Overview of Different Web Structures
| ✅ Paper Type: Free Essay | ✅ Subject: Engineering |
| ✅ Wordcount: 3409 words | ✅ Published: 31 Aug 2017 |
Dark Internet, Dark net (File Sharing), Turbo10, Meta-Search Engine
Mansi Iyengar (SCU ID: W1170603)
This project is targeted for the researchers to gain insight into the different web structures. The primary focus being deep net and dark net.
It also throws light on file sharing in dark net along with meta search engines used by them.
This report is based on dark net, metasearch engines and file sharing mechanism. It has been categorized in the form of chapters.
Each chapter gives us the below information
Chapter 1 tells us about the different structures in the web
Chapter 2 provides an overview of dark net and TOR
Chapter 3 describes the file sharing mechanism in dark net and commonly used approaches
Chapter 4 focuses on operation of meta search engine
Chapter 5 talks about Turbo10 search engine for deep net
The linkage of each web page is referred by website’s structure. Consider for a website having high number of web pages. In such scenario, crawlers should have the ease to find the subpages.
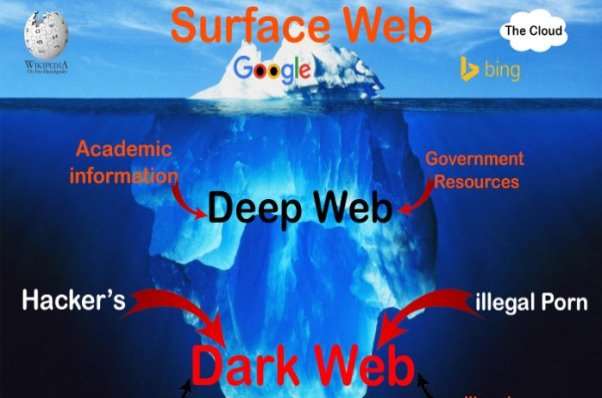
Figure 1 portrays entire web structure that comprises of:
- Surface web
- Deep web
- Dark web
Surface web
The traditional internet we use for everyday life is the world wide web.
Represented by www.
Deep web
Deep web provides the hidden part of the internet. Search engine do not index these. Thus deep web stands apart from the traditional web. Some components of deep web include email, online banking, on demand videos
Dark web
Dark web is different from above traditional web types.
Dark net stands for a network accessed via specific software or configuration using protocol that are not standardized.
For everyday life, we use regular search engines such as google. The exists websites that cannot be looked up on google. For such websites need a particular application in order to access. Such websites are known as dark web.
Dark net comprises of decentralized computers that collaborate in tandem to send information from origin to the target. Some of the popular dark net are Limewire, Gnucleus. Users are members that share information. Hosts are the computers that help share the information.
Dark web is also known as dark net or dark internet.
For ease of understanding we can consider software named as Tor. Tor provides the functionality wherein the user cannot be identified on traditional websites.
TOR
Tor also provides sites that have hidden services. Basically the hidden or anonymous feature is leveraged to masquerade where server is situated. Tor makes it almost impossible to trace the members accessing website.
Tor is not fool proof and comprises of some flaws. These pertain to security configuration. This gap can be used by officials to determine the real server location. The popularity of TOR is extremely high and hence most commonly used. Hence the focus on this example.
Features of dark net
However, dark nets provide additional facilities different from above. These may include collaborative effort of handling non-licensed software and content
Content found on dark net
On two fronts dark net facilitates anonymity – member visiting website and also for website itself. Governments too use dark net. For example, in order to gain data bypassing and censorship, Tor provides that option
Dark net too can be used by politicians. This is serves as a platform to mediate and take decision. Secrets are revealed by whistle blowers on certain sites so that they can avoid being traced. Webpages such as Strongbox help serve such purpose.
This leads to establishment of websites that traditionally are not used. They can be used for anti-social purpose. For example, stolen credit card information, illegal currency, drugs and weapons are found here. Gambling activities too are provided.
Illegal drugs and goods, part of commercial dark market are made popular by silk road and diabolic market. These are attacked by legal teams.
