Development of a Recommender System
| ✅ Paper Type: Free Essay | ✅ Subject: Information Systems |
| ✅ Wordcount: 4466 words | ✅ Published: 18 May 2020 |
Chapter 1: Introduction
1.1 Overview
A recommender system is a specialized information filtering system that produces recommendations for products to its users (Vaidya and Khachane, 2017). These types of systems have become ubiquitous on the internet nowadays, this is mainly due to the large amount of data that is available to users. Movie recommendation is one of the key uses for recommender systems, this is due to the advent of streaming services such as Netflix that allow users to access seemingly unlimited libraries of content. These systems main purpose is to help users cope with information overload by helping them finding items that are of relevance to them. (Khusro, Ali and Ullah, 2016)
These specialised systems fall into one of three categories of recommendation sources, the other two being recommendations produced by other consumers and recommendations produced by human experts (Senecal and Nantel, 2004). In their research (Senecal and Nantel, 2004) found that users are heavily influenced by recommendations when choosing item online, with most people having a higher degree of trust into expert systems such as recommender systems when compared to the other two categories, even when these systems are perceived as having less knowledge about the items when compared to human experts.
This project aims at building a recommender system that is able to combine the efficiency of expert systems with the expertise of human experts. This is going to be achieved by building a system that will produce recommendations for critics instead of items. This will allow users to find experts in the sector, which share their tastes and will give the users the freedom to then explore the review produces by these critics and make decision about which movie to watch.
1.2 Why do we need Recommender Systems?
In recent years the increasing presence of movie streaming services has changed the way people consume content, with streaming services such as Netflix and Amazon prime video users have more choices that they ever had before. All these possibilities however can also have a negative impact on the users experience, many users can be overwhelmed by the options that are available to them and this can lead to people picking content they don’t really like or not picking anything at all due to loss of attention (Schwartz, 2016). This phenomenon has been observed by (Gomez-Uribe and Hunt, 2019) who found that the typical Netflix user spends 60 to 90 seconds browsing the Netflix library before losing interest in watching content on the service.
A solution to this problem is producing reliable and fast recommendation systems that are able to grant a high coverage of the content that is available even when presented with sparse data (Sarwar et al., 2001). These types of systems are used everywhere on the internet and have a vital role in ensuring the best possible experience for the user, one example if this is as mentioned before Netflix which reports that nearly 75% of content consumed by people on their service is the result of recommendations produced by their system. (Medium, 2019)
1.3 The challenges of recommendation systems
Recommender systems are distinguished by which technique they use to actually produce recommendations. The most widely used techniques for recommendation systems are Content-based filtering and collaborative filtering (Eirinaki et al., 2018). Both techniques function by creating user profiles. Each user has a profile which is a list of items that he has either rated or purchased (Eirinaki et al., 2018). The difference between these two algorithms is in the way they use these profiles.
In content-based filtering the items themselves are given a set of attributes that defines them. The user is then recommended items that have matching attributes to the ones in the user’s profile. Because each item has to have a set of attributes this technique introduces the need of analysing each item individually. (Ricci, Rokach and Shapira, 2015)
Collaborative Filtering on the other hand does not need data about the items, it only uses ratings that the users give to the items. These rating are used to find a given user’s “Neighbourhood”, which is the set of users that most closely match the current users taste, this set is then used to predict the rating that the user will give to items he has not seen yet. The items that receive the highest ranking are the ones that are recommended by the algorithm. (Ricci, Rokach and Shapira, 2011)
Producing reliable recommendation is a hard task especially when it comes to large amount of data. Even the best recommender systems have to face some inherent issues that come with producing reliable and fast recommendations (Khusro, Ali and Ullah, 2016). One of these issues is the so called “Cold Start Problem”, which occurs when a new users or items are introduced to the system, the lack of information about these new items in many cases will either result in bad recommendations or in no recommendations depending on the system. Another key challenge that occurs with recommender systems is the so called “Filter Bubble”, this effect causes users to be constantly redirected towards the same type of content, thus limiting the user’s freedom and choice (Nguyen et al.,2019). The reason for this effect is that in many recommender systems loops occur where a user will consume content that is recommended and the system based on this new data will keep recommending content of the same type, causing users to be stuck being recommended only a small amount of the content available and being granted only a small coverage of the items available (Nguyen et al.,2019).
