Review Paper on Fault Tolerance in Cloud Computing
| ✅ Paper Type: Free Essay | ✅ Subject: Computer Science |
| ✅ Wordcount: 2652 words | ✅ Published: 03 Apr 2018 |
A REVIEW PAPER ON FAULT TOLERANCE IN CLOUD COMPUTING
- Deepali Mittal
- Ms. Neha Agarwal
Abstract— Cloud computing demand is increasing due to which it is important to provide correct services in the presence of faults also. The Resources in cloud computing can be dynamically scaled that too in a cost effective manner. Fault Tolerance is the process of finding faults and failures in a system. If a fault occurs or there is a hardware failure or software failure then also the system should work properly. Failures should be managed in a effective way for reliable Cloud Computing. It will also ensure availaibility and robustness .This paper aims to provide a better understanding of fault tolerance techniques which are used for managing faults in cloud. It also deals with some existing Fault tolerance model.
Index Terms— Cloud Computing, Fault Tolerance, Dependability.
I. Introduction
Cloud computing is new method which can be used for representing computing model where IT services are delivered via internet technologies . These have attracted millions of users. Cloud storage not only provide us the massive computing infrastructure but also the economics of scale. Such a trend, requires assurance of the quality of data storage services which involves two concerns from both cloud users and cloud service providers: data integrity and storage efficiency.
It is much more simple than internet. It is a service that allows user to access applications that actually exist at location other than user’s own computer or other devices on network. There are many benefits of this technology. For example any other company hosts user application.
Cloud computing is nothing new as it uses approaches, concepts, and techniques that have already been developed. But on the other side everything is new as cloud computing changes how we invent, develop, deploy, scale, update, maintain, and pay for applications and the infrastructure on which they run. Cloud Computing is an efficient way of computing as it centralizes the storage, memory and processing.
Fault tolerance has the property to assess the capability of the system to react graceciouslly to a hardware and software failure which is not expected. In assortment to attain robustness or raptness in cloud computing, failure should be determined and handled carefully.This paper will give basic knowledge about Fault tolerance Approaches.The Methods used for fault management in cloud We also study some existing fault management models which tolerates fault in cloud environment. Then figure out the best model of fault tolerance.
Fault tolerance deals with all different approaches that provides robustness ,availaibility and dependability .The major use of enforcing fault tolerance in cloud computing include recovery from different hardware and software failures, reduced cost and also improves performance . Robustness is the property of providing of with an accurate service in an unwanted situation that can arise because of an unexpected system state. Dependability is something that need to be achieved.It is one of the very important aspects for cloud provider.It includes dependability as well as availability.It is related to some of the Quality of service issues delivered by the system.
Fault tolerance intent to accomplish robustness and dependability in the cloud environment.Fault tolerance techniques can be classified into types depending on the policies of fault tolerance viz,
Proactive Fault Tolerance :
Proactive fault tolerance simple means early prediction of the problem before it actually arises.
Reactive fault tolerance:
This policy handles the failure. The effect of failure is reduced when the failure actually occurs. This could be further divided into two sub-procedures :
1. Error Processing
2. Flaw Treatment
The first process eliminates error from the system. Fault treatment tries to prevent faults from getting reactivated .
Fault tolerance is accomplished by error processing. Error Processing has two main phases. The first phase is “effective error processing” which means bringing the effective error back to a latent state and if possible it is done before occurrence of a failure.The Second Phase is “latent error processing” which aims to ensure that the error is not reactivated.
II. Existing Fault Tolerance Approaches In Cloud
The different techniques used for fault tolerance in cloud are :
Check pointing: It is a good fault tolerance approach .It is used for applications which have a long running time. In check pointing technique , check pointing is done after each change in system state. It is useful when a task is not able to complete. It fails in the middle due to some error. Then that task is made to begin from the most recent check pointed state instead of restarting it from the beginning.
Task Migration : There may be a case when a task in not able to complete on the assigned specific virtual machine . When this type of task failure occurs then that task could be moved other machine. This can be performed by using HA-Proxy.
Replication: Replication simply means copying. The replica of tasks is executed on distinct resources if the original instance af task fails.It is done to get the actual required result. Replication can be implemented by using various tools. Some of the tools are Hadoop , HA Proxy or Amazon EC2.
