Adopting MapReduce and Hummingbird for Information Retrieval
| ✅ Paper Type: Free Essay | ✅ Subject: Computer Science |
| ✅ Wordcount: 2088 words | ✅ Published: 03 Apr 2018 |
Adopting MapReduce and Hummingbird for Information Retrieval in dedicated cloud Environment
|
|
Abstract:
Data collected in section 3 indicated the number of active internet users across the globe. The collected chunks of information termed as Big Data not only utilizes physical resources into the network, but also leads to increase in human and financial resources. Cloud computing being a technology with IaaS (Infrastructure as a Service), PaaS (Platform as a Service) and SaaS (Software as a Service) provides virtual resources on pay per use policy. MapReduce being widely used Algorithm is used in line with Hummingbird Search engine for information retrieval.
Keywords: MapReduce, SaaS, IaaS, PaaS, Hummingbird, Big data
1. Introduction
One of the papers published in International conference at Jaipur, entitled “The Need and Impact of Hummingbird Algorithm on Cloud based Content Management System” [21] elaborates on existence of humming bird algorithm on 15th birthday of Google. In existence with previous Google algorithms like panda 3.5, page rank and penguin, hummingbird is a new replacement of full engine instead of repairing individual modules. This has affected 90% of data across the globe.
Migrating MapReduce algorithm on cloud environment using Hadoop, not only improves performance due to cloud features but also the efficiency is increased with cost minimization.
2. Problem

Fig-1: Data center Source: IBM Enterprise System
Fig-1 gives a snapshot of engineers working at data centers who manages information from diverse platforms and resources. Managing hardware and Network with virtualized resources needs dedicated young talent. When it comes to end user, he gets an average service as a result of improper management of data centers. MapReduce is one of the best known algorithms used for IR (Information Retrieval) in addition with existing algorithms as explained in section 7.
Due to exponential increase in smart devices that supports voice based search, definitely needs fast and efficient searching algorithm for information retrieval. The voice based search assists to make smart decisions in real time applications like place identification, weather forecast and medical assistance using android based applications.
3. Why problem is important
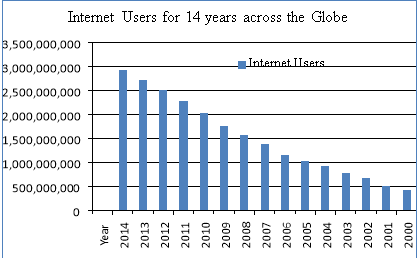
Fig-2: Global Internet users Source: W3 Foundation
Looking at data increase across the globe as shown in Fig-2 (data collected till July 1, 2014) [19], the pilled content in repositories is increasing worldwide. It requires huge amount of hardware resources running for years to extract information and knowledge for decision making. The big challenge in big data is ever increasing content utilizing human resource and cost to create chunks in available networks across the globe, which needs attention.
4. It is an unsolved problem
From the following relevant reviewed literature (table-1), it gives a blueprint that the problem has still remained unsolved. The authors have either focused on cloud components [6] [11] or had used traditional Google Components during the analysis. Since Hummingbird Algorithm [10] is not keyword based the searching criteria have changed. When combined with MapReduce [1] [3] [15] in cloud environment shall definitely yield efficient results with minimum cost and resources.
|
Sr. No |
Topic |
Paper Details |
Focused Area |
|
Image retrieval: research and use in the information retrieval |
Masashi Inoue National Institute of Informatics -2009 |
|
|
|
Survey of Cloud Computing Web Services for Healthcare Information Retrieval Systems |
Ismail Hmeidi, Maryan Yatim, Ala’ Ibrahim, Mai Abujazouh Proceedings of the International conference on Computing Technology and Information Management, Dubai, UAE, 2014 |
|
|
|
Evaluation of Information Retrieval in Cloud computing based services |
Mr. Kulkarni N. N., Dr. Pawar V. P., Dr. K.K Deshmukh Asian Journal of Management Sciences 02 (03 (Special Issue)); 2014; 20-22 |
|
|
|
Complex Event Processing :unburdening big data complexities |
Prakash rajbhog and Narayanan Chathanur Infosys Lab Briefing Vol-11 No-1, 2013 |
|
|
|
Beyond MapReduce : the next generation of big data analytics |
Brian Hellig, Stephen Turner Rich Collier Long Zheng ET International-2014 |
|
Table-1: Existing Systems compared
5. Here is my idea
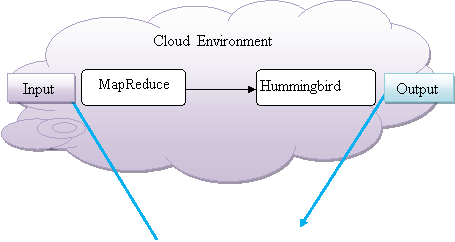