1.4 Proposed solutions (change title of subsection)
The proposed system that is presented in this report will use model-based collaborative filtering in order to find the most similar critics to a given user. Model-based collaborative filtering uses machine learning algorithm to find patterns in the data and produce recommendations (Su, X. and Khoshgoftaar, T. ,2019), the system will use K-means clustering as its underlying model.
The system will address the issues that have been identified in section 1.3. Ideally the final solution should not suffer too much from these issues and should be able to give reliable and accurate recommendations to its users.
The first issue is the “Cold Start Problem” which is a key issue with most recommender systems, as mentioned earlier this problem occurs when new users or items without any information about them are introduced to the system. (Khusro, Ali and Ullah, 2016) present in their research a variety of solution to this problem, one of these solutions is to use a questionnaire that can help determine the taste of new users of the system. The questionnaire will ask users to rate a series of movie of different genres, one the movies are rated the system will compute average rating for each genre which are features used by the clustering model to find the most similar critics. The critic data is going to be obtained from an online dataset and will not change therefore the “Cold Start Problem” will not occur with this data since no new data is going to be added to the system. If new critics are added to the system, the average rating for each genre will be calculated before they are actually inserted in the system.
The second key problem that was identified in the creation of the so called “Filter Bubbles”. This problem is going to be addressed by recommending critics instead of individual movies, because critics rate a wide variety of content the user will still have the freedom of choosing which content to watch without being redirected to the same type of content by the system. This however can be an issue for some users since they might still fell overwhelmed by the amount of movies that the critics have reviewed, the effects of this problem are going to be monitored during the testing phase where users will be asked if they felt that the system helped them choose better movies or if they still felt overloaded by the choices that were available.
1.5 Report Structure
The report is going to be structured into chapter, in this section a brief overview of these chapters is given.
Chapter 2 of this report will present the background research that has been carried out. This research will include an in-depth view of collaborative filtering techniques, related work that has been done in the field and a study of the machine learning techniques that are going to be implemented.
Chapter 3 will present the requirement analysis that has been carried out as well as a list of functional and non-functional requirements for the recommendation system.
Chapter 4 is going to describe the specifications of this project; which include the libraries and programming languages used and the data that is going to be used by the system.
Chapter 5 is dedicated to the implementation of the final system; it will focus on the algorithms that have been implemented and will explain the challenges faced during the implementation stage and the solutions to these problems.
Chapter 6 will present the result of the testing that is going to be carried out, these results are going to be analysed in a critical manner to assure a fair evaluation of the system.
Chapter 7 is the last chapter of the report and will include the conclusion section of the report as well as possible future work.
Chapter 2: Literature Review
2.1 Recommender Systems
Recommender systems can be defined as software systems that are responsible for providing users with suggestions about items that may be of interest. These suggestions are then used to help the users of the system when choosing which items to buy, watch or listen (Ricci, Rokach and Shapira, 2011). An “item” is these types of systems is what the system is trying to recommend to its users, some examples of these items are: movies, music and websites (Ricci, Rokach and Shapira, 2011). For the purpose of this project the term item will be used to refer to movie critics which are what the produced software will recommend.
At their core recommendation system are based on ranking algorithms, these algorithms take into account data about its user’s likings and use this data to produced ranked lists which are then presented to its user as a “recommendation” (Ricci, Rokach and Shapira, 2011).
The information about the users is stored in a “user profile” which summarizes a person’s taste. The information in these profiles can be stored explicitly by storing rating that the owner of the profile gives to items he has seen or it can be stored implicitly by inferring a user’s likings from his actions. (Ricci et al., 2011) (Eirinaki et al., 2018).
Recommender Systems can be distinguished by the technique they use to produce these ranked lists of suggestions, these techniques can be grouped into three categories: collaborative filtering, content-based recommendation and hybrid recommendation (Cheng et al., 2016). In this report the collaborative filtering approach is going to be researched in depth due to it being the chosen approach for the system that is going to be implemented. The reason collaborative filtering has been chosen is that it is the most suitable technique for the data that is going to be used and it is the most popular and mature approach for recommendation. (Isinkaye, Folajimi and Ojokoh, 2015)
2.2 Collaborative Filtering
Collaborative filtering is one of the most popular methods used for recommendation systems (Ricci, Rokach and Shapira, 2011). The idea behind this technique is that users who had similar taste regarding the items in the recommender system are going to keep having the same taste in future (Cheng et al., 2016).
