Effective Forecast of Phishing Sites using Machine Learning
| ✅ Paper Type: Free Essay | ✅ Subject: Computer Science |
| ✅ Wordcount: 1007 words | ✅ Published: 23 Sep 2019 |
Effective Forecast of Phishing Sites using Machine Learning
Abstract— Phishing is one of the attracting methods utilized by phishing craftsman in the aim of stealing the individual subtleties of unsuspected clients. The unsuspected clients post their information believing that these sites originate from confided in budgetary foundations. This paper utilizes Machine-learning supervised learning algorithm for demonstrating the expectation errand. To be specific decision tree classifier approach.
Key words: (Machine learning, Phishing, Supervised learning)
I. Introduction
Despite the fact that the web clients know about these kinds of phishing attacks, Lot of clients progress toward becoming unfortunate casualty to these attacks. Decision tree classifier approach in Machine Learning is useful to characterize phishing email by consolidating structural features in emails.
Phishing is ceaselessly developing as it is easy to develop a site by copying the source code and relatively easier to send across mails. Be that as it may, all the web clients are not expert in PC building and subsequently they progress toward becoming injured individual by giving their own subtleties to the phishing craftsman. Some of the areas like banking, insurance, easy money, and interesting looking games are few instances that are main carriers for luring.
The training data for supervised learning comprise of a lot of preparing models. In directed adapting, every precedent is a couple comprising of an information object and ideal yield esteem or output called the supervisory flag. A directed learning calculation examines the preparation information and produces a surmised capacity, which is known as a classifier. The classifier is then utilized for foreseeing the exact yield an incentive for any legitimate concealed input. The classification algorithm utilized for learning the site data is Decision tree induction.
.
II. Current work
Maher Aburous (2009) proposes a methodology for keen phishing discovery utilizing fuzzy data mining. Ram basnet (2008) used machine learning approach for identifying phishing attacks. One-sided support vector machine and neural systems are utilized for productive forecast of phishing messages.
Ying Pan and Xuhus Ding (2006) utilized inconsistencies that exist in the websites character, auxiliary highlights and HTTP exchanges to identify the ridicule site. It requests neither client mastery nor earlier learning of the site. Anh Le, Athina Markopoulou (2011), College of California utilized lexical highlights of the URL to anticipate the phishing site.
- Supervised Learning Algorithms
Under supervised learning standout amongst the most extensively used and viable techniques for inductive acceptance are the decision tree. In the decision tree, the occasions are arranged by arranging them dependent on assessment of feature values. A node in the tree compares to an element in an occurrence to be ordered. Each branch of the tree speaks to a value that the node can anticipate.
The C4.5 calculation is the most well-known calculation among the other decision trees. In the C4.5 decision tree, the tree can likewise be spoken to as set of in the event that tenets to enhance clarity and elucidation.
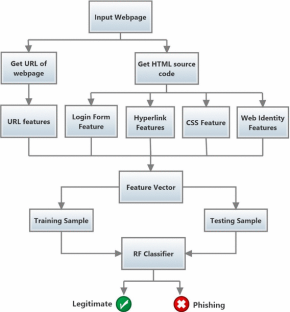
Figure1. Towards detection of phishing websites by Jain, Ankit Kumar. (2017).
Random Forest (RF) is another well known decision tree, which can be utilized for both classification and regression purpose. RF is a group of various decision trees freely prepared on chosen training datasets. The arrangement data is then dictated by casting a ballot among all the trained decision trees.
IV. Methodology
Feature extraction assumes a prominent job for the effective forecast of phishing sites. In a HTML source code there are numerous components that can recognize the first genuine site from the duplicate sites.
|
Feature |
|
|
foreign anchor, Nil Anchor |
On the off chance that the area name in the url isn’t like the one in page url then it is called as foreign anchor. Nil Anchor means that page is connected with none. |
|
IP Address, Dots in URL, slashes in url |
The IP Address is same as domain name for a fraudulent site. The phishing site will contain more than 5 dots or slashes in url. |
|
Foreign images, CSS |
The images and css are mostly redirected to another domain. |
|
SSL certificate |
Every genuine site will have SSL authentication. However, phishing sites do not have SSL declaration. |
|
Search Engine |
On the off chance that the site is real and if the page url is given to any web search, the initial 10 results delivered will be about the concerned site. |
|
Blacklist |
The url is verified against the blacklist. There would be chance that the page url is available in the blacklist. |
Results
The performances of the models are assessed dependent on the two criteria, the prediction precision and the preparation time. The dataset with 100 phishing sites and 100 genuine sites is taken for execution.
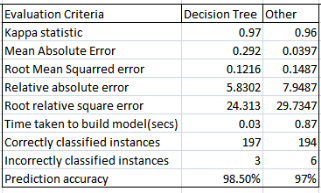
It is identified that the decision tree algorithm has better prediction accuracy and preparation time.
V. Conclusions
This research demonstrates the use of Machine learning approach to predict a phishing website using two performance criteria preparation time and prediction accuracy. It is proved that decision tree classifier performs well compared to other.
VI. Future Developments
In not so distant future we can expect to plan and execute an information base utilizing decide acceptance that can on ongoing cautions online clients of any plausibility of phishing attacks.
References
- Hossain M.A, Keshav Dahal, Maher Aburrous. (2010). Modelling Intelligent Phishing Detection System for e-Banking using Fuzzy Data Mining. Expert Systems with Applications. 37 (12), 7913-7921
- Santhana Lakshmi, Vijaya MSb. (2012). Sciverse ScienceDirect. Efficient prediction of phishing websites using supervised learning algorithms. 30 (30), 798 – 805
- Xuhua Ding, Ying Pan. (2006). Anomaly Based Web Phishing Page Detection. Computer Security Applications Conference. 39 (8), 381-392.
- Alec Wolman, Stefan Sarolu, Troy Ronda,. (2008) a user-assisted anti-phishing tool. Itrustpage. 42 (4), 261-272.
- I.H., Frank, E., Trigg, L., Hall, M., Holmes, G. & Cunningham, S.J. (1999). Weka: Practical machine learning tools and techniques with Java implementations. (Working paper 99/11). Hamilton, New Zealand: University of Waikato, Department of Computer Science.
- Ankit Kumar Jain, B. B. Gupta. (2018). towards detection of phishing websites on client-side using machine learning based approach. Telecommunications Systems. 68 (4), 687-700
- Srishti Rawal, Bhuvan Rawal. (2017). Phishing Detection in E-mails using Machine Learning. International Journal of Applied Information Systems. 12 (7), 21-24.
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


DMCA / Removal Request
If you are the original writer of this essay and no longer wish to have your work published on UKEssays.com then please click the following link to email our support team:
Request essay removal