Report on Critical Review of Binary Search Tree Algorithm
| ✅ Paper Type: Free Essay | ✅ Subject: Computer Science |
| ✅ Wordcount: 78 words | ✅ Published: 12 Mar 2018 |
What is Binary Search Tree?
Binary search tree (BST) is a dynamic data structure, which means that its size is only limited by amount of free memory in the computer and number of elements may differ during the program executed. BST has aComparableKey (and an associated value) for each. All elements in its left sub-tree are less-or-equal to the node (<=), and all the elements in its right sub-tree are greater than the node (>). Assumexbe a node in a binary search tree. Ifyis a node in the left sub-tree ofx,thenkey[y] <= key[x].Ifyis a node in the right sub-tree ofx,thenkey[x] <= key[y].
A main pro of binary search trees is fast searching.
There are three type of binary search tree:
- Inorder traversal
- Preorder traversal
- Postorder traversal
In inorder traversal, the left sub-tree of the given node is visited first, then the value at the given node is printed and then the right sub-tree of the given node is visited. This process is applied recursively all the node in the tree until either the left sub-tree is empty or the right sub tree is empty.
Java code for inorder traversal:
public void printInorder(){
printInOrderRec(root);
System.out.println(“”);
}
/**
* Helper method to recursively print the contents in an inorder way
*/
private void printInOrderRec(Node currRoot){
if ( currRoot == null ){
return;
}
printInOrderRec(currRoot.left);
System.out.print(currRoot.value+”, “);
printInOrderRec(currRoot.right);
}
In preorder traversal, the value at the given node is printed first and then the left sub-tree of the given node is visited and then the right sub-tree of the given node is visited. This process is applied recursively all the node in the tree until either the left sub-tree is empty or the right sub tree is empty.
Java code for preorder traversal:
public void printPreorder() {
printPreOrderRec(root);
System.out.println(“”);
}
/**
* Helper method to recursively print the contents in a Preorder way
*/
private void printPreOrderRec(Node currRoot) {
if (currRoot == null) {
return;
}
System.out.print(currRoot.value + “, “);
printPreOrderRec(currRoot.left);
printPreOrderRec(currRoot.right);
}
In postorder traversal, the left sub-tree of the given node is traversed first, then the right sub-tree of the given node is traversed and then the value at the given node is printed. This process is applied recursively all the node in the tree until either the left sub-tree is empty or the right sub-tree is empty.
Java code for postorder traversal:
public void printPostorder() {
printPostOrderRec(root);
System.out.println(“”);
}
/**
* Helper method to recursively print the contents in a Postorder way
*/
private void printPostOrderRec(Node currRoot) {
if (currRoot == null) {
return;
}
printPostOrderRec(currRoot.left);
printPostOrderRec(currRoot.right);
System.out.print(currRoot.value + “, “);
}
Full code example for BST
//Represents a node in the Binary Search Tree.
class Node
{
//The value present in the node.
public int value;
//The reference to the left subtree.
public Node left;
//The reference to the right subtree.
public Node right;
public Node(int value)
{
this.value = value;
}
}
//Represents the Binary Search Tree.
class BinarySearchTree
{
//Refrence for the root of the tree.
public Node root;
public BinarySearchTree insert(int value)
{
Node node = new Node(value);
if (root == null)
{
root = node;
return this;
}
insertRec(root, node);
return this;
}
private void insertRec(Node latestRoot, Node node)
{
if (latestRoot.value > node.value)
{
if (latestRoot.left == null)
{
latestRoot.left = node;
return;
} else
{
insertRec(latestRoot.left, node);
}
} else
{
if (latestRoot.right == null)
{
latestRoot.right = node;
return;
} else
{
insertRec(latestRoot.right, node);
}
}
}
//Returns the minimum value in the Binary Search Tree.
public int findMinimum()
{
if (root == null)
{
return 0;
}
Node currNode = root;
while (currNode.left != null)
{
currNode = currNode.left;
}
return currNode.value;
}
//Returns the maximum value in the Binary Search Tree
public int findMaximum()
{
if (root == null)
{
return 0;
}
Node currNode = root;
while (currNode.right != null)
{
currNode = currNode.right;
}
return currNode.value;
}
//Printing the contents of the tree in an inorder way.