Collaborative filtering requires two types of data to work: the set of users in the system and the set of items in the system (Felfernig et al., 2013). These two sources of data are then combined in a user-item rating matrix that is used to store the ratings that each user has given to each item, if no rating is given then the matrix has an empty space (Kumar and Thakur, 2018). These ratings can have different range, typically they are in the range or 1 to 5 where 1 is the lowest rating and 5 is the highest rating. The matrix that is generated by the algorithm has measure u x i where u is the total number of users in the system and i is the total number of items in the system (Raghuwanshi and Pateriya, 2018).
|
Star Wars |
Titanic |
Avatar |
Avengers |
|
|
User 1 |
3 |
1 |
5 |
|
|
User 2 |
4 |
2 |
3 |
4 |
|
User 3 |
1 |
1 |
Fig.1 Example of a User-Item Matrix
This user-item matrix is then used to produce predictions for the rating that the current user of the system might give to item he has not seen, these prediction fall on the same scale as the rating. Once all the prediction are computed a list of N items is constructed, this list contains the item the received the highest prediction value and have not been seen by the user yet (Sarwar et al., 2001). This process is shown in figure 2.
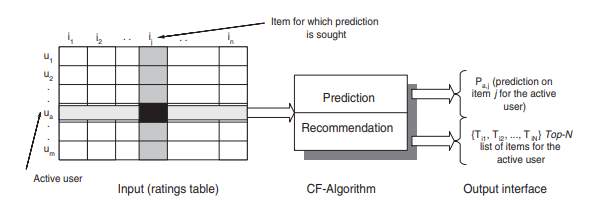
Fig.2 General Process for collaborative filtering
Collaborative filtering can be implemented in many ways, in general collaborative filtering techniques can be grouped in two categories: memory-based and model based techniques. The main difference between these two groups is the way the actual list of recommendations is calculated from the user-item matrix.
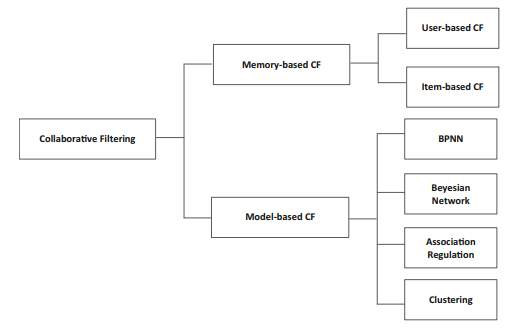
Fig.3 Diagram of collaborative filtering approaches (bo hong).
2.2.1 Memory Based Collaborative Filtering
Memory based approaches involve finding the set of user that are most similar to the active user, this set is called the “Neighbourhood” (Felfernig et al., 2013). These neighbourhoods can be of two kinds: item-based or user-based depending on which relationship the algorithm is going to exploit (Al-bashiri et al., 2018). Generally these relationship are found by calculating the degree of similarity between the active user and the other users and choosing the neighbours that have the highest similarity in the case of user-based approaches or by calculating the similarities between item ratings in the item-based approach (Raghuwanshi and Pateriya, 2018). Once a neighbourhood is found by the system a variety of algorithms is used to calculate the list of recommendations for the user.
The key challenge with memory based techniques lies in the similarity measure chosen to find the neighbourhood, this is due to the importance of finding the correct neighbours in memory based approaches (Al-Bashiri et al., 2018). Some of the most popular similarity metrics are presented below:
2.2.1.1 Euclidean Distance
Euclidian distance is the fundamental measure of similarity upon which many measures are based on (Sondur, Chagadani and Nayak, 2016). It is defined as:
Fig.4 Formula used to calculate the Euclidian Distance between two vectors.
