Overview of Distributed Computer Systems
Info: 7993 words (32 pages) Dissertation
Published: 26th Aug 2021
Tagged: Information Systems
Table of Contents
2.1 Distributed System Architectures.
2.3 Integrated file management systems.
2.4 Distributed integrated systems.
3. Hiding distribution in distributed systems.
3.3 Information storage mechanisms in distributed systems.
4. Distributed operating systems.
4.2 Mobile configuration agents.
5. Security in distributed systems.
5.2 Discretionary Access Control.
5.3 Security in networked environments.
6. Distributed databases and data stores.
6.2 Consistency and Fault Tolerance.
7. Communication in distributed systems.
7.1 Protocols in Communication.
7.3.3 Message Oriented Communication
7.4 Broadcast Protocols for distributed systems.
7.4.2 The Trans and Total broadcast protocol.
8. Distributed File Systems (DFS)
8.1 Design decisions in Distributed File Systems
8.1.5 Remote Access and Caching
8.1.6 Stateless / state-full Server
1. Introduction
In computer science, “distributed systems” is an important subject area. A distributed computer system is made up with set of interconnected computers through a common communication channel. This communication channel facilitates for the connected computers to exchange information. So, this maintains the interconnectivity of the distributed system. The computers of distribution system could be spread in large geographic area sometimes one computer is located in one continent and another computer can be located in another continent.
Main drive for the introduction and evolvement of distributed systems is that high availability (Minimal downtime) and reliability, computing power and hardware resources (CPU, memory etc) are superior compared to standalone computers. Properties such as constancy, security, fault tolerance, are mainly considered when designing distributed systems. Since a distributed system may expand to millions of nodes from several number of nodes adoptability and scalability should also be focused on. Performance of distributed systems is affected by variables which are associated with the media that is used to interconnect node (i.e.- Network). Concepts such as load balancing and redundancy are closely linked to distributed systems depending on the objectives of the system.
In this report we have summarized information gathered through our literature review on “Distributed Systems”. We mainly targeted on important areas of distributed systems namely distributed system architectures, distributed operating systems, security, distributed databases, communication protocols, distributed file systems.
2. System architectures
There are two basic categories of computer system architectures i.e. centralized architecture and distributed system architecture. Centralized systems have important advantages such as, easy maintenance, High reliability in computation and they provide strong interface to the system.
However, there are key drawbacks in centralized systems. Centralized systems are highly sensitive for the failures. When one component fails in a centralized system whole system will fail. When an upgrade or a modification is going on the entire system needs to be shut down. It is difficult to handle high load with centralized systems as they have very limited memory and computational power. Comparatively the cost of the centralized systems is very high. To cope with all these cons in centralized systems the distributed system architecture was introduced few decades ago.
2.1 Distributed System Architectures
A distributed system can be considered as a set of computers or workstations and servers connected using a common communication channel [1]. This communication medium and nodes connected to the communication medium collectively build up a local area network (LAN). The users of the distributed systems can simultaneously consume the resources of their own work stations and the resource provided by the remote workstations attached to the distributed systems.
There are key advantages and in distributed systems. Distributed systems are providing heterogeneous computing environment. The nodes attached to the distributed system can provide vide verity of functionalities and also, they have different features as well. Distributed systems provide high availability when one node fails that can be detached from the system without affecting to other component of the system and also new component can be introduced to the system without completely stop the whole system. These systems are facilitating for parallel execution of processes.
Distributed systems have their own drawbacks such as lack of shared memory [1] for information sharing and difficulties in system management due the physical distribution of workstations in the system it is important to manage the security and authorization of users [1].
Distributed systems can be divided into three main categories [1] client-server systems, integrated file management systems and integrated distributed systems [1]. However modern distributed systems are collections of features belong to all three categories of architectures.
2.2 Client-server systems
The concept of client-server systems was initiated by the researchers of Xerox-parc [2]. Server provides well defined set of services to the client through the web. Client and the server communicates over HTTP. Server provides an interface which defines services. Clients access services according the interface. Most of the modern operating system kernels are using this model [1]. Not only web based system but modern operating systems kernels are also using this architecture.
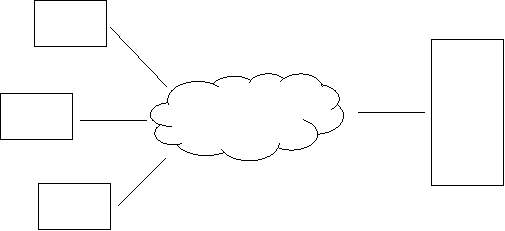
Figure 1: Client server architecture.