Self- Healing : A big task can divided into parts .This division is done for better performance. It results in creation of variant application instance.The instances run on distinct virtual machines.In this way automated failure management is done for instances.
Safety bag checks: This strategy is quite simple. It blocks the command which does not met the requirements for safe execution or proper working of machine.
S-Guard : It is a stream Processing techniques.It makes available more resources. It use the mechanism of Rollback recovery. Check Pointing is done Asynchronously. It is used for distributed environment. S-Guard is performed using Hadoop or Amazon EC2.
Retry : A task is made to execute repeatedly .This approach try to re execute the failed job on same machine .
Task Resubmission : A task failure can make the complete job also fail. So when a failed task is identified ,it should be submitted to same or either distinct resource for reexecution.
Time checker : Time checker is a supervised technique. A watch dog is used. It consider Critical time function.
Rescue workflow : This strategy is used for Fault tolerance in workflow execution.
Reconfiguration: The configuration of the system is changed in this technique.The faulty component is removed.
Resource Co-allocation: It increases the availability of resources. It takes care of multiple resources. Resource allocation is done to complete the execution of task.
III. Fault Tolerance Models
Various Fault Tolerance Models are designed using these techniques. These techniques are combined with one another and then applied or simply used individually. Some of Existent fault tolerance models are :
“AFTRC – A Fault Tolerance Model for Real Time Cloud Computing” is designed by keeping the fact in mind that real time systems have good computation. These systems are also scalable and make use of virtualization techniques which helps in excuting real time applications more effectively.This model is designed by considering the dependability issue. The model make use of proactive fault strategy and predicts the faulty nodes.
“LLFT – Low Latency Fault Tolerance ” act as a middleware for tolerating faults. It is useful for distributed application which are running in cloud. In this model fault tolerance is provided like a service by cloud providers. Applications are replicated by middleware. In this way replication helps in handling of faults for different applications.
“FTWS – Fault Tolerant WorkFlow Scheduling” is a model based on replication approach. It also makes use of resubmission technique. A metric is maintained for checking the priority of tasks and they are submitted accordingly. The principle of workflow is used in this model. Workflow means a series of task executed orderly. Data dependency decides the order. Fault management is done while the workflow is scheduled.
“FTM” is one of the most flexible model. It delivers fault tolerance as on demand service. The user has a advantage that without having known the working of model ,they can specify the required fault tolerance. It is mainly designed for dependability issues. It consists of various components. Each component has its own functionality.
”Candy” is component base availability modeling frame work. It is mainly designed for availaibility issues. System modelling language is used to construct a model from specifications. This is done semi automatically.
“Vega-warden” is a uniform user management system. It creates global work space for variant applications and distinct infrastructure.This model is constructed for virtual cluster base cloud computing environment to overcome the 2 problems: usability and security which arise from sharing of infrastructure.
“FT-Cloud” has a mechanism of automatic detection of faults.It makes use of frequency for finding out the component.
“Magi-Cube” is a kind of architecture for computing in cloud environment.It is designed for dependability,expenditure and performance issues.All three issues are related to storage.This architecture provides highly reliable and less redundant storage. This storage system is done for metadata handling.It also handles file read and write.
IV. Fault Tolerant Model for Dependable Cloud Computing
Fault Tolerant Model for dependable cloud computing is a model designed for dealing with failures in cloud . As we all know Cloud Computing Environment is made up of virtual machines or you can say nodes. The applications run on these nodes. Using this model faulty nodes are detected and replaced by correctly performing nodes. This is done for real applications. Now on what criteria the model can decide a node to be faulty ? There can be various parameters for detecting faulty node but this model makes use of dependability or dependability measurement. The criteria could be changed according to user’s requirement.
A. Working of Model
The model is designed for X virtual machines. X distinct algorithms run on the X nodes. Input buffer feeds the data to nodes. The input data is then moved onwards to all the nodes simultaneously. When the node gets the input it starts its operation. It performs some functions as designed or stated by the algorithm . In other words , the algorithm runs on nodes and gives a result .The Funtioning of every module is different.
