their current needs. Overbooking describes resource management in any manner where the total available capacity is less than the theoretical maximal requested capacity. This is a well-known technique to manage scarce and valuable resources that has been applied in various fields since long ago. The main challenge is how to decide the appropriate level of overbooking that can be achieved without impacting the performance of the cloud services. This paper focuses on utilizing the Overbooking framework that performs admission control decisions based on fuzzy logic risk assessments of each incoming service request. This paper utilizes the collocation function (affinity) to define the similarity between applications. The similar applications are then collocated for better resource scheduling.
I. INTRODUCTION
Scheduling, or placement, of services is the process of deciding where services should be hosted. Scheduling is a part of the service deployment process and can take place both externally to the cloud, i.e., deciding on which cloud provide the service should be hosted, and internally, i.e., deciding which PM in a datacenter a VM should be run on. For external placement, the decision on where to host a service can be taken either by the owner of the service, or a third-party brokering service. In the first case, the service owner maintains a catalog of cloud providers and performs the negotiation with them for terms and costs of hosting the service. In the later case, the brokering service takes responsibility for both discovery of cloud providers and the negotiation process. Regarding internal placement, the decision of which PMs in the datacenter a service should be hosted by is taken when the service is admitted into the infrastructure. Depending on criteria such as the current load of the PMs, the size of the service and any affinity or anti-affinity constraints [23], i.e., rules for co-location of service components, one or more PMs are selected to run the VMs that constitute the service. Figure 1 illustrates a scenario with new services of different sizes (small, medium, and large) arriving into a datacenter where a number of services are already running.

Figure 1: Scheduling in VMs
Overload can happen in an oversubscribed cloud. Conceptually, there are two steps for handling overload, namely, detection and mitigation, as shown in Figure 2.

