CRISP-DM Model Application
| ✅ Paper Type: Free Essay | ✅ Subject: Information Technology |
| ✅ Wordcount: 2803 words | ✅ Published: 18 May 2020 |
A.)CRISP-DM Model
CRISP-DM (Cross-Industry Standard Process for Data Mining) is a data mining model developed by Daimler Chrysler (then Daimler-Benz), SPSS (then ISL) and NCR in 1999, CRISP-DM 1.0 version was published and is complete and documented. It provides a uniform framework and guidelines for data miners. It is a efficient and well-proven methodology. It consists of six phases or stages which are well structured and defined.
These phases are described below.
1. Business Understanding
2. Data Understanding
3. Data Preparation
4. Modeling
5. Evaluation
6. Deployment

Significance ofall the above-mentioned steps.
1.Business Understanding –
Identify the objective and frame the business issue, gatherinformation onresource, imperatives, suppositions, risksetc, Prepare AnalyticalGoal, Flow Chart.
2.Data Understanding –
Data Understanding period of CRISP DM Framework center around gathering the data, depicting and investigating the information. Investigating the information involves analysing the information.
3.Data preparation:
The data preparation belongs to the analyze phase of the DMAIC cycle, containing selection, clean-up, construction, integration and formatting of data as preparation for the modeling phase.
4.Modeling:
Once we complete the above steps, we have implementedthe necessity of ML and now we can proceed with the implementation of differentML algorithm. The algorithm to be selected depends completely on the businessrequirement, available data and the desiredoutcome. In an ideal situation, we should try differentalgorithm or combination ofalgorithm (Ensembles) to arrive at our final best algorithm.
5.Evaluation of the Model:
The Evaluation is assigned to improve phase of the DMAIC cycle. In this phase, the results are evaluated towards the data mining goals, used models and cost benefit relations. Here, checklists, internal benchmarking and statistical analysis can help to assess the results and create profitable improvement ideas. There aremany model evaluationtechniques like Accuracy, Sensitivity, RMSE (Root MeanSquare Error) and the list keepsgoing. Which evaluationmetrics to choose completelydepends on the evaluationcriteria, final model desiredoutcome, business requirementand the modelalgorithm used.
6.Deployment:
Finally, once the model iscreated, tested and evaluated on the Testand Validation data. The model undergoesdifferent realtime evaluation and testinglike A/B Testingand after all the approvalprocess, the code is pushedto the PROD/Live data.
APREP-DM: Framework for Automating the Pre-Processing of a Sensor Data Analysis on CRISP-DM
The requirement for analysing data is increasing in a rapid pace. Few examples include customer behavioural patterns in shops, the autonomous motion of robots, and fault prediction. Pre-processing of data is essential for achieving accurate results in any business. This includes detecting outliers, handling missing data, and data formatting, integration, and normalization. Pre-processing is necessary for eliminating ambiguities and inconsistencies. We use a framework called APREP-DM (Automated PRE-Processing for Data Mining) applicable to data analysis, including using sensor data. Here we evaluate two types of perspectives:
- pre-processing in a test-case scenario.
- comparing APREP-DM with the outcomes of other existing frameworks.
Analysing integrated data obtained from sensors or wearable devices in addition to using data on existing systems. Be that as it may, the precision of such investigations is restricted when bringing crude information legitimately into the estimations performed by business insight apparatuses. CRISP-DM includes a stage where the customer’s need and the achievement criteria of the venture dependent on “business understanding” are chosen. This system does not treat exceptions in the information arrangement step. In this way, the potential effect of anomalies on the task result makes CRISP-DM unsatisfactory for sensor-information examinations. CRISP-DM is in some cases utilized for other information mining framework base like APREP-DM since it doesn’t rely upon explicit items.
However, the accuracy of such analyses is limited when importing raw data directly into the calculations performed by business intelligence tools. CRISP-DM involves a step where the client’s priority and the success criteria of the project based on “business understanding” are decided. This framework does not treat outliers in the data-preparation step. Thus, the potential impact of outliers on the project outcome makes CRISP-DM unsuitable for sensor-data analyses. CRISP-DM is sometimes used for other data mining framework base like APREP-DM because it does not depend on specific products.

We can use APREP-DM in order to automate the parts of pre-processing of sensor data, including common data-cleaning tasks such as detecting outliers and handling missing data.