Where x and y are two vectors that represent the ratings that each user has given to the same set of items,
and
represent the rating of each individual item I and d(x,y) is the total “distance” between the two users. (Sondur, Chagadani and Nayak, 2016)
The Euclidean distance is very basic measure of similarity and comes with some serious drawbacks.One of these drawbacks is that if the scale of the data is not the same, then the data with the largest scale will overpower the other, therefore it is only appropriate with normalized data or data with the same scale (Sondur, Chagadani and Nayak, 2016). Another drawback of this measure is that it can result in smaller distance value if two data vectors don’t have much in common in terms of items, a smaller distance value in that case will falsely show a high level of similarity between vectors. (Shirkhorshidi, Aghabozorgi and Wah, 2015)
2.2.1.2 Pearson’s Correlation Coefficient
This metric of similarity is among the most popular measure of similarity of users in memory based collaborative filtering (Al-Bashiri et al., 2018) and was first used for collaborative filtering by (Resnick et al., 1994). It is defined as:
Fig.5 Formula used to calculate Pearson’s correlation coefficient
Where x and y are a pair of users,
is the group of items that both the users have rated,
and
are the average of the ratings that both users have given,
and
are rating that user x and y respectively have given to item i, and pcc(x,y) is the final measure of similarity. (Sondur, Chagadani and Nayak, 2016)
A value for pcc(x,y) that is greater than 0 denotes a positive correlation between two users, on the other hand a value that is less than 0 denotes a negative correlation between users. If the value of pcc(x,y) is equal to 0 there is no correlation between the examined users (Sheugh and Alizadeh, 2015). Even though this is one of the most popular measure of similarity is suffers from a sever limitation, in the case where users have not rated many items in common this technique will lead to high or low similarities resulting in bad recommendations being produced. (Al-Bashiri et al., 2018)
2.2.1.3 Cosine Similarity
The cosine similarity measure is often used for information retrieval tasks, however in recent times it has been explored as a similarity measure for recommendation problems (Sondur, Chagadani and Nayak, 2016).This similarity metric measure the cosine of the angle that is produced by the vector representation of the user’s ratings that are present in the system (Ye, 2011). It is defined as:
Fig.6 Formula used to calculate Cosine Similarity
Where x and y are the vectors representing the ratings produced two users being analysed,
is the set of items that both users have given a rating to,
is an individual item from the set of common items,
and
are the ratings for item I given by the users and CV(x,y) is the final measure of similarity. The range of this measure is [0, 1] where 0 is the lowest possible similarity and 1 is the maximum similarity. (Sheugh and Alizadeh, 2015)
This measure is very effective for use cases where the vectors of the two users are of different sizes since it is independent on vector length (Shirkhorshidi, Aghabozorgi and Wah, 2015). The main drawback of this approach for measuring similarity is that it does take into account difference in the mean and variance of the vectors. (Sondur, Chagadani and Nayak, 2016)
2.2.2 Model Based Collaborative filtering
Model based techniques are a different implementation of Collaborative filtering, and are based open the idea of utilizing machine learning or data mining techniques to find complex pattern in the user-item data (Su, X. and Khoshgoftaar, T. ,2019). This approach is a proposed solution to some of the major drawback of Memory based collaborative filtering, the main one being the large amount of memory needed for very large dataset (Thi Do and Van Nguyen, 2010)
One of the most common machine learning technique used by this type of Collaborative filtering is clustering. This method aims at partitioning data using clustering algorithms, these algorithms will take the user-item data as input and produce “clusters” which are groups of data points that are similar to each other (Thi Do and Van Nguyen, 2010). Clustering is in most cases used to find the “Neighbourhood” of an active user, this is done by first training the model with the data of all the other users and then placing the new user in the model. The cluster in which the new user will end up is his “Neighbourhood”, from there classification or ranking tasks can be carried out. (Su, X. and Khoshgoftaar, T., 2019). Clustering are very effective at solving memory problem when implementing recommending systems, this is due to the smaller size of data that they work with which in most case is only one cluster (Pham et al., 2011). The actual training process which is resource expensive can be done in advance by saving the resulting model. . (Su, X. and Khoshgoftaar, T., 2019)
2.3 Clustering Algorithms
Clustering algorithms are a type of unsupervised learning that aims at grouping data points into distinct classes called clusters without any knowledge about the actual class in which these data points fall into (Osamor et al., 2012). All the data points in the same cluster are similar to each other while being different to the data in other clusters (Abbas, 2008), this process allows for a better analysis by finding complex relationships in the data. In the field of recommender systems clustering techniques are used to speed up the process of finding users that share the same likings and may be of interest to each other (Su, X. and Khoshgoftaar, T., 2019).