public void printInorder()
{
printInOrderRec(root);
System.out.println(“”);
}
//Helper method to recursively print the contents in an inorder way
private void printInOrderRec(Node currRoot)
{
if (currRoot == null)
{
return;
}
printInOrderRec(currRoot.left);
System.out.print(currRoot.value + “, “);
printInOrderRec(currRoot.right);
}
//Printing the contents of the tree in a Preorder way.
public void printPreorder()
{
printPreOrderRec(root);
System.out.println(“”);
}
//Helper method to recursively print the contents in a Preorder way
private void printPreOrderRec(Node currRoot)
{
if (currRoot == null)
{
return;
}
System.out.print(currRoot.value + “, “);
printPreOrderRec(currRoot.left);
printPreOrderRec(currRoot.right);
}
//Printing the contents of the tree in a Postorder way.
public void printPostorder()
{
printPostOrderRec(root);
System.out.println(“”);
}
//Helper method to recursively print the contents in a Postorder way
private void printPostOrderRec(Node currRoot)
{
if (currRoot == null)
{
return;
}
printPostOrderRec(currRoot.left);
printPostOrderRec(currRoot.right);
System.out.print(currRoot.value + “, “);
}
}
//Main method to run program.
class BSTDemo
{
public static void main(String args [])
{
BinarySearchTree bst = new BinarySearchTree();
bst .insert(10)
.insert(40)
.insert(37)
.insert(98)
.insert(51)
.insert(6)
.insert(73)
.insert(72)
.insert(64)
.insert(99)
.insert(13)
.insert(9);
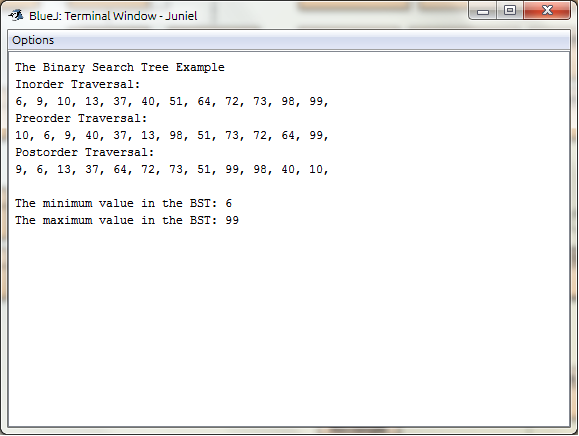
System.out.println(“The Binary Search Tree Example”);
System.out.println(“Inorder Traversal:”);
bst.printInorder();
System.out.println(“Preorder Traversal:”);
bst.printPreorder();
System.out.println(“Postorder Traversal:”);
bst.printPostorder();
System.out.println(“”);
System.out.println(“The minimum value in the BST: ” + bst.findMinimum());
System.out.println(“The maximum value in the BST: ” + bst.findMaximum());
}
}
Output example
Linear Search Algorithm
Linear search, also known as sequential search, is a operation that checks every element in the list sequentially until the target element is found. The computational complexity for linear search isO(n),making it mostly much less efficient than binary searchO(log n).But when list items can be arranged in order from greatest to lowest and the possibility appear as geometric distribution (f (x)=(1-p) x-1p, x=1,2),then linear search can have the potential to be greatly faster than binary search. The worst case performance scenario for a linear search is that it needs to loop through the entire collection; either because the item is the last one, or because the item isn’t found. In other words, if havingNitems in the collection, the worst case scenario to find an item isNiterations. This is known asO(N)using theBig O Notation. The speed of search grows linearly with the number of items within the collection. Linear searches don’t require the collection to be sorted.
