Hybrid Electric Energy Integrated Cluster
| ✅ Paper Type: Free Essay | ✅ Subject: Engineering |
| ✅ Wordcount: 2382 words | ✅ Published: 31 Aug 2017 |
Project Acronym: HELENIC-REF
Project Title: Hybrid Electric Energy Integrated Cluster concerning Renewable Fuels
This project has been funded by the European Union’s Horizon 2020 research and innovation programme. The information in this document reflects only the author’s views, not the opinion of the European Union. Neither the REA nor the European Commission are responsible for any use that may be made of the information contained therein.
The deliverable describes the data that will be obtained for HELENIC-REF, the procedure for obtaining, managing, storing these data. An explanation of naming, version controlling and preserving the data will be given, along with the procedure of sharing the data per the participation of the project in Open Research Data Pilot.
HELENIC-REF (Hybrid Electric Energy Integrated Cluster concerning Renewable Fuels) project refers to the establishment of a new sustainable methodology of production of energy or fuels. HELENIC-REF is participating on the Open Research Data Pilots which a pilot action in H2020 on open access to research data.
The foresight for the Data Management Plan is dictated by the three main objectives of the HELENI C-REF project:
- The reduction method based on the Lorenz electron forces
- The production of hydrogen using magnetite catalyst
- The production of hydrocarbons based on the production of hydrogen and the Lorenz electrons
The following plan describes the data that will generated in connection of these objectives in the research project. It speaks about the methods of collection, the way they will be shared and how they will be stored, backup and preserved.
The data that will be produced in the project can be divided in three wide categories, computer software, research data and metadata, and manuscripts and dissemination material.
3.1 Computer Software
HELENIC-REF will produce software for measurement and instrumentation and modelling. The source code will be stored and shared among the partners in ZIP archives, which in the most common format for this purpose. Source code will have standard programming language format either in .m or .vi depending for the program in which was created.
3.2 Research data and metadata
This category refers to the data that will be collected from the different experiments that will be carried in the project from each partner. The data will be stored in standard format of .txt, .csv to be accessible easily from any type of software for further processing of evaluation.
The main categories of the research data that will be produced in the project cover the following areas.
- Information on the catalyst
- Information on the developed experimental apparatus for the reduction process
- Information on the developed experimental apparatus for the hydrogen production
- Information on the developed reactor for the hydrocarbon production
3.2.1 Information on the catalyst.
The data produced on the catalyst will refer mainly on the its structural characterization and will be produced with different methods described in Section 4.
3.2.2 Information on the developed experimental apparatus for the reduction process
The reduction process will be based on Lorenz electron reactor operation. The data will be produced and collected from the measurement of this activity with the used of different measurement method such as chromatography, structural characterization etc. (More details in Section 4)
3.2.3 Information on the developed experimental apparatus for the hydrogen production
This data will be produced by monitoring different parameters of the designed experimental apparatus, such as temperature, pressure, electro-magnetic conditions etc.
3.2.4 Information on the developed experimental apparatus for the hydrogen production
The Hydrocarbon production will be made by either use the produced hydrogen or the Lorenz electrons. This procedure has different approaches and each will produce its own data sets
3.2.5 Information on the developed reactor for the hydrocarbon production
These data will be produced by the process or the burning the accumulated hydrogen and oxygen.
3.3 Manuscripts
Manuscripts refers to the all the documents produced during the project, deliverables, publications, internal documents. Microsoft WORD (.doc) will be used for the draft versions and both WORD and PDF formats will be used for the final ones.
3.4 Dissemination material
HELENIC-REF will produce different types of dissemination materials, flyers, public presentations, videos, presenting the idea and the achievements of the project. For the flyer, the final format will be an image on .JPEG or bitmap .BMP. The presentations will be either in Microsoft PowerPoint format or PDF. All the dissemination material will be shared in public only in PDF format or hardcopy. For the video widely used format will be used as AVI or MOV.
4.1 Creation and collection of the data
In this section the methodology for the collection and the creation of each of the data category will be presented.