We mainly focus on the pre-processing step of the analysis model, which is further divided into two sub-steps. One of the sub-steps is common data-cleaning (e.g., detecting outliers or handling missing data); the other is transformation (e.g., extracting or integrating data, reconstruction, or adding new items) generate to integrate data into the model. Data-cleaning can be implemented by statistics or by clustering or classifying items. The business goals and the criteria for priority and success (in the “business understanding” step) can be used to arrive at the criteria for defining outliers and the way by which missing data can be filled. Thus, APREP-DM includes “business understanding” step before “detecting outliers” and “handling missing data” steps.
APREP-DM follows CRISP-DM which does not rely on specific products. “Business understanding”, “data understanding”, “pre-processing”, “modelling” and “evaluation”, are the three different process used in APREP-DM.
APREP-DM involves “business understanding” step at first, followed by “data understanding”, for selecting the final target data to be analysed in a sensor-data project. Step wise process are given as follows:
- Business understanding: Criteria defining priority and success by clarifying the client’s aim.
- Data understanding: In this step we must understand the data used for the project and evaluate the data if required.
-
Data Preparation:
- Automatically performing common data-cleaning tasks like, detecting outliers and handling missing data. This sub-step is automatically taken care in the process.
- We must perform the relevant transformations, e.g., extracting data, reconstructing of the dataset, to create a model suited to the final goal.
- Modelling: Selecting a model for Analysis, e.g., decision tree, or neural network.
- Evaluation: Using applications to evaluate the accuracy and versatility of the model.
- Deployment: Summarizing the process and sharing knowledges.
The two pre-processing steps, (3-1) and (3-2), are not performed simultaneously. Data-cleaning tasks are performed first. Other data-cleaning processes are performed subsequently.
APREP-DM is that it does not remove outliers during pre-processing. This is because outliers are used for detecting anomalies or unexpected behaviour. Thus, APREP-DM detects outliers, and removes them if necessary.
- During pre-processing by extending the CRISP-DM framework data-transformation tasks (e.g., to deal with outliers and missing data within datasets) were defined automatically.
- Interpreting the goal of the analysis and the success standards before pre-processing is very important.
A sensor-data analysis scenario verification of the efficiency of the proposed APREP-DM framework was done.
More studies are required in order to verify APREP-DM process by building system.
CRISP-DM MethodologyExtension for Medical Domain
In analysis ofdata there is a lack ofdetailing and specificity of theframework for executing miningin the medical field. CRISP-DMis a repetitive and hierarchicalprocess model, which gives us aframework that can beexpanded to a specific approachusing a generic. Six phases involvedin the process and better carefulnessare considered. The extension is termedas CRISP-MED-DM, that considers the specificchallenges related tomedicine. The CRISP-DM modelis used for mapping themedical application domain with itsdistinctive challenges and CRISP-DMreference model is improved.
Essentially, actualizing DM in drug has a lot of obstructions, for example, interdisciplinary correspondence, innovative, moral, and assurance of patient information can be experienced. In medical well-known problems such as fragmented and inaccurate information exist.
Issues that need to be considered:
- Mining multi-relational, spatial and temporal data(non-static).
- Personal, social, ethical data privacy restrictions.
- System interoperability on clinical data.
- Dynamic cooperation of clinicians for data gathering.
The main stage “Business understanding”was renamed to “Problemunderstanding” to evade equivocalimportance insidetwo alternate points of view, Moreover, the assignment”Define Objectives” has been split into”Define clinical goals” and”Define healthcaremanagement objectives”. Assess patientdata privacy and legalconstraints is presented asnew action keeping theissue of patient informationsecurity a noteworthylimitation.
CRISP-MED-DM addressesthe challenges and issues of Data Miningapplication in medical domain. In the proposedextension of the industrystandard CRISP-DM referencemodel, 38 generic and specializedtasks have been introduced.
Today, CRISP-MED-DM undergoespractical execution incardiology domain.
Holistic Extension to the CRISP-DMModel – Data Mining Methodology forEngineering Applications (DMME)
Due to the fastincrement in demand for theaccessibility of the manufacturing-relateddata. One reason forincrease in data istechnologies emerging in thefield of sensor connectivity andsensor integration. The Industrial Internet of Things (IIOT)and Cyber-physical Production System (CPPS)has consistently developingspecialized potential outcomes. we are not using thetremendous extent of socialaffair related information to its fulldegree. It could be utilizedfor strategy improvementor seeing of individualmachines.