Accepter Module
This module tests the nodes for correct result. It verifies the result of algorithms. If the result is faultless or as required then the result is forwarded further for evaluation of dependability.The appropriate result is sent to timer module. The inappropriate result is not forwarded instead signal is sent.
Timer Module
This module has a timer set for every node .It checks the time of result.If the result is generated before the time set or within that assigned time the only it forwards the result.
Dependability Assessor
This module is responsible for checking of dependability of nodes. At the starting of system the dependability for each node is set to it maximum that is cent percent. When computations are performed the dependability of nodes dynamically changes.The dependability is decided on the basis of time and correctness of result. Dependability increases if the result is accurate and on time. The highest and lowest limit of dependability is set in the beginning. The node with dependability value less than the lowest dependability is replaced. It also sends a message to resource manager. The result of dependability assesers forwards the results to descision maker module.
Decision Maker
It gets the result from dependability assessors. A selection of node is done from all perfect nodes. The node which has the maximum dependability is selected. It makes the comparison between the dependability level of nodes and system dependability. System dependability is important to be attained by a node. In case all the node fails to achieve the system dependability then a failure notification is issued. A failure notification means that all the nodes have failed for this computation cycle. Now backward recovery is done using check points .Decision maker also asks the resource manager to replace the node with lowest dependability with the new one.
Check Pointing
Check Pointing saves the state of system. It is done at regular small intervals. It is helpful in a scenario when a system fails completely. The strategy helps in automatic recovery form the check pointer state. This automatic recovery is done only when all the nodes fails. The system continues to work properly with rest of the nodes.
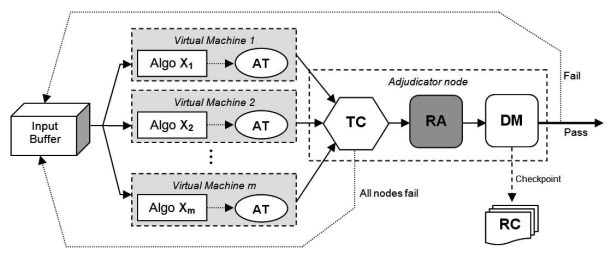
Fig .1.Fault Tolerant Model For Dependable Cloud Computing
B. Mechanism Of the Model
Dependability Assessment Algorithm
Begin
Initially dependability:=1, n :=1
Input from configuration RF, maxDependability, minDependability
Input nodestatus
if nodeStatus =Pass then
dependability := dependability + (dependability * RF)
if n > 1 then := n-1;
else
if processing node Status = Fail then dependability: = dependability – (dependability * RF * n) n: = n+1;
if dependability >= max Dependability then Dependability: = max Dependability
if dependability < min Dependability then Processing node Status: =dead
Call Add new node ( );
End
Decision Mechanism Algorithm
Begin
Initially dependability:=1, n :=1
Input from RA nodeDependability, numCandNodes
Input from configuration SRL
bestDependability := find_dependability of node with highest dependability
if bestDependability >= SRL status := success
else perform_backward_recovery
call_proc: remove_node_minDependability
call_proc: add_new_node
End
C. Result
In the first cycle, both VirtualMacine-1 and VirtualMachine-3 have the same dependability, but the result of VM-1 has been selected as it has a lower IP address. VM-3 output was selected by DM from cycle 2 to 4, as it has the highest dependability among competing virtual machines. In cycle 5 VirtualMachine-3 still has the highest dependability, but it is not selected. Because its result was not passed by AT and TC, so consequently, it was not among competing virtual machines.
