Development of Human Computer Interface
| ✅ Paper Type: Free Essay | ✅ Subject: Computer Science |
| ✅ Wordcount: 2431 words | ✅ Published: 12 Mar 2018 |
Development of Human Computer Interface Based on Cognitive Model Integrated With Data Mining Techniques
M. Mayilvaganan, D. Kalpanadevi
Abstract
First review concern about the relevant literature survey in order to evaluate the performance of learning ability and knowledge, behavior, attention, by the category of cognitive skills which is analyzed by various data mining techniques. In this paper focus the concepts of cognitive process and data mining techniques which are used to evaluate the usability of system based on metrics for analyzing problem solving resources. The implementation of cognitive process in the Human computer Interface(HCI) system contributes to give better performance of the human behavior which will be analyses by data mining technique of classification and clustering process can be proposed to evaluate the knowledge of person in efficient manner. This implies that the skills will be stimulated over time through intentional support and also helps for various resources based on different categorize.
Keywords: GOM Model, Data mining techniques, Human Computer Interface system, Observational method, C4.5, Naïve Bayes, K-means, Weka Tool.
- Introduction
Data mining also called Knowledge Discovery in Databases (KDD) in the field of discovering novel and potentially useful information from large amount of data. In recent years, there has been increasing interest on the use of data mining to investigate scientific questions for problem solving analysis, an area of human thinking, behavior, analyse the performance from the knowledge criteria are gathered by the techniques of data mining [1]. An ability of cognitive performance is essential in various environment, which is influenced by many qualitative attributes are included for forming the data set. Data mining techniques such as K-nearest neighbor, decision tree, Naïve Bayes, Neural network, Fuzzy, Genetic and other techniques are applied in various environments [3]. This paper describes about literature survey on to analyse the cognitive performance integrates with data mining techniques.
2. Cognitive process in Human Computer Interaction (HCI)
Human computer interaction is concerned with how people use computer system to perform tasks, usually in a real life work setting. To evaluate the competing task by using usability criteria based on cognitive models. Cognitive processes is the process that involve knowledge, attention, memory, producing and understanding the language, problem solving and decision making. All these are very important for human behavior. The working process of each task can be analyzed by data mining techniques for finding the human behavior, attitude and attention performance in respect way.
2.1 Collecting Qualitative Data through Cognitive process
Scope of knowledge is accumulated information, problem solving schemas, performance skills, expertise, memory capacity, problem representation ability, abstraction and categorization abilities, synthesis skills, long-term concentration ability, motivation, efficiency and accuracy.
Data which is collected by using variety of techniques like Video and audio recording, software logging, Scan converters, think- aloud protocols or pencil and paper field notes. These techniques can be followed by several cognitive models such as GOM model, KLM model, Cognitive complexity which has to be evaluating by language based model such as Command Language grammar, Task Action Language, Task Action Grammar, and Knowledge Analysis of tasks.
In cognitive complexity, the tasks can be assessed by analysing the number of entities that have to be related in a single representation. For eg: The hypothesis ideas such as collecting the personal data, family background, academic details, extracurricular activities, activities while during studies etc., are the basic attributes for analysing the performance skill for required person.
The techniques are outlined for analysis of cognitive complexity in general cognition, cognitive development, mathematics education, reasoning tasks, psychometric test items, and industrial decision making, problem solving etc. The role of questionary format on the basis of problem solving, reasoning task, behaviour methods to analyse in effective way.
2.2 GOMS Model
GOMS model stands for Goals, Operators, Methods, and Selection rules needed to perform a task. Tasks are broken down into their components to predict performance times.
Figure.1 represents the process of GOM model describe as
Goals – are objectives
Operators – are the actions that change the system state or the cognitive state.
Methods – are description of procedures for achieving goals stored in the user’s knowledge
structure of the task built-up for the problem solving.

Fig.1 GOM model
Selection Rules – are If …Then statements to enable the user to choose between the methods
under the time complexity.
2.3 Keystroke Level Model (KLM)
KLM is derived from GOMS and describes the time taken to execute sub-task using the system facilities. Total time taken for an action is arrived at by simply adding together the times for each component task. To obtain the predicted time for a task and add the times for individual operators based on Fitt law, Steering Law.
2.4 Cognitive Complexity Theory
Cognitive complexity theory is an extension of GOMS. It attempts to predict how difficult learn and use a system will be base on a GOMS model of the task and its required knowledge, a model of the user current knowledge and a list of the items of knowledge to be learned in order for the user to be able to make error- free use of the system.