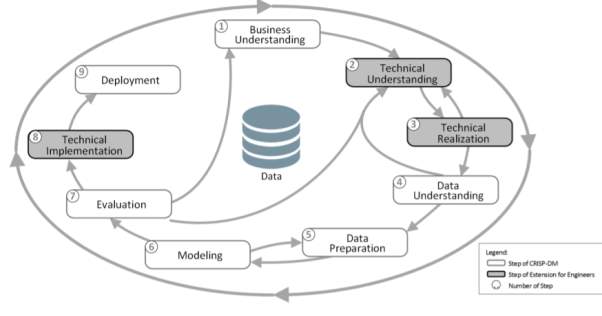
As domainspecific issues in getting and processingthe isn’t secured byCRISP-DM and since there are nodata-mining techniquesfor the specializedcomprehension of articles, for example, machinesand generation processand there is no arrangement for theacquirement of data fromsensors and by techniquesfor machine controls, we characterizeDDME, Data Mining Methodologyfor Engineering Applications, an expansionof CRISP-DM, which gives an all-encompassinganswer for the creativeterritory. It gives a view to theexamination of information identifiedwith the creation area. DDME gives theprimary answer for guide and archivesthe procedures inside informationmining ventures in the buildingspace. DDME provides the first solution toguide and documentsthe processes within data miningprojects in the engineeringdomain.
B). ‘Big Data’ Mining
Big Data is a term used to identify the datasets those size is beyond theability of typical databasesoftware tools to store, manage andanalyse. Big Data introduceunique computational andstatistical challenges, includingscalability and storage bottleneck, noise accumulation, spurious correlation and measurement errors. These challenges are distinguished and require new computational and statistical paradigm. Data are collected and analysed to create information suitable for making decisions. Hence data provide a rich resource for knowledge discovery and decision support. Database is a collection of data where data can be accessed, managed, and updated easily.
Data mining is the process discovering interesting knowledge such as associations, patterns, changes, anomalies and significant structures from large amounts of data stored in databases, data warehouses or other information repositories. Data mining uncovers interesting patterns and relationships hidden in a large volume of raw data. Big data is a heterogeneous collection of both structured and unstructured data. Businesses are mainly concerned with managing unstructured data. Big Data mining is the ability of extracting useful information from these large datasets or streams of data which were impractical before because of its volume, variety, and velocity.
ISSUES AND CHALLENGES-
The process of applying advanced analytics and visualization techniques to huge data sets to uncover hidden patterns and unknown correlations for effective decision making is part of Big Data Analysis. The analysis of Big Data involves multiple distinct phases which include data acquisition and recording, information extraction and cleaning, data integration, aggregation and representation, query processing, data modelling and analysis and Interpretation. Each of these phases introduces challenges.
Few big data mining challenges are as follows.
- Heterogeneity and Incompleteness
- Scale and Complexity
- Timeliness
- Security and Privacy Challenges for Big Data
Problem domains whereData mining technologies and toolsutilized are as per the following:
Market-based analysis – Consider a certaingroup of individuals purchasing a certain category of products, then this modeling method can be related as hypothesis that informs the category of products more probable to be purchased later by that specific group of individuals. Retailers can utilize this to know the idea of the buyer and they can alter the design of the store to suit the requirements of the client.
- Future Health Care – Usingdata mining we could improve health systems to a great extent. To improvecare and decreasecosts, we can differentiatethe prescribed procedures. The volume of patients (Unhealthy People) in everycategory can be predicted by the data mining. Suitable considerationand time can be given to patients at the correct time. It can indeed, even be utilized to identify any sort of fraud.
- Education –EducationalData Mining, which is concerned with thedevelopment of methods that discoverknowledge, from this information Studentsfuture learning behaviour can bepredicted by studying the effects of educational support. An institution can predict the student’s result by takingaccurate decisions andfocusing on what to teachand how to teach.
- CRM – Acquiringand retaining customers, and implementation ofcustomer focused strategies and improvingcustomer’s loyalty is managed bycustomer relationship management. Maintaining a good relationshipwith a customer and it is very important to collect and analyze the data and by applying mining technologies on the collected data seekers for retaining customers, gets solutions with filtered results instead being confused as of where to focus.
- Fraud Detection – Conventional strategies for detecting frauds are tedious and mind-boggling and billions of dollars have been lost to the activity of frauds. Using data mining aids, we can acquire meaningful patterns, valid and useful knowledge from the information in the form of data. The main ideaof a fraud detectionsystem is it should protectthe information of allusers. Acollection of sample records makes a supervisedmethod. These records accumulatedare then classified as non-fraudulent orfraudulent. A model isprepared using this data andalgorithm to identify whether the record isfraudulent or not.