|
Cycle |
Real |
Virtual Machine-1 |
Virtual Machine-2 |
Virtual Machine-3 |
DM |
|||||||||||||
|
Time |
Relia- |
Relia- |
Relia- |
Selected |
||||||||||||||
|
Limit |
AT |
TC |
Time |
AT |
TC |
Time |
AT |
TC |
Time |
|||||||||
|
bility |
bility |
bility |
Node |
|||||||||||||||
|
(ms) |
||||||||||||||||||
|
Start |
– |
– |
– |
1 |
– |
– |
1 |
– |
– |
1 |
– |
|||||||
|
1 |
2500 |
Pass |
Pass |
2174 |
1.020 |
Fail |
Fail |
2997 |
0.980 |
Pass |
Pass |
2238 |
1.020 |
VM-1 |
||||
|
2 |
3700 |
Pass |
Fail |
3901 |
1.000 |
Pass |
Fail |
– |
0.941 |
Pass |
Pass |
3599 |
1.040 |
VM-3 |
||||
|
3 |
2150 |
Pass |
Fail |
3477 |
0.960 |
Pass |
Pass |
2101 |
0.960 |
Pass |
Pass |
2084 |
1.061 |
VM-3 |
||||
|
4 |
6300 |
Pass |
Fail |
– |
0.902 |
Pass |
Pass |
5732 |
0.979 |
Pass |
Pass |
6113 |
1.082 |
VM-3 |
||||
|
5 |
1950 |
Fail |
Fail |
– |
0.830 |
Pass |
Pass |
1906 |
0.998 |
Fail |
Fail |
1892 |
1.061 |
VM-2 |
||||
|
6 |
2800 |
Pass |
Pass |
2791 |
0.846 |
Pass |
Pass |
2682 |
1.018 |
Fail |
Fail |
2653 |
1.018 |
VM-2 |
||||
|
7 |
2350 |
Pass |
Pass |
2269 |
0.863 |
Pass |
Pass |
2312 |
1.039 |
Pass |
Fail |
2771 |
0.957 |
VM-2 |
||||
|
8 |
3200 |
Pass |
Pass |
3075 |
0.881 |
Pass |
Pass |
3102 |
1.059 |
Pass |
Fail |
– |
0.881 |
VM-2 |
||||
|
9 |
3900 |
Pass |
Pass |
3618 |
0.898 |
Pass |
Fail |
3949 |
1.038 |
Pass |
Pass |
3772 |
0.898 |
VM-1 |
||||
|
10 |
2650 |
Fail |
Fail |
2589 |
0.880 |
Pass |
Pass |
2601 |
1.059 |
Pass |
Fail |
3110 |
0.826 |
VM-2 |
||||
TABLE I : Result
v. Conclusion and future work
Tolerance of faults makes an important problem in the scope of environments of cloud computing. Fault tolerance method activates when a fault enters the boundaries i.e theoretically these strategies are implemented for detecting the failures and make an appropriate action before failures are about to occur.
I have looked after the need of fault tolerance with its various methods for implementing fault tolerance. Various called models for fault tolerance are discussed .In the present scene, there are number of models which provide different mechanisms to improve the system. But still there are number of problems which requires some concern for every frame work. There are some drawbacks non of them can full fill the all expected aspects of faults. So might be there is a possibility to carried over the drawbacks of all previous models and try to make a appropriate model which can cover maximum fault tolerance aspect.
References
- AnjuBala, InderveerChana,” Fault Tolerance- Challenges, Techniques and Implementation in Cloud Computing” IJCSI International Journal of Computer Science Issues, Vol. 9, Issue 1, No 1, January 2012 ISSN (Online): 1694-0814 www.IJCSI.org
- Sheheryar MalikandFabriceHuet “Adaptive Fault Tolerance in Real Time Cloud Computing” 2011 IEEE World Congress on Service
- Ravi Jhawar, Vincenzo Piuri, Marco Santambrogio,” A Comprehensive Conceptual System-Level Approach to Fault Tolerance in Cloud Computing”, 2012 IEEE, DOI 10.1109/SysCon.2012.6189503
- P. Mell, T. Grance. “The NISTdefinition of cloud computing”. Technical report, National Institute of Standards and Technology, 2009.
- Wenbing Zhao, Melliar-Smith, and P. M. Moser, “Fault tolerance middleware for cloud computing,” in 3rd International Conference on Cloud Computing (CLOUD 2010). Miami, FL, USA, 2010.
- R. Jhawar, V. Piuri, and M. D. Santambrogio, “A comprehensive conceptual system level approach to fault tolerance in cloud computing,” in Proc. IEEE Int. Syst. Conf., Mar. 2012, pp. 1–5.
- M. Castro and B. Liskov, “Practical Byzantine fault tolerance,” in Proc.3rd Symp. Operating Syst. Design Implementation, 1999, pp. 173–186.
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


DMCA / Removal Request
If you are the original writer of this essay and no longer wish to have your work published on UKEssays.com then please click the following link to email our support team:
Request essay removal