Sentimental Analysis of Twitter Dataset Using Python
| ✅ Paper Type: Free Essay | ✅ Subject: Information Technology |
| ✅ Wordcount: 1011 words | ✅ Published: 23 Sep 2019 |
PROJECT PROPOSAL
SENTIMENTAL ANALYSIS OF TWITTER DATASET USING PYTHON

CONTENTS
1. Introduction
2. Problem Statement
3. Statement of Need
5. Methodology
6. Programming Languages
7. Expected Results
8. Timeline
9. References
- INTRODUCTION
Microblogging website has become the most important source to find out all kind of information that the user needs. This is due to the real-time nature of microblogs where people post a variety of opinions on diverse topics. The topics vary from discussing current political issues to finding the rating of products based on the opinions. These opinions can be used to make different conclusions on different sectors of the modern world. But, finding the solutions based on this data is not an easy task. We have to depend on different sentimental analysis methods to find the solution. [1]. (Columbiauniversity-paper, 2019)
The project on Sentimental Analysis of Twitter data; based on each of the tweets on a taxi service running in a country, the best features can be identified.
- PROBLEM STATEMENT
The famous microblog Twitter is used to build a model that classify the data or merely called “tweets” into different sentiments based on their polarity. The sentiments are categorized as positive, negative or neutral. The analysis of data is achieved by a two-level mechanism. In the first level, word analysis occurs where each word is taken to determine the polarity. In the second level, the sentence is taken and analysis occurs by combinations of different words.
In our project, we use this sentimental analysis for identifying the taxi service Uber. Different features like payment, service, cancellation and safety are taken to find the best feature. Python is used in our project in the prediction of real-time Twitter data based on pattern classification and data mining algorithms.
- STATEMENT OF NEED
Data-driven techniques are the most powerful as well as necessary methods in taking decisions on the real world problems. We use the sentimental analysis in almost all fields like politics, health care, customer ratings and so on. So, there is a need to build algorithms that apply data mining techniques in the collection of opinion based data.
The project on analysis of Uber data from Twitter will help the company to find the good and bad features of the service. This will help the company to make improvements in giving the best customer service.
- LITERATURE REVIEW
Twitter is one of the most popular site where people respond to a variety of matters with strong viewpoints. Hence people have used the sentimental approach in Twitter data in various projects.
[2]“Data Mining Approach For Classifying Twitter’s Users”, a project done by Mashael Saeed Alqhtani and M. Rizwan Jameel used the sentimental approach. They classify social groups as terrorist and dissident so that it is possible to identify the anomalous user as soon as possible. For this first need to extract a certain set of features that are used to characterize each group using different data mining technique and these data are stored in the database. For this extraction sentiment analysis, text mining and opinion mining are used. The main goal is to calculate the similarities of selected user tweets with respect to features that are extracted. For this analysis, they are using Python Twitter Tools (PTT) called Tweepy. It is possible to detect anomalous groups by analyzing text from Twitter ( Data Mining Approach For Classifying Twitter’s Users, 2019).
[3] Muqtar Unnisa, Ayesha Ameen and Syed Raziuddin proposed “Opinion Mining on Twitter Data using Unsupervised Learning Technique” where the Twitter data set is clustered into positive and negative clusters using unsupervised machine learning technique like spectral clustering. The result of the analysis is represented as a scatter plot graph and hierarchical graph. They are using a spectral algorithm that reduces the eigen values for the similarity matrix and plotting the graph by using the K means algorithm. They also mention hierarchical clustering as another way to plot the graph by using the data points. From their analysis, they conclude that unsupervised learning can be used to solve the domain dependency. (Opinion Mining on Twitter Data using Unsupervised Learning Technique, 2019)
- METHODOLOGY
STEP 1: Dataset Collection
- Twitter dataset or the tweets are collected using Twitter API.
- Data collected based on particular keywords on Uber.
Example: payment, price, cancellation, safety.
- Done using Python library tweep.
STEP2: Data Cleansing
- Tweets are tokenized. (NLTK Library)
- Removal of symbols like “@” or “#” and URLs.
- Removal of Stop words.
- Lexical Normalization is done.
- Done using Python library numpy and nltk.
STEP3: Sentimental Analysis
- Classify based on three sentimental labels: positive, negative, neutral
- Naïve Bias Algorithm used to predict the sentiments.
- Done using Python library textblob.
STEP 4: Visualization
- Data visualization done by using matplotlib library of python or WordCloud.
DATA SET: Data set from Twitter containing Uber tweets.
ALGORITHM: Naïve Bias Algorithm
TOOLS: Python, Pycharm
PROGRAMMING LANGUAGE: Python
- EXPECTED RESULTS
The sentimental analysis of Twitter dataset on Uber taxi service is taken to find the polarities. Based on these polarities we can determine the feature that best describes its service.
- TIMELINE
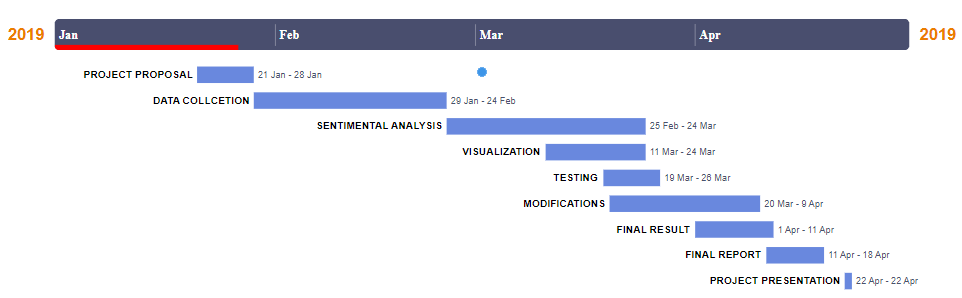
- REFERENCES
[1] Sentiment Analysis of Twitter Data. Apoorv Agarwal ,Boyi Xie, Ilia Vovsha, Owen Rambow, Rebecca Passonneau. Department of Computer Science ;Columbia University, New York, NY 10027 USA.
[2] Data Mining Approach For Classifying Twitter’s Users. International Journal of Computer Engineering & Technology (IJCET) Volume 8, Issue 5, Sep-Oct 2017, pp. 42–53, Article ID: IJCET_08_05_006. By Mashael Saeed Alqhtani and M. Rizwan Jameel Qureshi, Faculty of Computing and Information Technology, King Abdul-Aziz University, Jeddah, Saudi Arabia.
[3] Opinion Mining on Twitter Data using Unsupervised Learning Technique. International Journal of Computer Applications (0975 – 8887) Volume 148 – No.12, August 2016. By Muqtar Unnisa, Ayesha Ameen and Syed Raziuddin IT Dept Deccan College of Engineering and Technology Darussalam Hyderabad.
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


DMCA / Removal Request
If you are the original writer of this essay and no longer wish to have your work published on UKEssays.com then please click the following link to email our support team:
Request essay removal