Alternate hacking services are sold. These are at group level or individualistic level. This has led to cyber-crimes and counter cyber investigation. Government has started looking into these using tools procured from Procedia Computer Science journal. Denial of service attacks too have been made through Dark Web. [4]
File Sharing
File sharing involves the method of dividing or enabling digital media access such as audio files, video files, programs or eBooks.
There are multiple ways to attain file sharing. Generally used approaches of storage, transmission include web url hyperlinked docs., p2p networks and centralized servers. [3]

The above figure shows us how figure shows how file sharing can be achieved between access controlled digital systems like private, public and invited.
P2P file sharing process
Computers or nodes are connected with each other as part of P2P network. The members have the ability to share or download information immediately via the web.

Above figure shows peer to peer network. Based on the model of self-server and client model, P2P is set up in general.
for example, when the member connects to the P2P client and after initiating file download, he gets connected with other members downloading the information. In other words, others peers serve as file server. The initial member also acts as file server when another peer starts to download the file. Eventually this leads to augmenting of download speed. Some commonly used torrents for P2P are bittorrent and μTorrent. Other popular P2P networks being BearShare and LimeWire. [2]
OnionShare
Consider App called OnionShare that is available for multiple Operating Systems. This is a P2P program. Entire information from TOR anonymity network is sent through this file sharing program.
consider regular file sharing system needs faith. Law regulators can tap into these.
Tor helps bypass third party, there is direct sharing of file from one person to another via anonymous network
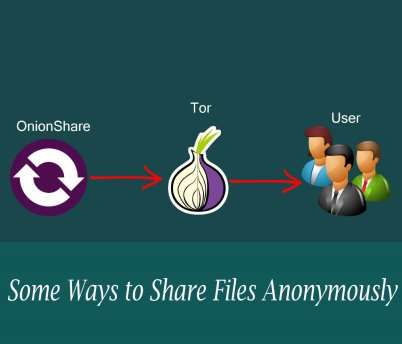
The above figure describes OnionShare process. After Tor instance is running, OnionShare will run. The beginning part is by starting a local web server that is viewable as tor hidden service, generating web link that cannot be guessed out. This web link is used to download the file.
The web link is then provided to the recipient person via secure method
the webserver is cancelled The moment the receipt downloads the file,
Now the file becomes inaccessible to anyone. These is scope to expand this further by having a continuous running server in order to share with multiple recipients [5]
BitTorrent File Sharing Process
Background
BitTorrent file sharing protocol for dark net. BitTorrent is a peer-to-peer file sharing protocol and the most popular one according to a report by (2008). In the same report one can read that BitTorrent takes up a substantial amount of all the internet traffic in the world, between 27 and 55 percent depending on geographical location. This makes BitTorrent not only the most used protocol for file sharing, but of all application layer protocols.
As per Schulse and Mochalski , Bit Torrent is popular file sharing protocol. This is also used by Darknet.
BitTorrent breaks data into parallel smaller chunks instead of single chunk, enhancing reliability and reducing vulnerability
Approaches for bit torrent file sharing
Provided below are two approaches for bit torrent file sharing:
Torrent file approach
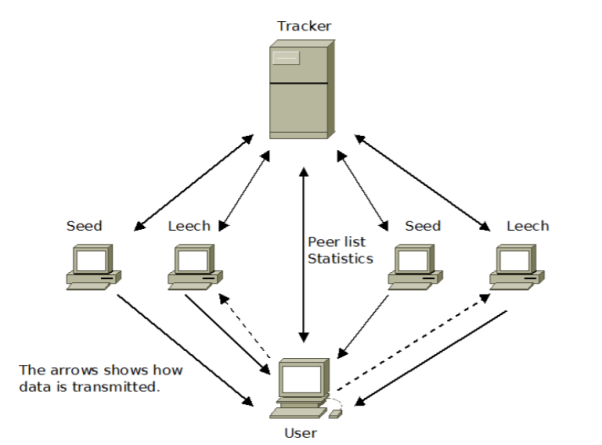
TFigure 5 Torrent file sharing approach
A torrent file is setup that has tracker, file contents. This file is smaller than original file. Seed is the uploader and leech is the downloader.
