AQM: A Mechanism of Congestion Control in Networks
| ✅ Paper Type: Free Essay | ✅ Subject: Computer Science |
| ✅ Wordcount: 1825 words | ✅ Published: 26 Mar 2018 |
- Saira Saeed, Bilal Shams,
Abstract: Congestion in the network occurs when node or link carries so much data that its quality of service downgrade. Active queue management is the most well-known algorithm to control congestion in the network. This paper discussed some of the queue length based and load based algorithms in AQM, we also highlighted its pros and cons.
Keyword: congestion, Active queue management
1. Introduction: Congestion can take place at sensors that receive more data than its maximum forwarding rate. These consequences in long delay in data delivery and wasting of resources due to lost or dropped packets. When congestion occurs in network the Quality of service will disturb which is an important feature in sending data from node to another. When buffer overflow the packet drops so it would increase the energy consumptions of a sensor as the packets need to be retransmitted. Higher packet drops will also reduce the throughput of the data. Some multimedia data such as voice and video are critical to time delay [1]. Thus, congestion needs to be controlled to ensure that the end-to-end delay is also minimized.
2. Active queue management (AQM)
The role of Active Queue Management (AQM) in IP networks was to balance the work of end-system protocols such as the Transmission Control Protocol (TCP) in congestion control hence to enlarge network utilization, and limit packet loss and delay.[2] AQM is a scheme which shares bandwidth fairly and control congestion over the routers/internet. According to the congestion metric active queue management has classified in to queue length based, load based and queue length and load based.

Fig.2. Classification of AQM scheme. [3]
Congestion is observed by average queue length in queue based schemes, and the control aspires to stabilize the queue length. The downside of queue based scheme is that a backlog is inherently required. Load based schemes precisely predict the utilization of the link, and determine congestion and take actions based on the packet arrival rate. Rate-based schemes can grant Early feedback for congestion. The goals of the load based AQMs are to alleviate rate mismatch between enqueue and dequeue, and achieve low loss, low delay and high link utilization. The third AQM scheme is the combination of load based and queue length which measure congestion and get a tradeoff between queues stability and responsiveness. [3]
In this paper we just discussed the queue length based and load based briefly.
3. AQMs Based On Queue Length Merit.
3.1. Random Early Detection (RED).
The main objectives of RED is to minimize packet loss and queuing delay, avoid global synchronization of sources, maintain high link utilization, and remove biases against bursty flows. RED avoids congestion early and delivers congestion notification to the end source and allows them to reduce the transmission rate before overflow occurs. To reduce the delay of flows RED keeps the queue size full. RED maintains an exponentially weighted moving average (EWMA) of the queue length which is used to detect incipient congestion. When average queue length greater than min threshold, packets are randomly dropped or marked with explicitly congestion notification (ECN). [4][5] When average queue length greater max threshold all packets are dropped or marked.

Fig.3. RED algorithm [3]
3.2. FRED (Fair random early detection)
FRED is modified version of RED therefore it reduces the unfairness of RED. Inside the internet route FRED maintains state information for every flow. When different types of traffic shares one link, RED allows unfair bandwidth sharing because RED does not take the bandwidth utilization of the flow into account when dropping packets. The author proposes FRED as solution. The main objective of fair random flow is to provide different strategies of dropping to different kind of flows. Flows that take more bandwidth shall be isolated where as low speed and bursty flows should be protected and safe from dropping. [survey2]FRED maintains queue size of per flow and drops packets conditionally comparing per flow queue size with average per flow queue.

Fig.4. FRED Algorithm [4]
3.3. CHOKE (Choose and Keep for responsive flows, Choose and Kill for unresponsive flows)
In the CHOKE algorithm a packet is drawn randomly from FIFO buffer whenever a new packet arrived at congestion router. This packet is compared with newly arriving packet. Both packets are dropped if it belongs to the same flow, otherwise the new incoming packet is confessed into the buffer with a probability that depends on the level of congestion and the randomly chosen packet is kept intact. CHOKE is simplest and stateless algorithm which does not provide any special data structure. However when the number of flows is large compared to the buffer space than this algorithm performance is not well. [6]
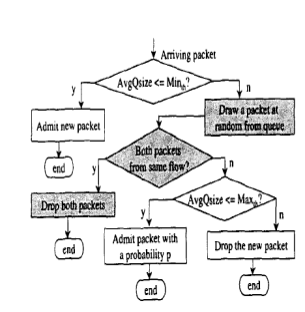
Fig.5. CHOKE algorithm
4. AQM on load based.
4.1. BLUE: A New Class of Active Queue Management Algorithms.
RED queue length gives very little information about the number of competing connections in a shared link. BLUE overcome the drawbacks of RED by using packet loss and link idle events for protecting TCP flows against non-responsive flows. [1] BLUE, basically is a different active queue management algorithm which uses packet loss and link utilization history to manage congestion.
BLUE keep up a single probability, which it uses to mark or drop packets when they are queued. If the queue is frequently dropping packets due to buffer overflow, BLUE increments the marking probability, therefore increasing the rate at which it sends back congestion notification. On the other hand, if the queue becomes empty or if the link is idle, BLUE decreases its marking probability.
The main purpose of using BLUE is that congestion control can be performed with a least amount of buffer size. Other algorithms like RED need a large buffer size to attain the same goal. [7]