Fig-3: Proposed Information Retrieval System
Being cloud computing [4] [6] is upcoming Technology as discussed in section -7.2, is a good source of virtualized resources that helps to manage content on diverse platform irrespective of geographical boundaries. An instance of Hadoop that supports MapReduce Algorithm (elaborated in sec-7) is migrated in cloud environment using SaaS (Software as a Service) to whom input is diverted for processing. Hummingbird (more in section-7) Algorithm is a brand new search engine designed to understand meaning from acquired query instead of word, is imparted to collect output from MapReduce instance. The collected output on Amazon S3 cluster is efficiently and effectively delivered to end user based on voice based request, in addition to traditional systems for efficient decision making in the field of medicine, scientific research and so on.
6. My idea works
To confirm the working of proposed idea, a hosted instance of Hadoop was used that supports MapReduce Algorithm and S3 data cluster from Amazon. It also has Qubole [20] managed database to test the instance in cloud environment. Qubole has an API (Application programming Interface) that gives overview of running instances through dashboard. A user shall give input as a database or can manually select file in addition to query wizard.
Once the input is given to MapReduce cluster, data analysis shall be done by using hive query in addition to pig script.
Following results were collected by using existing database.

Fig-4: Cloud based Hadoop Instance Source: Qubole
Figure -4 shows a dashboard running Hadoop instance, in which 2 queries have finished data analysis. It communicates at runtime with Amazon S3 bucket where data is stored for input. The mapper [1][3][15] scans the data files from the source and extends the output to reducer. The reducer further processes data and is sent back to S3 cluster for further processing. This information shall be accessed by end user through web access and with the support of Hummingbird Algorithm.

Fig-5: Running Hadoop Cluster Source: Qubole
Fig-5 shows a single running Hadoop Instance in cloud environment. Qubole supports metrics of instances running simultaneously that enhances performance their by increasing efficiency. The graph in the above figure indicates time spent to complete single job. Every task is monitored by master DNS having unique ID. To each DNS a list of queries shall be given as input for further analysis.
Fig-6 shows process getting started on Hadoop Cluster that combines both map and Reduce session together. The jobs performed uses batch processing system for single instance. Running multiple instances on different clusters in cloud environment makes process more efficient without investing much is physical infrastructure. As a result of which end user shall enjoy the benefits of information retrieval with minimum time, cost and physical resources. As cloud supports pay per use policies resource allocation as per requirements becomes easier.

Fig-6: Hadoop Master DNS Source: Qubole
- Detail explanation about concepts
- existing algorithms used for information retrieval
- BFS(Bredth First Search)
- Redundant BFS.
- ISN (Intelligent Search Machine)
- Directed BFS
- Random walker search
- Randomized Gossiping
- Centralized approach
- Distributed Information retrieval
- Searching Object identifier
Following explanations shall help to elaborate more about specific areas.
7.2 Cloud Architecture

Fig-7: Cloud Architecture Source: NIST
Cloud is an upcoming technology that supports IaaS (Infrastructure as a Service) PaaS (Platform as a Service) and SaaS (Software as a Service) as shown in Fig-7.
For any hosted instance in cloud, open source software is used as a server that supports virtualization and Grid technology. Virtual private network is used in addition to broadband network13] [16]. As a service provider SLA (Service level Agreement) is signed between an organization and service provider. Distributed computing is one of the known components as data transferred across the network requires secure, authentic and efficient service in a given network.
The type of cloud includes public, private, community and hybrid cloud [2]. Private clouds are hosted in dedicated environment having firewall and other authentication features. Updating existing system and taking backup remains responsibility of the owner. Hybrid clouds may be hosted in private environment in synchronization with public resources. The end user held responsible for resources used in public cloud with minimum security.
7.3 MapReduce Algorithm

Fig-8: MapReduce Algorithm Source: Jimmy Lin, University of Maryland
The algorithm takes data input as a file or database in the form of query. A list of mapper instances are activated which travels across the database in search of information. The jobs or data values are shuffled based on keys and aggregated as an input to reducers. These reducers understand the key inputs and reshuffle to get unique relevant information for further processing as shown in Fig-8[1].
7.4 Hummingbird Algorithm
Hummingbird Algorithm [10] [21] is the latest birthday gift from Google. Panda 3.5 and penguin were basically filters applied to searching criteria in the form of web pages and hyperlink.
The traditional search engine extracts information based on keywords. Considering a sentence “How many times does hummingbird flap their wings per second?” the traditional search engine being keyword based tries to extract word like times, flap and per second. Based on collected keywords the web pages are searched in database. The collected content undergoes filtering from panda and penguin. Resultant results are displayed to user in the form of hyperlinks.
Being hummingbird is innovation in the field of search and meant for voice based information retrieval, it accepts query as a single sentence instead of keywords. The engine tries to understand meaning and creates knowledge base from provided information or query.