Above figure describes the torrent file sharing approach. User first downloads the torrent. From torrent the set of peers is found. From the network, file pieces are exchanged. Files are treated instead of atomic blocks but as smaller chunks.
Advantage is that the bandwidth is spread among peer as against just the seeds.
The tracker for a torrent provides peers a peer list. In this manner, bit torrent communication takes place, which is the same process involved for seeders and leaches
DTH approach
There is a second approach that bypasses the tracker. This provides greater anonymity. This approach is performed without generating torrent file.
For this purpose, bit torrent protocol ends up implementing DHT i.e. distributed hash table.
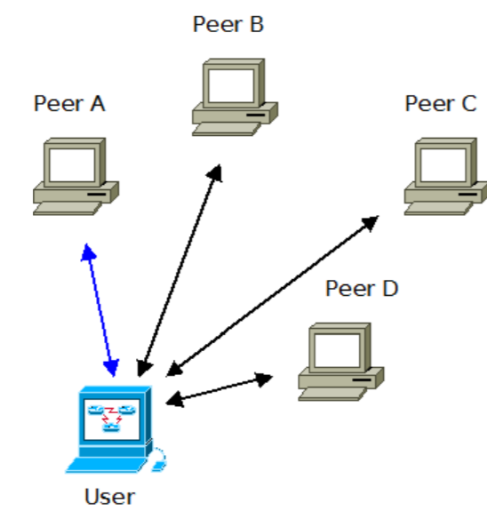
Figure 6 DTH file sharing approach
The above figure describes DTH file sharing approach. DHT provides a set of key, value saved in it. The working is similar to how has table works. Nodes have ability to detect noes based on the key. There is unique identification for each node. For this the communication utilized is User Datagram Protocol (UDP).
The benefit is that there no centralized trackers. However, the track list is provided by peers that send peer list. Traditional torrent file has web link to a tracker. This step is by passed in second approach, wherein DHT web link is used. DHT network is entered into by the peer using the URL. From the entry node, it can search across other networks for files and peer connection for file sharing. [6]
The results of other databases are combined in meta search engine. It takes up the concatenation of various results from various search engines and links then to various resources. [1]
Virtual databases are generated from the mirrors of the physical database results of other search engines. These virtual databases are generated from the meta search engines. The searches are concentrated over certain criteria. [2]
Background
Searching the web with multiple search engines was the issue tackled by researchers. One of the outputs was meta search engine. Search Savvy was the first engine discovered and used by Daniel Dreilinger from Colorado State University. This engine looks over the results from 20 different directories and search engines at once. Meta search engine crawler discovered by Eric Selberg at Washington University. It used its own search engine syntax and searched over 6 search engines.
Dogpile formed at University of Pittsburgh and Pennsylvania State University measured ranking and overlap of various search engines. This proved to have one of the best results. [3]
Advantages
More information and search coverage can be achieved by using meta search engines. This helps the user to get faster and accurate results. The query of the user results is generated in unique ways by using the indexes which are aggregated by search engines. The input effort for a meta search engine and normal search engine are the same but the results retrieved are more. They also reduce the effort of users to type on various search engines to find file and resources.
Disadvantages
Translation of the query format or understanding the query forms can be an issue in the meta search engine. All the results sets of a query are not given to a user as the links generated from a meta search engine are limited. The links generated are limited. Promoted websites are given higher priority over other websites.
It is probable that the user will get multiple results from the search engine. It may not be stream lined. This is especially an issue due to more coverage over the queried topic. The users find it difficult to use meta search. They might not be able to get any precise information.
Operation


The above figure describes the meta search operation. The search engine receives a query from the user.
The key parts are as below:
Broker:Â The query needs a pre-processing as each search engine has a specific format of the data being fed in. As they depend on different operators and they do not share the same syntax. The output is a series of ordered set documents.
Rank: the documents are raked post identifying the result pages and also in the order of the most relevant links. [4]
The input query is passed to the search engines database. It creates a virtual database. This helps to combine data from various sources. Duplicates can be generated as various search-engines have different methods of indexing the data. This output data is then processed by the meta-search engine. The revised list is produced for the user. They would respond in the following ways.