2.5 Knowledge Analysis of Tasks (KAT)
KAT is an evaluate model to identify the task gathered from variety of techniques including interviews and questionnaires, observation, rating scales, repertory grids and conduct online test for problem solving. The completed tasks will analysis for the performer by producing the result. KAT involves several stages such as
- Identify the person goals, sub goal and subtasks
- Work out order in which sub goal are to be carried out.
- Identify task strategies.
- Identify procedures.
- Identify Task Objects and Actions.
3. Data Mining Concepts Integrates To HCI
The variety of domain values which are related with performance based on their required result carried out by cognitive process model. From fig.1 shows such factor may be founded by means of analysis based on data mining techniques. Usability criteria can be measured by setting performance targets in the system design at the stage of effectiveness, learning ability, and flexibility, attitude which is evaluated by either survey or experimental method. An analytical evaluation method is followed by the GOMS model, KLM model and Cognitive complexity theory for end-user testing through knowledge task analysis. After observational evaluation happened, the collection of data will be stored in the database.
Using data mining techniques, preprocessing, data cleaning and transformation are carried out for avoid the redundancy and clear the noisy data from the database. After preprocessing, several algorithms are applied to discover the knowledge and performance factor are analysed to identify the human ability.
4. Data mining techniques
An application of Data mining is a rich focus of Classification algorithm, Association algorithm, Clustering algorithm which can be applied to the field of some resources it concerns with developing methods that discover the knowledge from data originating from any other resource environment.





















Fig.1. Methodology Process of analyse skill by Data Mining Techniques
4.1 Classification Techniques
In Classification process, the derive model is to predict the class of objects whose class label is unknown. The derived model is based on the analysis of asset of training data.
In educational data mining, the work of data was predicted by logical rule of the Classification algorithms with the represent of common domain values for analyzing the qualitative performance of required details.
In this case study, it can be predicting the human behavior through HCI by given the problem solving question, observational process and other resources. In this technique, it can be classified the functioning of cognitive style such as logical reasoning, analytical ability, Numerical ability, balanced profile for skill learning, personality analysis and other styles for analyzing the skill for the human user from the collected dataset systematically.
In C4.5 algorithm construct in which enhanced by ID3 algorithm and it works in divide and conquer method. At the beginning stage the root is present to associate with training data set. The rule set is formed from the initial state of decision tree. Each path from the initial state, the condition will be evaluate and simplified by the effect of rule and an outcomes will put on the required leaf, the step will continuous when it comes discarding the condition. Let freq (Ci, S) stand for the number of samples in S that belong to class Ci (out of k possible classes), and S denotes the number of samples in the set S. Then the entropy of the set S:
 equation (1)
equation (1)
After set T has been partitioned in accordance with n outcomes of one attribute test X:
 equation (2)
equation (2)
gain (x) = info (T) – infox(T)
In Naïve Bayes algorithm, to reduce computation in evaluating P (X|Ci), the naive assumption of class conditional is made. This presumes that the values of the attributes are conditionally independent of one another, given the class label of the tuple. The data set predicts that tuple X belongs to the class Ci.
 equation (3)
equation (3)
By Bayes’ theorem, the classic for which P (Ci |X) is maximized is called the maximum posteriori hypothesis.
P (Ci |X) = P(X|Ci)P(Ci) / P(X) equation (4)
The classic for which P (Ci |X) is maximized is called the maximum posteriori hypothesis. It can easily estimate the probabilities P(x1|Ci)×P(x2|Ci)×··×P(xn|Ci) from the training tuples by the following relationship.
 equation (5)
equation (5)
4.3 Clustering Techniques
Cluster analysis is used to segment a large set of data into subsets called clusters. It is the process of grouping or organizing a set of objects into distinct group based on some similarity or dissimilarity measure among the individual objects, such that the objects in the same group are more similar to each other than those in other groups [2]. Through this technique, it can be cluster the skill level in style wise or any other pattern and analyse in each cognitive style in grouped manner.
In this paper, K-means clustering can be used to analyse the classification of training tuple from the rule base relation, then it can be grouped the performance of skill in pattern wise. K-means algorithm takes the input parameter and partitions a set of n objects into k clusters. Cluster similarity is measured in regard to the mean value of the objects in a cluster based on center of gravity. For each of the remaining object is assigned to the cluster based on the distance. Iteration can be repeated until the function can satisfied.