4.1.1 Computer Software
The software produced in HELENIC-REF will be mainly to gather and process the data from the different types of sensors that the partners will use during the experimental procedure. National Instruments Suite will be used from all the partners for the data acquisition of some of the sensors and the commercial software of the devices for the gas analysis, flow meter etc. In addition, software code will be produced during the modeling procedure with the use of MATLAB. Its time a new version of code will be produced, will be released among the partners to update their versions if needed.
4.1.2 Research data and metadata
Research data will be produced during the experimental procedure of the project and the further processing of these data. As previous said these data can be divided in the four main categories. The methods for the collection of the data in each category involve scientific equipment and sensors. The data produced on the catalyst will be made through measurements on:
- Electron microscopy
- X-ray diffraction
- FTIR & Raman spectroscopy
In addition, the resistivity of the catalyst will be monitored and data will be produced from its structural modelling.
The methods to produce the datasets on the reduction process will be based on:
- On-line oxygen flow measurement using sensors and/or chromatography
- On-line resistivity monitoring
- On-line parametric control (Air flow, temperature, current, magnetic field)
- Periodic structural characterization
- Modeling of the reduction process
The datasets for the Hydrogen and Hydrocarbon production, they will be obtained through measurements by both the operating conditions of the experiment:
- Temperature
- Pressure
- Water flow rate for steam generation
- Inlet inert flow rate (N2)
- Output gaseous flow rate
- Output gaseous flow rate (hydrogen and oxygen)
And the electro-magnetic conditions:
- Current flow along the catalyst
- Magnetic field vertical to the current flow on the catalyst
- Resistivity on the catalyst
4.1.3 Manuscripts and dissemination material
All the documentation of the project, deliverables, internal reports, material for dissemination will be produced by the Microsoft Office Suite
4.2 Naming, versioning and handling of the files.
The structure of the archiving of the data will follow the WP and task organization. The parent folder will be named under the Work Package number and the children folders with the name of the task. The structure will be the same for the different type of data, research software, dissemination material. The structure of the folders can be seen in Figure 1.
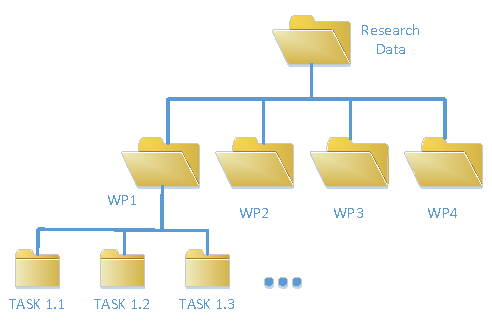
Figure 1: Structure of folder for Research Data archiving
Research data from measurements will be accompanied by a log file naming who created the data or contributed, date and under what conditions they can be accessed. In addition, these datasets will be followed by detail documentation about the used methodology, the analytical and procedural information, if any assumption was made and the equipment used to obtain these (chromatograph, gas analyzer etc.).
The naming of the files will be made accordingly to their content for easier identification. Especially for the data from measurement in the name of the file the generation date will be contained and a number indicating the repetition of the experiment that day “filename_day_month_year_repetition” for example if the date was 3 of March 2016 and it was the 10th time that the experiment for repeated then the name will be “filename_03_03_2016_R10”. For the rest of the files a version system will be used indicating the version of the file after the name “filename_Vx”. For the software where is needed for the versioning and revision tool like GIT (https://git-scm.com ) will be used.
For manuscripts, the writer/owner of the document will be controlling the version of in the name of the file but also in the Document History table inside the document. Each partner that will contribute in the document will use track changes and change the name of the original by adding he/she initials to the filename.
4.3 Quality procedures
The Consortium has specified quality procedures for the deliverables and internal documents and the dissemination material. Each document generated by any partner must be circulated at least 10 days before its deadline for submission. Also, the Coordinator will check the document against any issues of plagiarism or not proper referencing. The content of any publication or dissemination material must be approved by the Consortium before submission and it is checked to include the acknowledgment to the EU funding.