Figure 2: Oversubscription view
A physical machine has CPU, memory, disk, and network resources. Overload on an oversubscribed host can manifest for each of these resources. When there is memory overload, the hyper visor swaps pages from its physical memory to disk to make room for new memory allocations requested by VMs (Virtual Machines). The swapping process increases disk read and write traffic and latency, causing the programs to thrash. Similarly, when there is CPU overload, VMs and the monitoring agents running with VMs may not get a chance to run, thereby increasing the number of processes waiting in the VM’s CPU run queue. Consequently, any monitoring agents running inside the VM also may not get a chance to run, rendering inaccurate the cloud provider’s view of VMs. Disk overload in shared SAN storage environment can increase the network traffic, where as in local storage it can degrade the performance of applications running in VMs. Lastly, network overload may result in an under utilization of CPU, disk, and memory resources, rendering ineffective any gains from oversubscription. Overload can be detected by applications running on top of VMs, or by the physical host running the VMs. Each approach has its pros and cons. The applications know their performance best, so when they cannot obtain the provisioned resources of a VM, it is an indication of overload. The applications running on VMs can then funnel this information to the management infrastructure of cloud. However, this approach requires modification of applications. In the overload detection within physical host, the host can infer overload by monitoring CPU, disk, memory, and network utilizations of each VM process, and by monitoring the usage of each of its resources. The benefit of this approach is that no modification to the applications running on VMs is required. However, overload detection may not be fully accurate.
II. RELATED WORK
The scheduling of services in a datacenter is often performed with respect to some high-level goal [36], like reducing energy consumption, increasing utilization [37] and performance [27] or maximizing revenue [17, 38]. However, during operation of the datacenter, the initial placement of a service might no longer be suitable, due to variations in application and PM load. Events like arrival of new services, existing services being shut down or services being migrated out of the datacenter can also affect the quality of the initial placement. To avoid drifting too far from an optimal placement, thus reducing efficiency and utilization of the datacenter, scheduling should be performed repeatedly during operation. Information from monitoring probes [23], and events such as timers, arrival of new services, or startup and shutdown of PMs can be used to determine when to update the mapping between VMs and PMs.
Scheduling of VMs can be considered as a multi-dimensional type of the Bin Packing [10] problem, where VMs with varying CPU, I/O, and memory requirements are placed on PMs in such a way that resource utilization and/or other objectives are maximized. The problem can be addressed, e.g., by using integer linear programming [52] or by performing an exhaustive search of all possible solutions. However, as the problem is complex and the number of possible solutions grow rapidly with the amount of PMs and VMs, such approaches can be both time and resource consuming. A more resource efficient, and faster, way is the use of greedy approaches like the First-Fit algorithm that places a VM on the first available PM that can accommodate it. However, such approximation algorithms do not normally generate optimal solutions. All in all, approaches to solving the scheduling problem often lead to a trade-o↵ between the time to find a solution and the quality of the solution found. Hosting a service in the cloud comes at a cost, as most cloud providers are driven by economical incentives. However, the service workload and the available capacity in a datacenter can vary heavily over time, e.g., cyclic during the week but also more randomly [5]. It is therefore beneficial for providers to be able to dynamically adjust prices over time to match the variation in supply and demand.
Cloud providers typically offer a wide variety of compute instances, differing in the speed and number of CPUs available to the virtual machine, the type of local storage system used (e.g. single hard disk, disk array, SSD storage), whether the virtual machine may be sharing physical resources with other virtual machines (possibly belonging to different users), the amount of RAM, network bandwidth, etc. In addition, the user must decide how many instances of each type to provision.
In the ideal case, more nodes means faster execution, but issues of heterogeneity, performance unpredictability, network overhead, and data skew mean that the actual benefit of utilizing more instances can be less than expected, leading to a higher cost per work unit. These issues also mean that not all the provisioned resources may be optimally used for the duration of the application. Workload skew may mean that some of the provisioned resources are (partially) idle and therefore do no contribute to the performance during those periods, but still contribute to cost. Provisioning larger or higher performance instances is similarly not always able to yield a proportional benefit. Because of these factors, it can be very difficult for a user to translate their performance requirements or objectives into concrete resource specifications for the cloud. There have been several works that attempt to bridge this gap, which mostly focus on VM allocation [HDB11, VCC11a, FBK+12, WBPR12] and determining good configuration parameters [KPP09, JCR11, HDB11]. Some more recent work also considers shared resources such as network or data storage [JBC+12], which is especially relevant in multi-tenant scenarios. Other approaches consider the provider side of things, because it can be equally difficult for a provider to determine how to optimally service resource requests [RBG12].
Resource provisioning is complicated further because performance in the cloud is not always predictable, and known to vary even among seemingly identical instances [SDQR10, LYKZ10]. There have been attempts to address this by extending resource provisioning to include requirement specifications for things such as network performance rather than just the number and type of VMs in an attempt to make the performance more predictable [GAW09, GLW+10, BCKR11, SSGW11]. Others try to explicitly exploit this variance to improve application performance [FJV+12]. Accurate provisioning based on application requirements also requires the ability to understand and predict application performance. There are a number of approaches towards estimating performance: some are based on simulation [Apad, WBPG09], while others use information based on workload statistics derived from debug execution [GCF+10, MBG10] or profiling sample data [TC11, HDB11]. Most of these approaches still have limited accuracy, especially when it comes to I/O performance.
Cloud platforms run a wide array of heterogeneous workloads which further complicates this issue [RTG+12]. Related to provisioning is elasticity, which means that it is not always necessary to determine the optimal resource allocation beforehand, since it is possible to dynamically acquire or release resources during execution based on observed performance. This suffers from many of the same problems as provisioning, as it can be difficult to accurately estimate the impact of changing the resources at runtime, and therefore to decide when to acquire or release resources, and which ones. Exploiting elasticity is also further complicated when workloads are statically divided into tasks, as it is not always possible to preempt those tasks [ADR+12]. Some approaches for improving workload elasticity depend on the characteristics of certain workloads [ZBSS+10, AAK+11, CZB11], but these characteristics may not generally apply. It is therefore clear that it can be very difficult to decide, for either the user or the provider, how to optimally provision resources and to ensure that those resources that are provisioned are utilized fully. Their is a very active interest in improving this situation, and the approaches proposed in this thesis similarly aim to improve provisioning and elasticity by mitigating common causes of inefficient resource utilization.
III. PROPOSED OVERBOOKING METHOD
The proposed model utilizes the concept of overbooking introduced in [1] and schedules the services using the collocation function.
3.1 Overbooking:
The Overbooking is to exploit overestimation of required job execution time. The main notion of overbooking is to schedule more number of additional jobs. Overbooking strategy used in economic model can improve system utilization rate and occupancy. In overbooking strategy every job is associated with release time and finishing deadline, as shown in Fig 3. Here successful execution will be given with fee and penalty for violating the deadline.