Fig.6. BLUE Algorithm.
4.2. SFED: Selective Fair Early Detection
Selective fair early detection is an easy to implement rate control based AQM discipline which can be joined with any scheduling discipline. It maintains a token bucket for every flow or comprehensive flows. The token filling rates are in proportion to the allowable bandwidths. The tokens are removed from the corresponding bucket whenever a packet is enqueued. The decision to enqueue or drop a packet of any flow depends on the occupancy of its bucket at that time. A sending rate higher than the permitted bandwidth results in low bucket occupancy and so a larger drop probability thus indicating the onset of congestion at the gateway. This ensures the adaptive flow to attain a steady state and prevents it from getting penalized severely. However non-adaptive flows will continue to send at the same rate and thus will suffer more losses. The rate at which the tokens are removed from bucket of a flow is equal to the rate of incoming packets of that flow, but the rate of addition of tokens in a bucket depends on its permitted share of bandwidth and not on the rate at which packets of that particular flow are dequeued. In this way token bucket controls the bandwidth consumed by a flow.[8].
4.3. FABA: Fair adaptive bandwidth allocation:
FABA is the extension of SFED and can be coupled with any simplest scheduling discipline like FCFS first in first served). FABA has many objectives like
- It allocates fair bandwidth amongst flows.
- It can avoid congestion by early detection and notification,
- It has low implementation complexity.
- Easy extension to provide differentiated services.
FABA deals with both adaptive and non-adaptive traffic while providing incentive for flows to incorporate end-to end congestion control. It uses a rate control based mechanism to achieve fairness amongst flows at a router. [9] As in random early detection (RED), congestion is detected early and notified to the source.
Table.1. Strength and Weakness of AQM Algorisms.
|
Algorithm |
Strength |
Weakness |
||||||
|
RED |
|
|
||||||
|
FRED |
|
|
||||||
|
CHOKE |
without any state information. |
|
||||||
|
BLUE |
|
|
||||||
|
SFED |
|
|
||||||
|
FABA |
|
|
||||||
6. Conclusion: In this paper we have state the term AQM and its algorithms. We have highlighted some of queue length based and queue based algorithm with its strength and weakness.
References:
[1] husna zainol abidin , yuslinda wati mohamad yusof,saiful izwan suliman,” network using fairness bandwidth allocation. “october 2008.
[2] richelle adams, “active queue management: a survey”, ieee communications surveys & tutorials, vol. 15, no. 3, third quarter 2013
[3] c.dhivya1, e.george dharma prakash raj2,” survey on load based aqm algorithms”, vol.1.issue.2.;2013
[4],Ningning Hu, Liu Ren (liuren@cs.cmu.edu) Jichuan Chang, “Evaluation of Queue Management Algorithms”, Course Project Report for 15-744 Computer Networks
[5] dive et al.. “Classification and Performance of AQM-Based Schemes for Congestion Avoidance” (IJCSIS) International Journal of Computer Science and Information Security,Vol. 8, No. 1, 2010
[6] CHOKE,a statless queue management scheme for approximating bandwidth allocation.
[7] BLUE: A New Class of Active Queue Management Algorithms, Shiny Department of EECS zNetwork Systems Department University of Michigan IBM T.J. Watson Research Center
[8]Wu-chang Fengy Dilip D. Kandlurz Debanjan y Sahaz Kang G.”SFED: A Rate Control Based Active Queue Management”. IBM India Research Laboratory, New Delhi, India Block 1, Indian Institute of Technology,
[9]Abhinav Kamra a,1, Huzur Saran a, Sandeep Sen a, Rajeev Shorey.” Fair adaptive bandwidth allocation: a rate control based active queue management discipline”. Department of Computer Science and Engineering, Indian Institute of Technology, New Delhi, India. July 2003
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


DMCA / Removal Request
If you are the original writer of this essay and no longer wish to have your work published on UKEssays.com then please click the following link to email our support team:
Request essay removal