These algorithms can be implemented using various methods, the most popular of these methods are presented below:
- Partitioning algorithms that aim at separating the given data into K clusters, where the number of clusters is given in advance (Agrawal et al., 1998). This is an iterative approach that aims at minimizing the total-square error, this is done by moving objects from one class to another until the final iteration is reached or no improvement is made. (Khanali and Vaziri, 2016)
-
Hierarchical clustering that aim at combining or dividing clusters and forming a hierarchy based on the combinations and divisions that have been performed (Abbas, 2008). This type of approach does not have a set number of clusters as opposed to partitioning methods, the clusters are created based on the previous clusters in the system (Osamor et al., 2012). Overall the hierarchical approach is quite strict since any division or combination cannot be undone, this leads to it having a lower computational cost since it does not have to repeat any step (Khanali and Vaziri, 2016) .There exist two different approaches for hierarchical clustering:
- Agglomerative approach where each data point belongs to one cluster by itself. These small clusters are then combined until the data reached the desired state (Rokack and Maimon , 2005). This approach however has a major drawback, due to it having to create a single cluster for each data point it does not scale well. (Khanali and Vaziri, 2016)
- Divisive approach where a giant cluster that incorporates all the data is created. This cluster is the divided into smaller clusters, which are recursively divided until the desired state is reached. (Rokack and Maimon , 2005)
Overall the hierarchical approach is a very strict approach since any combination or deletion cannot be undone, this lead to it having a reduced computational cost.
Bibliography
- Vaidya, N. and Khachane, A. (2017). Recommender systems-the need of the ecommerce ERA. 2017 International Conference on Computing Methodologies and Communication (ICCMC).
- Schwartz, B. (2016). The Paradox of Choice: Why More Is Less: How the Culture of Abundance Robs Us of Satisfaction. New York: Ecco Press, pp.21-52.
- Gomez-Uribe, C. and Hunt, N. (2019). The Netflix Recommender System. [online] Available at: http://delivery.acm.org/10.1145/2850000/2843948/a13-gomez-uribe.pdf?ip=161.23.240.181&id=2843948&acc=OA&key=BF07A2EE685417C5%2E53A024A4F41048F4%2E4D4702B0C3E38B35%2EE5B8A747884E71D5&__acm__=1563781868_fc91c3780335226f4ddd8c034ef75892 [Accessed 13 Jul. 2019].
- Medium. (2019). Netflix Recommendations: Beyond the 5 stars (Part 1). [online] Available at: https://medium.com/netflix-techblog/netflix-recommendations-beyond-the-5-stars-part-1-55838468f429 [Accessed 6 Jul. 2019].
- Sarwar, B., Karypis, G., Konstan, J. and Reidl, J. (2001). Item-based collaborative filtering recommendation algorithms. Proceedings of the tenth international conference on World Wide Web – WWW ’01.
- Senecal, S. and Nantel, J. (2004). The influence of online product recommendations on consumers’ online choices. Journal of Retailing, 80(2), pp.159-169.
- Eirinaki, M., Gao, J., Varlamis, I. and Tserpes, K. (2018). Recommender Systems for Large-Scale Social Networks: A review of challenges and solutions. Future Generation Computer Systems, 78, pp.413-418.
- Ricci, F., Rokach, L. and Shapira, B. (2011). Recommender Systems Handbook. Boston, MA: Springer US, pp.1-48.
- Golbandi, N., Koren, Y. and Lempel, R. (2011). Adaptive bootstrapping of recommender systems using decision trees. Proceedings of the fourth ACM international conference on Web search and data mining – WSDM ’11.
- Khusro, S., Ali, Z. and Ullah, I. (2016). Recommender Systems: Issues, Challenges, and Research Opportunities. Lecture Notes in Electrical Engineering, pp.1179-1189.
- Su, X. and Khoshgoftaar, T. (2009). A Survey of Collaborative Filtering Techniques. Advances in Artificial Intelligence, 2009, pp.1-19.