Figure 3: Strategy of Overbooking
Data centers can also take advantage of those characteristics to accept more VMs than the number of physical resources the data center allows. This is known as resource overbooking or resource over commitment. More formally, overbooking describes resource management in any manner where the total available capacity is less than the theoretical maximal requested capacity. This is a well-known technique to manage scarce and valuable resources that has been applied in various fields since long ago.

Figure 4: Overview of Overbooking
The above Figure shows a conceptual overview of cloud overbooking, depicting how two virtual machines (gray boxes) running one application each (red boxes) can be collocated together inside the same physical resource (Server 1) without (noticeable) performance degradation.
The overall components of the proposed system are depicted in figure 5.
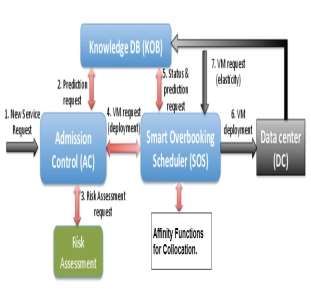
Figure 5: Components of the proposed model
The complete process of the proposed model is explained below:
- The user requests the scheduler for the services
- The scheduler first verifies the AC and then calculates the Risk of that service.
- Then already a running service is scheduling then the request is stored in a queue.
- The process of FIFO is used to schedule the tasks.
- To complete the scheduling the collocation function keeps the intermediate data nodes side by side and based on the resource provision capacity the node is selected.
- If the first node doesn’t have the capacity to complete the task then the collocation searches the next node until the capacity node is found.
The Admission Control (AC) module is the cornerstone in the overbooking framework. It decides whether a new cloud application should be accepted or not, by taking into accounts the current and predicted status of the system and by assessing the long term impact, weighting improved utilization against the risk of performance degradation. To make this assessment, the AC needs the information provided by the Knowledge DB, regarding predicted data center status and, if available, predicted application behavior.

The Knowledge DB (KOB) module measures and profiles the different applications’ behavior, as well as the resources’ status over time. This module gathers information regarding CPU, memory, and I/O utilization of both virtual and physical resources. The KOB module has a plug-in architectural model that can use existing infrastructure monitoring tools, as well as shell scripts. These are interfaced with a wrapper that stores information in the KOB.
The Smart Overbooking Scheduler (SOS) allocates both the new services accepted by the AC and the extra VMs added to deployed services by scale-up, also de-allocating the ones that are not needed. Basically, the SOS module selects the best node and core(s) to allocate the new VMs based on the established policies. These decisions have to be carefully planned, especially when performing resource overbooking, as physical servers have limited CPU, memory, and I/O capabilities.
The risk assessment module provides the Admission Control with the information needed to take the final decision of accepting or rejecting the service request, as a new request is only admitted if the final risk is bellow a pre-defined level (risk threshold).
The inputs for this risk assessment module are:
Req – CPU, memory, and I/O capacity required by the new incoming service.
UnReq – The difference between total data center capacity and the capacity requested by all running services.
Free – the difference between total data center capacity and the capacity used by all running services.
Calculating the risk of admitting a new service includes many uncertainties. Furthermore, choosing an acceptable risk threshold has an impact on data center utilization and performance. High thresholds result in higher utilization but the expense of exposing the system to performance degradation, whilst using lower values leads to lower but safer resource utilization.
The main aim of this system is to use the affinity function that aid the scheduling system to decide which applications are to be placed side by side (collocate). Affinity function utilizes the threshold properties for defining the similarity between the applications. The similar applications are then collocated for better resource scheduling.
IV. ANALYSIS:
The proposed system is tested for time taken to search and schedule the resources using the collocation the proposed system is compared with the system developed in [1]. The system in [1] doesn’t contain a collocation function so the scheduling process takes more time compared to the existing system. The comparison results are depicted in figure 6.

Figure 6: Time taken to Complete Scheduling
The graphs clearly depict that the modified (Proposed overbooking takes equal time to complete the scheduling irrespective of the requests.
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


DMCA / Removal Request
If you are the original writer of this essay and no longer wish to have your work published on UKEssays.com then please click the following link to email our support team:
Request essay removal