Tasks performed during datamining
- Pre-Processing – With the useof techniques like generalization andaggregation, the anomalies anddisturbance from the data to bemined is removed and adding the missing values, normalizing thedata or compressing isdone.
- Clustering – A hugeset of classes in data is partitioned intorelated sub-classes.
- Classification – Identifying the user-definedcategories for labelling andclassifying data things.
Some examples of Data Mining Tools
- Rapid Miner – Rapid Minerprovides a user friendly, machine learning algorithms and rich library of data science through its all in one programming environment like rapid Miner studio, which enables undertakings to insert prescient investigation in their business procedure. It is utilized for business and commercial applications just as for research, training, rapid prototyping, and application development and supports all steps of the machine learning process including data preparation, results visualization, model validation and optimization. Along with the data mining features such as clustering, filtering, data cleansing, etc. it also provides features such as built-in templates, repeatable work processes, and consistent mix with various dialects, for example, R, Python which aides in quick prototyping. Feeble contents are good with this tool.
- Knime – Primarily used for data pre-processing — i.e. data extraction, transformation and loading, Knime is a powerful tool with GUI that shows the network of data nodes. Popular amongst financial data analysts, it has modular data pipe lining, leveraging machine learning, and data mining concepts liberally for building business intelligence reports.
- Data Melt – Data Melt, or DMelt, is an environment for numeric computation, data analysis and data visualization. DMelt is designed for analysis of large data volumes (“big data”), data mining, statistical analyses and math computations. The program can be used in many areas, such as natural sciences, engineering, modelling and analysis of financial markets. It provides IDE and Java API which can be used to call functions of the application directly. DMelt is used to create high-quality vector-graphics images (SVG, PDF, etc.) that can be included in LaTeX and other text-processing engines.
- Weka– Weka is a collection of machine learning algorithms for data mining tasks. The algorithms can either be applied directly to a dataset or called from your own Java code. Weka contains tools for data pre-processing, classification, regression, clustering, association rules, and visualization.
Data Mining and Business Intelligence
To have the option to utilize accumulated data is significant than simply assembling the data. What’s more, Subsequently, to change information into data and data into learning we utilize Business Intelligence (BI). Business Intelligenceis the best available way for optimizing decision making ability in business. To extract, refine and transform the data from transactional systems and unstructured data intostructured data for direct analysis we have defined a set of methodologies, applicationsand technologies termed asBusiness Intelligence.
Throughmining real behavioursand different data mining tools helps to provide better management techniques for maintaining better customer relationship. In the beginning, we should utilise business intelligence strategy on the information to maximize the company benefits. With the help ofData mining and BusinessIntelligence various industries, such as sales and marketing, healthcare organization or financial institutions, could have a quick analysis of data and thereby, improving the quality of decision-making process in their business.
References:
Part (A)
- Holistic Extension to the CRISP-DM Model – Data Mining Methodology for Engineering Applications (DMME)
- (Huber, Schneider, Dorothea & Steffen. (2018).
- APREP-DM: Framework for Automating the Pre-Processing of a Sensor Data Analysis based on CRISP-DM.
- (2019 IEEE International Conference on Pervasive Computing and Communications Workshops (Per Com Workshops), 10.1109/PERCOMW.2019.8730785)
- Oleg as, NIAKŠU Institute of Mathematics and Informatics, CRISP Data Mining Methodology Extension for Medical Domain. Baltic J. Modern Computing. 3. 92-109. (2015).
Part (B)
- Puneet Singh Duggal, Sanchita Paul, (2013), “Big Data Analysis: Challenges and Solutions”, Int. Conf. on Cloud, Big Data and Trust, RGPV
- N.P. Gopalan and B. Sivaselan book on Data Mining techniques and trends published by Asoke K. Ghosh, PHI learning private limited. Shivam Agarwal 2013 International Conference on Machine Intelligence and Research Advancement.
- Data Mining: Concepts, Models, Methods, and Algorithms. John Wiley & Sons. ISBN 978-0-471-22852-3. OCLC 50055336
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


DMCA / Removal Request
If you are the original writer of this essay and no longer wish to have your work published on UKEssays.com then please click the following link to email our support team:
Request essay removal