- Nguyen, T., Hui, P., Harper, F., Terveen, L. and Konstan, J. (2019). Exploring the filter bubble.
- Canny, J. (2002). Collaborative filtering with privacy via factor analysis. Proceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval – SIGIR ’02.
- Kumar, P. and Thakur, R. (2018). Recommendation system techniques and related issues: a survey. International Journal of Information Technology, 10(4), pp.495-501.
- Cheng, W., Yin, G., Dong, Y., Dong, H. and Zhang, W. (2016). Collaborative Filtering Recommendation on Users’ Interest Sequences. PLOS ONE, 11(5), p.e0155739.
- Isinkaye, F., Folajimi, Y. and Ojokoh, B. (2015). Recommendation systems: Principles, methods and evaluation. Egyptian Informatics Journal, 16(3), pp.261-273.
- Felfernig, A., Jeran, M., Ninaus, G., Reinfrank, F., Reiterer, S. and Stettinger, M. (2013). Basic Approaches in Recommendation Systems. Recommendation Systems in Software Engineering, pp.15-37.
- Raghuwanshi, S. and Pateriya, R. (2018). Recommendation Systems: Techniques, Challenges, Application, and Evaluation. Advances in Intelligent Systems and Computing, pp.151-164.
- Al-bashiri, H., Abdulgabber, M., Romli, A. and Kahtan, H. (2018). An improved memory-based collaborative filtering method based on the TOPSIS technique. PLOS ONE, 13(10), p.e0204434.
- Resnick, P., Iacovou, N., Suchak, M., Bergstrom, P. and Riedl, J. (1994). GroupLens. Proceedings of the 1994 ACM conference on Computer supported cooperative work – CSCW ’94.
- Sondur, M.S.D., Chigadani, M.A.P. and Nayak, S., 2016. Similarity measures for recommender systems: a comparative study. Journal for Research, 2(3)
- Sheugh, L. and Alizadeh, S. (2015). A note on pearson correlation coefficient as a metric of similarity in recommender system. 2015 AI & Robotics (IRANOPEN).
- Shirkhorshidi, A., Aghabozorgi, S. and Wah, T. (2015). A Comparison Study on Similarity and Dissimilarity Measures in Clustering Continuous Data. PLOS ONE, 10(12), p.e0144059.
- Ye, J. (2011). Cosine similarity measures for intuitionistic fuzzy sets and their applications. Mathematical and Computer Modelling, 53(1-2), pp.91-97.
- Ming-Phung Thi Do, Dung Van Nguyen. (2010). Model-based approach for Collaborative Filtering.
- Manh Cuong Pham, Matthias Jarke, Ralf Klamma & Yiwei Cao (2011) A Clustering Approach for Collaborative Filtering Recommendation Using Social Network Analysis. JUCS – Journal of Universal Computer Science. [Online] 17 (4).
- Osamor, V., Adebiyi, E., Oyelade, J. and Doumbia, S. (2012). Reducing the Time Requirement of k-Means Algorithm. PLoS ONE, 7(12), p.e49946.
- Abbas, O.A., 2008. Comparisons Between Data Clustering Algorithms. International Arab Journal of Information Technology (IAJIT), 5(3).
- Agrawal, R., Gehrke, J., Gunopulos, D. and Raghavan, P. (1998). Automatic subspace clustering of high dimensional data for data mining applications. ACM SIGMOD Record, 27(2), pp.94-105.
- Khanali, H. and Vaziri, B. (2016). A Survey on Clustering Algorithms for Partitioning Method. International Journal of Computer Applications, 155(4), pp.20-25.
- Rokach, L. and Maimon, O. (2005). Clustering Methods. Data Mining and Knowledge Discovery Handbook, pp.321-352.
- Kanungo, T., Mount, D., Netanyahu, N., Piatko, C., Silverman, R. and Wu, A. (2000). The analysis of a simple k-means clustering algorithm. Proceedings of the sixteenth annual symposium on Computational geometry – SCG ’00.
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


DMCA / Removal Request
If you are the original writer of this essay and no longer wish to have your work published on UKEssays.com then please click the following link to email our support team:
Request essay removal