1)Â Access to the meta-search engine reference is provided which also includes the private access to the database system The changes made on the database system would be captured.
2) In a non-cooperative way, the access to the interface may or may not be provided.
3) Meta search engine is denied access to the search engine.
 Architecture of ranking
Architecture of ranking

Above figure describes the architecture of the meta search engine. It consists of the user’s query being sent to the meta search engine. It contacts the other search engines its connected to. They process the results and generate resources. These results are then preprocessed and then given back to the meta search engine as a response. This collective response is given to the user.
Fusion
Fusion is a process for data filtering. It helps to build up efficient results.
Collection Fusion
Unrelated data is indexed via search engines it is dealt by the Collection Fusion process which is also a distributed retrieval process. Ranking on the data is based on how probable is the data to give the required information to the user. It picks up the best resources and ranks it. The resources which are selected are combined in a list and given to the user.
Data Fusion
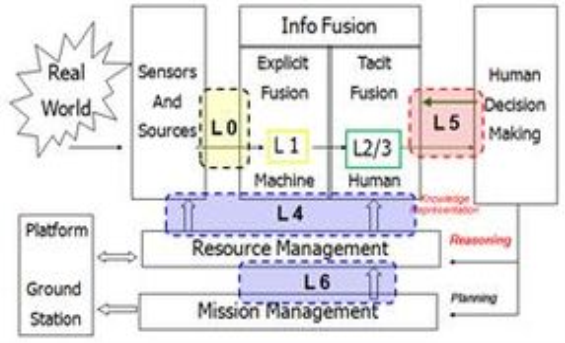
Figure 9: Data Fusion Architecture
Above figure give the architectural reference of the Data Fusion.
- L0: The user information which the sensors and the sources process is given to the fusion algorithm
- L1: The machine process of converting L0 output and it feeds it to the L1 process
- L2 – L3: The human process of manually marking the retrieved data as relevant or not
- L4: Resource management layer adds to the sources and the L2/L3 layer providing th necessary feedback
- L6: The mission management helps to add context to the user query. This is added to the resource management layer
- L5: Once all the processing through the layers is complete the data is given back to the user.
This is fusion mechanism which relies on the common data sets which are retrieved by search engines. The initial ranks are combined into a list. The analysis of the actual ranks of the documents retrieved is calculated. The links of the documents with the highest relevancy score is selected. ComboSum is one of the techniques used to normalize the scores. The scores produced are incomparable as different search engines run on different algorithms.
Examples of Meta-Search Engines
DeepPeep
Above figure is a snippet for DeepPeet. Public web pages are indexes and expanded by search engine. It does so by search through various public databases. Traditional search engines cannot index by DeepPeep. It also looks to find urls into deep web.
IncyWincy
Above image is Incywincy snippet. It uses many search engines, combines and filters the results. It crawlers more than 200 million pages. It uses its unique algorithm for relevance tests.
CompletePlanet
Above figure is snippet of Complete Planet. It indexes and crawlers many search engines and special databases which are not public. It is one of the  main search engines of the deep web.
Other Deep Web search engines include Intute, Infomine, Scirus, Turbo 10.

The above figure is the Turbo 10 is a meta search engine snippet. It helps to engineer a universal reference for Deep Net. It refers to topic specific search engines. Google and Yahoo like crawler-based search engines do not use these files. Turbo 10 also lets you add more engines to the collection on which your search query is executed. [7]
Pros
The positive thing about turbo10 is that it has the ability to connect and maintain connection to online databases in bulk.
This provides connecting to thousand engines in a fully automated capability which is scalable to further connect to another thousand.
Turbo10 also finds content on deep net. Deep net encompasses multiple databases covering wide range of topics such as business, colleges, government teams. These are not accessible to traditional web engines and google. Traditional search engines are helpful for indexing static pages.
Thus a rich experience is provided as we can tap into multiple databases across such a large range of domains, empowering the user.
Turbo provides the option of having ten search engines to search from.