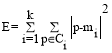 equation (6)
equation (6)
where E is the sum of the square error for all objects in the data set; p is the point in space representing a given object; and mi is the mean of cluster Ci, the distance from the object to its cluster center is squared, and the distances are summed. The resulting of k clusters as compact and group can be formed for the required pattern.
- Experimentation of Training Data set and Result Analysis Using Data mining Techniques
From this research survey, it can be analysed and produced an idea to propose the human performance based on cognitive process through Human Computer interface by interacting from computer system. The training data set can be experimented in data mining techniques to analysis the behavior of the human user via computer system.
In this experiment, Classification technique approach was obtained accuracy to classification for forum data. Using Weka tool the classification algorithm was provided to experiment with sample data set by the given attributes like logical reasoning, numerical ability and personality for analyse the skill level of human user. Through clustering technique it can be analysed the performance of skill level from the classified training data set.
Weka provides the range of the functioning in style wise and estimates the accuracy of resulting predicting model in classification algorithms are C4.5 and Naïve Bayes techniques used in the analyzing process. These techniques are decision making rule process which can be worked in probability evaluation model on the analysis of a set of training data.
If logical_reasoning = good and Numerial_ability = good and personality=good then
Performance= Good_skill_user
If logical_reasoning = poor and Numerial_ability = poor and personality=good then
Performance= Average_skill_user
If logical_reasoning = poor and Numerial_ability = poor and personality=poor then
Performance= below _average _skill_user
TABLE.1: PERFORMANCE MEASURE FOR TRAINING DATA OF 200 SAMPLE INSTANCE
|
Algorithm |
Execution Time (Sec) |
Number of Correctly classified instance (200 training data set) |
|
C4.5 |
0.25 |
170 |
|
Naïve Bayes |
0.1 |
142 |
From table.1, shows the measuring the performance of execution time and correctly classified instance based on the proposed algorithm for predicting in rule. In second experiment, the data clustering method can be used for checking the similarity based on the criteria of performance like Good skill user, Average Skill user and below average skill user using K-means algorithm technique.

Fig. 2: Clustering Performance in pattern wise analysis
6. Conclusion
In this studied, it can be concluded that an idea of Human computer interface which integrate with respect to cognitive models for analyzing human behavior of skill gathered by using problem solving using data mining techniques. By using 200 instance of sample training data set, which can be predicted by the rule of classification techniques of C4.5 and Naïve Bayes algorithm which can be produced their efficiency are C4.5 classified by execution time of accuracy is 0.25 second and 170 instance are correctly classified. Naïve Bayes algorithm classified by execution time of accuracy is 0.1 second and 142 instances are correctly classified. From the above analysis more instance of classifier is C4.5 algorithm was well suited for classification to skill analysis. Finally, it can be analysis by category wise based on pattern then produce 80% of Good skill user, 40% of Average Skill user and 5% below average skill user using K-means clustering algorithm.
- References
7.1 Book
[1] Jiawei Han and Micheline Kamber, Data Mining: Concepts and Techniques, 2nd ed., Morgan Kaufmann Publishers, 2006.
- Arun K Pujari, “Data mining techniques”, University Press (India) Private Limited.
- David Hand, Heikki Mannila & adhraic Smyth, “Principles of Data Mining”, MIT Press, 2001.
- Anderson, J.R, ‘The Architecture of Cognition’, Harvard University Press, Cambridge (1983).
7.2 Journal Article
[5] Richard E.Clark, “Cognitive Task Analysis”, October 14, 2006.
[6] Chipman, S. F., Schraagen, J. M., & Shalin, V. L., “Introduction to Cognitive task analysis”
[7] David H. Jonassen, “Analysis of Task Procedures”, Copyright _@ 1986.
7.3 Conference Proceedings
[8] Bainbridge, L. “The change in concepts needed to account for human behaviour in complex dynamic tasks”, IEEE Transactions on Systems, Man and Cybernetics, Part A: Systems and Humans, 27, 351–359.
[9] Arbi Ghazarian, “Pauses in man-machine interactions: a clue to users “ Skill levels and their user interface requirements”, Int. J. Cognitive Performance Support, Vol. 1, No. 1, 2013.
[10] Sheikh,L Tanveer B. and Hamdani,S., “Interesting Measures for Mining Association Rules”. IEEE-INMIC Conference December. 2004.
[11] M. O. Mansur, M.Sap and M. Noor, “Outlier Detection Technique in Data mining: A Research Perceptive”, In Postgraduate Annual Research Seminar, 2005.
1
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


DMCA / Removal Request
If you are the original writer of this essay and no longer wish to have your work published on UKEssays.com then please click the following link to email our support team:
Request essay removal