Fig-9: Hummingbird Search Source: Google.com
In fig-9, the query asked to Google was where am i? Using voice search. The search engine had found my current location based on IP address or physical location and displayed map for the same.
8. Conclusion and future work
The paper is continuation to hummingbird Algorithm [21] that supports MapReduce Algorithm with Hummingbird search engine in dedicated cloud environment. Qubole a hosted Hadoop instance is used to confirm working of MapReduce in support with Amazon S3 for data during. A single hive query instance on single DNS is tested which shall be extended for testing multiple instances of hive and pig script simultaneously as future work.
References
[1] Rahul Prasad Kanu , Shabeera T P , S D Madhu Kumar 2014- Dynamic Cluster Configuration Algorithm in MapReduce Cloud, International Journal of Computer Science and Information Technologies, Vol. 5 (3), 2014, 4028-4033.
[2] Mr. Kulkarni N. N., Dr. Pawar V. P., Dr. K.K Deshmukh -2014 Evaluation of Information Retrieval in Cloud computing based services, Asian Journal of Management Sciences 02 (03 (Special Issue))
[3] Brian Hellig, Stephen turner, rich collier, long zheng-2014- beyond map educe: the next generation of big data analytics HAMR.Eti.com.
[4] Ismail Hmeidi, Maryan Yatim, Ala’ Ibrahim, Mai Abujazouh, 2014 – Survey of Cloud Computing Web Services for Healthcare Information Retrieval Systems , International conference on Computing Technology and Information Management, Dubai, UAE.
[5] Anil Radhakrishnan and Kiran kalmadi -2013- Big Data Medical engine in the cloud, Infosys Lab Briefing Vol-11, No-1.
[6] Dr. Sanjay Mishra, Dr. Arun Tiwari 2013– A Novel Technique for Information Retrieval Based on Cloud Computing, international Journal of information technology.
[7] Yu Mon Zaw, Nay Min Tun 2013-Web Services Based Information Retrieval Agent System for Cloud Computing. International Journal of Computer Applications Technology and Research Volume 2– Issue 1, 67-71.
[8] Gautam Vemuganti 2013- Metadata Management in Big data, Infosys lab Briefing.
[9] Aaditya Prakash 2013-Natured Inspired visualization of unstructured big data, Infosys lab briefing, Vol-11, No-1.
[10] Xinxin Fan, Guang Gong,Honggang Hu-2011- Remedying the Hummingbird Cryptographic Algorithm, IEEE.
[11] Mosashi Inoue 2009- image retrieval: research and use in the information retrieval, National Institute of Informatics.
[12] Jeff Dean Google Fellow 2009- Challenges in Building Large-Scale Information Retrieval Systems.
[13] Tsungnan Lin, Pochiang Lin, Hsinping Wang,Chiahung Chen-2009-Dynamic Search Algorithm in Unstructured Peer-to-Peer Networks, IEEE.
[14] William Hersh -2008 Future perspectives Ubiquitous but unfinished: grand challenges for information retrieval, Department of Medical Informatics and Clinical Epidemiology, Oregon Health and Science University, Portland, Oregon, USA.
[15] Jeffrey Dean and Sanjay Ghemawat 2004-MapReduce: Simplified Data Processing on Large Clusters, Google.com.
[16] Mehran Sahami Vibhu Mittal Shumeet Baluja Henry Rowley 2003-The Happy Searcher: Challenges in Web Information Retrieval, google.com
[17] James Allan 2002-Challenges in Information Retrieval and Language Modeling, Report of a Workshop held at the Center for Intelligent Information Retrieval, University of Massachusetts Amherst
[18] Amit Singhal 2001- Modern Information Retrieval: A Brief Overview IEEE Computer Society Technical Committee on Data Engineering.
[19] tp://www.internetlivestats.com
[21] Dr. Piyush Gupta, kashinath Chandelkar 2012- The Need and Impact of Hummingbird Algorithm on Cloud based Content Management System, vol-2, issue-12, IJARCSSE journal.
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


DMCA / Removal Request
If you are the original writer of this essay and no longer wish to have your work published on UKEssays.com then please click the following link to email our support team:
Request essay removal