The equipment that is used for the measurements during the experiments is certified and calibrate to assure the accuracy of the data measured. But the correct measurements are depending on the methodology of the experiments and the ability to repeat the experiment and to obtain the same results. For this reason, the data obtained from the experiments will be compared with previous measurements to identify the similarity to the results. Also, the results of the experiments will be circulated to the partners to assess the quality of the findings. In addition, the methodology used by each partner will be discussed in weekly based skype meetings with partners for possible corrections or omissions.
5.1 Data storage and back up during the project
Each partner will be responsible to store securely in their server equipment the data produced using the archiving system described above. These local servers are secure and the drives are periodically backed up. Through the development process, data may be shared on computers belonging to the partner staff. These computers are safeguarded through up to date virus and malware protection software. For sharing the data between the partners a designated secure area exists in the website. Access to this area can be done only with a username and password that has been granted to each partner from the administrator of the site.
Maintenance of the datasets stored in partner’s server will be done in accordance to each of the partner’s policy. In addition, a back-up of the datasets will be held by the coordinator in a secure area in his server.
5.2 Data sharing and confidentiality
Due to the novelty of the proposed method the consortium is willing to file for patents as soon as the outcome of the generated data will allow to do so. In addition the amount of the data that will be produced as can been seen from the description above will allow the partners to make several publications in high impact journals. The publications arise from the project will be open access in order to be exploit by not only the academic community by from the industry as this is the main goal of the consortium.
Also, because as mentioned it is highly possible to file for patents, the consortium has agreed to open the data for sharing only after the patents have been submitted. But, the data concerning any possible publications will be available to verify the findings and clarify the procedure that is described in each publication.
The Consortium have decided that the datasets from the experimental measurements will be preserved and used by the partners in future research activities. Similarly, to let researchers and wider public to know more about HELENIC-REF data from public reports, open access journals and conferences will be preserved along with the necessary data for validating the published results and for researchers to compare their findings.
All dissemination material will be preserved and shared as soon as possible to let the public about know about the project. The Consortium has decided to preserve the data for 5 years after the completion of the project.
All data to preserved will be kept in the partners serves and will be used by them before and after the completion of the project. The maintenance of the data will by each partner’s responsibility. The preservation of the public data is described in Section 5.3.
5.3 Data sharing
The Consortium, regarding its participation on the Open Research Data Pilot, is on favor to have open access publications. For this reason, to share the dataset from this publications Consortium is considering to use ZENODO ( https://zenodo.org ) as the data repository for the project outcomes. In this repository, all the research data that are needed to validate the open access publications will be kept, free of charge to any user.
HELENIC-REF datasets are to be shared for research and training purposes that is why they will be shared under the Creative Commons Non-Commercial Share-alike license 4.0 (https://creativecommons.org/licenses/by-nc-sa/4.0 ). This license enables anyone freely
- Share, copy and redistribute the material in any medium or format
- Adapt, remix, transform, and build upon the material
With respect to the following terms
- Attribution, one must give appropriate credit, provide a link to the license, and indicate if changes were made
- Non-commercial use
- Share alike (Share the data under the same license)
All the dissemination data will be made available through the website and social media.
In case a partner is required to share any of the confidential information, for example with manufacturers, suppliers or specialist companies, it is required to sign a non-disclosure agreement between them and after the Consortium Members are informed and have agreed.
5.4 Copyright and Intellectual Property Rights (IPR) issues.
Datasets are owned by the partner that generates them. Where several partners have jointly carried out work generating the datasets, they will have joint ownership of such these data. In addition, these partners can agree on a joint ownership agreement regarding the allocation and terms of exercising that joint ownership. The joint ownership results can be used by the partners for non-commercial research activities without requiring the prior consent of the others Joint Owners. The ownership of these dataset can be transferred per article 30 of the Grant Agreement.
As mentioned above the public scientific datasets will be shared under the Creative Common license to protect the intellectual property of the owners against any commercial use of the shared dataset.
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


DMCA / Removal Request
If you are the original writer of this essay and no longer wish to have your work published on UKEssays.com then please click the following link to email our support team:
Request essay removal