Example java program to show linear search algorithm
class LinearSearchDemo
{
public static int linearSearch(int[] array, int key)
{
int size = array.length;
for(int i=0;i { if(array[i] == key) { return i; } } return -1; } public static void main(String a[]) { int[] array1= {66,42,1,99,59,53,16,21}; int searchKey = 99; System.out.println(“Key “+searchKey+” found at index: “+linearSearch(array1, searchKey)); int[] array2= {460,129,128,994,632,807,777}; searchKey = 129; System.out.println(“Key “+searchKey+” found at index: “+linearSearch(array2, searchKey)); } } Output example Why Linear Search? Alinear searchlooks down a list, one item at a time, without skipping. In complexity terms this is an O(n) search where the time taken to search the list gets bigger at the same rate as the list does. Binary searchtree when starts with the middle of a sorted list, and it see whether that’s greater than or less than the value it looking for, which determines whether the value is in the first or second half of the list. Skip to the half way through the sub-list, and compare again. In complexity terms this is an O(log n) search where the number of search operations grows more slowly than the list does, because it is halving the “search space” with each operation. For example, suppose to search for U in an A-Z list of letter where index 0-25 and the target value at index 20. A linear search would ask: list[0] == ‘U’? False. list[1] == ‘U’? False. list[2] == ‘U’? False. list[3] == ‘U’? False. . .. … list[20] == ‘U’? True. Finished. The binary search would ask: Comparelist[12](‘M’) with ‘U’: Smaller, look further on. (Range=13-25) Comparelist[19](‘T’) with ‘U’: Smaller, look further on. (Range=20-25) Comparelist[22](‘W’) with ‘U’: Bigger, look earlier. (Range=20-21) Comparelist[20](‘U’) with ‘U’: Found it. Finished. Comparing the two: Divide and Conquer Algorithm Divide and conquer is a top-down technique for designing algorithms that consists of dividing the problem into smaller sub-problems hoping that the solutions of the sub-problems are easier to find and then composing the partial solutions into the solution of the original problem. Divide and conquer paradigm consists of following major phases: The similarity with Binary Search Tree, it is a degenerate divide and conquer search algorithm but with no combine phase. It searches for akeyin asortedvector then returning theindexwhere the key was found or return -1 when not found. It also reduces the problem size by half each recursion. The algorithm definition: Recursion Technique Recursionis a technique of solving problems that includes breaking down a problem into smaller and smaller sub-problems until get to a small enough problem that it can be solved trivially. Normally recursion includes a function calling itself. While it may not would appear to be much at first glance, recursion allow to write elegant solutions to problems that may otherwise be extremely hard to program. It is very similar with binary search tree that using divide and conquer technique which is breaking down problem into sub-problems. A binary search or half-interval search algorithm discover the position of a specified value within a sorted array. In each step, the algorithm compares the input key value with the key value of the middle element of the array. If the keys match, then a matching element has been found so its index is returned. Otherwise, if the looked key is less than the middle element’s key, then the algorithm repeats its action on the sub-array to the left of the middle element or, if the input key is greater, on the sub-array to the right. If the remaining array to be searched is reduced to zero, then the key cannot be found in the array and a special “Not found” indication is returned. Every repetition eliminates half of the remaining possibilities. This makes binary searches very efficient even for large collections. Binary search requires a sorted collection. Additionally, binary searching can only be applied to a collection that allows random access (indexing). Worst case performance: O(log n) Best case performance: O(1) Recursion is utilized as a part in this algorithm because with each pass a new array is created by cutting the old one in half. The binary search procedure is then called recursively, this time on the new array. Commonly the array’s size is adjusted by manipulating a beginning and ending index. The algorithm exhibits a logarithmic order of growth because it essentially divides the problem domain in half with each pass. Conclusion The conclusion is there is never be the best approach to follow blindly, each of these algorithms has its pros and cons. So, if there is any scenario or problem, it should be analyze first and adopt one of these algorithms to find what’s suit. REFERENCE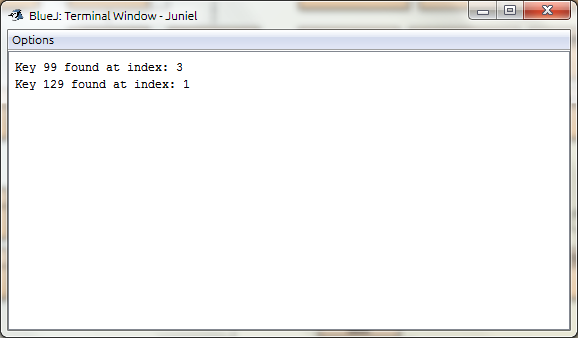
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


DMCA / Removal Request
If you are the original writer of this essay and no longer wish to have your work published on UKEssays.com then please click the following link to email our support team:
Request essay removal