Efficient Prediction System Using Artificial Neural Networks
| ✅ Paper Type: Free Essay | ✅ Subject: Computer Science |
| ✅ Wordcount: 2376 words | ✅ Published: 26 Mar 2018 |
- Jay Patel
Abstract- Predicting is making claims about something that will happen, often based on information from past and from current state. Neural networks can be used for prediction with various levels of success. The neural network is trained from the historical data with the hope that it will discover hidden dependencies and that it will be able to use them for predicting into future. It is an approach for making prediction efficient using best features on which prediction is more dependent.
Keywords: Artificial Neural Networks; Feature set; Profiles
- INTRODUCTION
Artificial neural networks are computational models inspired by animal central nervous systems (in particular the brain) that are capable of machine learning and pattern recognition. They are usually presented as systems of interconnected “neurons” that can compute values from inputs by feeding information through the network. For example, in a neural network for handwriting recognition, a set of input neurons may be activated by the pixels of an input image representing a letter or digit. The activations of these neurons are then passed on, weighted and transformed by some function determined by the network’s designer, to other neurons, etc., until finally an output neuron is activated that determines which character was read. Mainly three types of ANN models are present single layer feed forward network, Multilayer feed forward network and recurrent network Single layer feed forward network consist of only one input layer and one output layer. Input layer neurons receive the input signals and output layer receives output signals.
In a feed forward network the output of the network does not affect the operation of the layer that is producing this output. In a feedback network however the output of a layer after the layer being fed back into, can affect the output of the earlier layer. Essentially the data loops through the two layers and back to start again. This is important in control circuits, because it allows the result from a previous calculation to affect the operation of the next calculation. This means that the second calculation can take into account the results of the first calculation, and be controlled by them. Weiners work on cybernetics was based on the idea that feedback loops were a useful tool for control circuits. In fact Weiner coined the termcybernetics based on the Greek kybernutos or metallic steersman of a fictional boat mentioned in the Illiad. Neural models ranged from complex mathematical models with Floating point outputs to simple state machines with a binary output. Depending on whether the neuron incorporates the learning mechanism or not, neural learning rules can be as simple as adding weight to a synapse each time it fires, and gradually degrading those weights over time, as in the earliest learning rules, Delta rules that accelerate the learning by applying a delta value according to some error function in a back propagation network, to Pre-synaptic/Post-synaptic rules based on biochemistry of the synapse and the firing process. Signals can be calculated in binary, linear, non-linear, and spiking values for the output.



Figure 1. ANN Models
Multilayer feed forward network consist of input, output and one more addition than single layer feed forward is hidden layer. Computational units of hidden layer are called hidden neurons. In Multilayer Feed Forward Network there must be only one input layer and one output layer and hidden layers can be of any numbers. There is only one difference in recurrent network from feed forward networks is that there is at least one feedback loop.
In neurons we can input vectors taken as input and weights are included. With the help of weights and input vectors we can calculate weighted sum and taking weighted sum as parameter we can calculate activation function. There are different activation functions available e.g. thresholding, Signum, Sigmoidal, Hyperbolic Tangent.
- Phase ordering of optimization techniques
In optimizing compilers, it is standard practice to apply the same set of optimization phases in a fixed order on each method of a program. However, several researchers have shown that the best ordering of optimizations varies within a program, i.e., it is function-specific. Thus,we would like a technique that selects the best ordering of optimizations for individual portions of the program, rather than applying the same fixed set of optimizations for the whole program. This paper develops a new method-specific technique that automatically selects the predicted best ordering of optimizations for different methods of a program. They develop this technique within the Jikes RVM Java JIT compiler and automatically determine good phase-orderings of optimizations on a per method basis. Rather than developing a handcrafted technique to achieve this, they make use of an artificial neural network (ANN) to predict the optimization order likely to be most beneficial for a method. Our ANNs were automatically induced using Neuro-Evolution for Augmenting Topologies (NEAT). A trained ANN uses input properties (i.e., features) of each method to represent the current optimized state of the method and given this input, the ANN outputs the optimization predicted to be most beneficial to the method at that state. Each time an optimization is applied, it potentially changes the properties of the method. Therefore, after each optimization is applied, they generate new features of the method to use as input to the ANN. The ANN then predicts the next optimization to apply based on the current optimized state of the method. This technique solves the phase ordering problem by taking advantage of the Markov property of the optimization problem. That is, the current state of the method represents all the information required to choose an optimization to be most beneficial at that decision point.