Unlike other search engine like AskJeeves, that faces drawback of segregating information into different boxes, turbo streamlines the process by proving the result in weighted listing. This makes Turbo10 the ultimate search engine of search engine.
Consider the fact that say four search engines are selected, turbo10 does the work of selecting additional six search engines as it deems as best fit.
The result set would be based on either relevance or speed. The decision is independent of the search independent of search engine selected.
The above reduction of search result occurs by usage of clusters in box on left-hand side. The benefit of having clusters a few time, desired result set is obtained quicker as against advanced searches or logical expression
Turbo10 provides a new search paradigm. For a given page, there are ten result lists on a page. These have arrows. Thought this may also be unpopular, this generates hundred results for a given search.
The average case being thirty to forty result set being provided as three or four pages are returned. . Google gives lots of options. Unlike Google, Turbo10 simply limits the search results and provides limited result set
The main idea is that with Turbo 10, ability to choose search enigne is provided. Whereas say for a particular item through google, we need to keep searching and may find the same at pat a latter page say page forty
How is the ability provided to select ten search engines?
The task is completed via the web. A collection name is assigned to the ten search engines, mapped to your email.
Capability
Turbo10 has a vision to emerge as a leader for search engine
Plan to use amazon based recommendation algorithms for personalized searching. This would include personalized profile search, providing bookmarking feature an ecosystem to be setup wherein the user’s profile would interact with other users. Additional browsing options would be generated for users. Revenue model would tap into sponsored web links. These would be flagged licensing of the product to corporates.
Cons
Tturbo10 faces the drawback of being highly cluttered. Google has lots of white spaces. The search results are not cramped up. Turbo10 is not visually appealing. It has purple colour screen that may not be appealing to all
Many times the returned result set is cluttered. Sometimes the result set gets jumbled affecting result set. Additionally, there is no consideration for punctuation marks or logical expressions. Does not have ability to cache information. Due to high demand and expectation, knocked offline.
Intense competition with google.
The project is based on dark net ecosystem comprising of file sharing mechanisms and meta search engine. Dark net has continuously using evolving technology such as TOR, OnionShare. These help enable provide benefits of being anonymous protecting their identity. Similarly, the website to gets to preserve their anonymity. Dark net serves as a platform of communication to mediate, take decision and share information. These are used by different agencies including government and non-traditional activities such as whistleblowing.
Products that are not listed in traditional websites too are available on such platforms.
File Sharing approaches save bandwidth by helping sharing information efficiently. Easier to back up information. Fault tolerance is enhanced through decentralized approach part of peer to peer networking. Comparatively there is ease of maintenance over traditional files sharing system.
Meta search engines help to get streamlined results from various search engines which helps to improve relevancy of searches.
The benefits of dark net also include cross border payments, ensure complete privacy of sender and receiver. There is application in cryptocurrency, digital trading, eliminating middlemen. Set up of hassle free payments independent of weekend or holidays. Benefit of decentralization is control over your content that you want to share. Other advantages include establish net neutrality which means that internet can be used for all and not monopolized.
Hence there is a large scope for expansion in dark net space and technology is playing a pivotal role in enhancing its adoption.
[1] https://www.linkedin.com/pulse/internet-deep-web-dark-net-firas-saras
[2] https://sysinfotools.com/blog/peer-to-peer-file-sharing/
[3] http://www.spiroprojects.com/blog/cat-view-more.php?blogname=What-is-file-sharing-system?&id=262
[4] https://www.howtogeek.com/275875/what-is-the-dark-web/
[5] https://darkwebnews.com/anonymity/some-ways-to-share-files-anonymously/
[6] Johan Andersson & Gabriel Ledung, Darknet file sharing application of a private peer-to-peer distributed file system concept
[7] http://techdiction.blogspot.com/2007/01/turbo-10-search-deep-net.html
URLÂ Â Â Uniform Resource Locator
TORThe Onion Router
UDPUser Datagram Protocol
DTHdistributed hash table
WWWWorldwide web
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


DMCA / Removal Request
If you are the original writer of this essay and no longer wish to have your work published on UKEssays.com then please click the following link to email our support team:
Request essay removal