Most compilers apply optimizations based on a fixed order that was determined to be best when the compiler was being developed and tuned. However, programs require a specific ordering of optimizations to obtain the best performance. To demonstrate our point, we use genetic algorithms (GAs), the current state-of-the-art in phase-ordering optimizations, to show that selecting the best ordering of optimizations has the potential to significantly improve the running time of dynamically compiled programs. They used GAs to construct a custom ordering of optimizations for each of the Java Grande and SPEC JVM 98 benchmarks. In this GA approach, we create a population of strings (called chromosomes), where each chromosome corresponds to an optimization sequence. Each position (or gene) in the chromosome corresponds to a specific optimization from Table 2, and each optimization can appear multiple times in a chromosome. For each of the experiments below, we configured our GAs to create 50 chromosomes (i.e., 50 optimization sequences) per generation and to run for 20 Generations.
- Technique for Implementing GA
We ran two different experiments using GAs. The first experiment consisted of finding the best optimization sequence across our benchmarks. Thus, we evaluated each optimization sequence (i.e., chromosome) by compiling all our benchmarks with each sequence. We recorded their execution times and calculated their speedup by normalizing their running times with the running time observed by compiling the benchmarks at the O3 level. That is, we used average speedup of our benchmarks (normalized to opt level O3) as our fitness function for each chromosome. This result corresponds to the “Best Overall Sequence” bars in Figure 1. The purpose of this experiment was to discover the optimization ordering that worked best on average for all our benchmarks. The second experiment consisted of finding the best optimization ordering for each benchmark. Here, the fitness function for each chromosome was the speedup of that optimization sequence over O3 for one specific benchmark. This result corresponds to the “Best Sequence per Benchmark” bars in Figure 1. This represents the performance that we can get by customizing an optimization ordering for each benchmark individually.
- Results
The results of these experiments confirm two hypotheses. First, significant performance improvements can be obtained by finding good optimization orders versus the well-engineered fixed order in Jikes RVM. The best order of optimizations per benchmark gave us up to a 20% speedup (FFT) and on average 8% speedup over optimization level O3. Second, as shown in previous work, each of our benchmarks requires a different optimization sequence to obtain the best performance. One ordering of optimizations for the entire set of programs achieves decent performance speedup compared to O3.

Figure 2.Results of experiments using GA
However, the “Best Overall Sequence” degrades the performance of three benchmarks (LUFact, Series, and Crypt) compared to O3. In contrast, searching for the best custom optimization sequence for each benchmark, “Best Sequence for Benchmark”, allows us to outperform both O3 and the best overall sequence.
- Motivation
Predict the current best optimization: This method would use a model to predict the best single optimization (from a given set of optimizations) that should be applied based on the characteristics of code in its present state. Once an optimization is applied, we would re-evaluate characteristics of the code and again predict the best optimization to apply given this new state of the code. For this we can apply Artificial Neural Network in this method and we will also include profiles for better prediction of optimization sequence for particular program.
- Automatic Feature Generation
Automatic Feature generation system is comprised of the following components: training data generation, feature search and machine learning [5]. The training data generation process extracts the compiler’s intermediate representation of the program plus the optimal values for the heuristic we wish to learn. Once these data have been generated, the feature search component explores features over the compiler’s intermediate representation (IR) and provides the corresponding feature values to the machine learning tool. The machine learning tool computes how good the feature is at predicting the best heuristic value in combination with the other features in the base feature set (which is initially empty). The search component finds the best such feature and, once it can no longer improve upon it, adds that feature to the base feature set and repeats. In this way, we build up a gradually improving set of features.
a. Data Generation
In a similar way to the existing machine learning techniques (see section II) we must gather a number of examples of inputs to the heuristic and find out what the optimal answer should be for those examples. Each program is compiled in different ways, each with a different heuristic value. We time the execution of the compiled programs to find out which heuristic value is best for each program. We also extract from the compiler the internal data structures which describe the programs. Due to the intrinsic variability of the execution times on the target architecture, we run each compiled program several times to reduce susceptibility to noise.
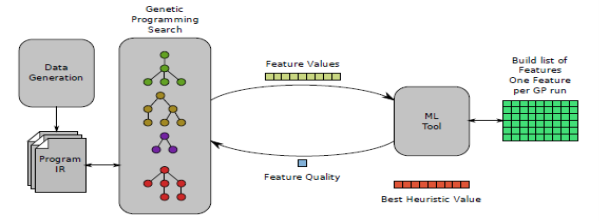
Figure 3. Automatic Feature Generation
b. Feature Search
The feature search component maintains a population of feature expressions. The expressions come from a family described by a grammar derived automatically from the compiler’s IR. Evaluating a feature on a program generates a single real number; the collection of those numbers over all programs forms a vector of feature values which are later used by the machine learning tool.
c. Machine Learning
The machine learning tool is the part of the system that provides feedback to the search component about how good a feature is. As mentioned above, the system maintains a list of good base features. It repeatedly searches for the best next feature to add to the base features, iteratively building up the list of good features. The final output of the system will be the latest features list.
Our system additionally implements parsimony. Genetic programming can quickly generate very long feature expressions. If two features have the same quality we prefer the shorter one. This selection pressure prevents expressions becoming needlessly long.
E. Motivation
They have developed a new technique to automatically generate good features for machine learning based optimizing compilation. By automatically deriving a feature grammar from the internal representation of the compiler, we can search a feature space using genetic programming. We have applied this generic technique to automatically learn good features.
- Code Optimization in Compilers using ANN
For ordering of different optimization techniques using ANN we must need to implement that in 4Cast-XL as it is a dynamic compiler. 4Cast-XL constructs an ANN, Integrate the ANN into Jikes RVM’s optimization driver than Evaluate ANN at the task of phase-ordering optimizations. For each method dynamically compiled, repeat the following two steps
- Generate a feature vector of current method’s state
- Generate profiles of program
- Use ANN to predict the best optimization to apply
Use ANN to predict the best optimization to apply. Run benchmarks and obtain feedback for 4Cast-XL Record execution time for each benchmark optimized using the ANN. Obtain speedup by normalizing each benchmark’s running time to running time using default optimization heuristic.
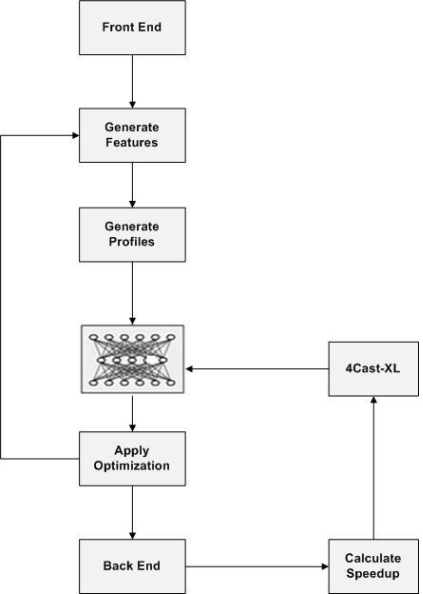
Figure 4. Code Optimization in compilers using ANN with Profiles
Results
Research work is aimed for optimizing code using artificial neural networks. In order to make this precise, better profiles generated from given set of features using Milepost GCC compiler with ten different programs. Experimental results demonstrate that profiles of program can be used for optimization of code.

Motivation
This section gives a detailed overview of how Neuro-evolution machine learning is used to construct a good optimization phase-ordering heuristic for the optimizer. The first section outlines the different activities that take place when training and deploying a phase ordering heuristic. This is followed by sections describing how we use 4cast-XL to construct an ANN, how we extract features from methods, and how best features called Profiles and ANNs allow us to learn a heuristic that determines the order of optimizations to apply. It motivates us to apply this approach for different types of predictions using Artificial Neural Networks.
- Prediction Using Neural Networks
Neural networks can be used for prediction with various levels of success. The advantage of then includes automatic learning of dependencies only from measured data without any need to add further information (such as type of dependency like with the regression). The neural network is trained from the historical data with the hope that it will discover hidden dependencies and that it will be able to use them for predicting into future. In other words, neural network is not represented by an explicitly given model. It is more a black box that is able to learn something.
1
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


DMCA / Removal Request
If you are the original writer of this essay and no longer wish to have your work published on UKEssays.com then please click the following link to email our support team:
Request essay removal