2.3 Integrated file management systems
The client server architecture does not enough for the transparent access of the remote files as the client needs to know the exact server which hosts the file.
To overcome these issues an abstraction of single file system was introduced.
2.4 Distributed integrated systems
In a distributed integrated system distribution management functionality are directly bound the system architecture. The distribution management functionalities such as process or virtual memory management, object naming is provided by a distributed kernel of the distributed system [1]. In each site of the distributed system a copy of a kernel is located. These distributed kernels are working together collectively to provide the functionalities of the distributed system.
3. Hiding distribution in distributed systems
According to the distributed system definition by Tanenbaum and van Rensesse [11]. Transparency is a key concept. Even though the distributed systems consist with multiple processors the system user should see it as a “virtual uniprocessor”. He should not see multiple processors in action within the system. The transparency in distributed systems is achieved in many ways. The authors of the paper [1] “Hiding Distribution in Distributed Systems” have described four major approaches of implementing the transparency in distributed systems. Those approaches are communication, file system integration, information storage and fault tolerance.
3.1 Communication mechanisms
In the distributed system architecture, the communication between the interconnected nodes is essential. The communication mechanisms in modern distributed systems can be categorized into three broad categories as message passing, port mechanism and remote procedure calls.
3.1.1 Message passing
For the synchronization and communication between process inside a distributed system message passing mechanism can be used. In the message passing mechanism a physical copy of a message is passed to a process from another process. In a distributed system environment when explicit message passing mechanism is used the programmer needs to know the exact name and the location of the process which he needs to send the message. This make difficult to implement process migration since process location is not transparent. As a solution for this problem the port communication model can be used.
3.1.2 Port mechanism
The port mechanism can be used to separate process management from communications [4]. Ports are acting as mailboxes, with this mechanism messages are directed to these mail boxes. This mechanism separates the port identification from the location where the process runs. And also this facilitate for the migration strategies.
3.1.3 Remote procedure calls
The remote procedure call or RPC is a modification of the procedure call mechanism. The only difference in RPC is the callee and the caller are located in different physical locations. The callee is a server and the caller is the client. Typically, callee and caller processes are running in two different locations.
In the RPC mechanism, the request parameters and results are passed using the message passing techniques. This synchronize the caller to wait the callee’s results [3].
3.2 File system integration
To maintain the transparency in a distributed system the transparency of file access is critically important. File location transparency, file naming transparency and file migration transparency are difficult to implement.
3.2.1 Naming transparency
The ideal naming transparency mechanism is implemented in the Newscale connection (NC) systems, to implement this UNIX naming trees are combined together to build a single naming structure [1].
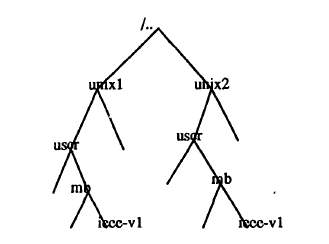
Figure 2: Connection of two UNIX file systems [1]
In the NC system, new additional layer of software is introduced to in between the user application and the UNIX kernel. The main responsibility of this NC layer is to distinguish system calls which needs to be redirected to the other system and accept system calls coming from another system.
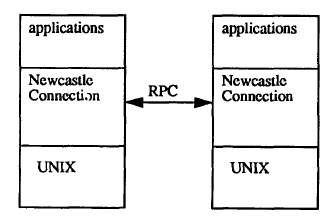
Figure 3: NC layer implementation [1].
3.2.2 Location transparency
For the location transparency, the object internal name should be independent from the objects physical location. In the Apollo system [12] a unique identifier (UID) is used to as the object internal name. This identifier is unique for the whole system. The UID consists of two fields, creation time stamp and the node ID. The object UID is used to access corresponding objects [1]. Hint manager keeps hints of the object location. First the object locating algorithm tries to find the object in local system and if object cannot be find in the local system the algorithm gets help of hint manger to locate the object.
3.3 Information storage mechanisms in distributed systems
In a distributed system files can be accessed using two mechanisms. Multi-level store memory and single level store memory.
The multilevel addressing model uses two different addressing modes. One is to address data stored in user address space and the other one is to access permanent objects or files stored on disk.
In single level address model, a single address is used. All memory references are logical references to objects.
3.3.1 Multilevel storage
To address permanent objects like files which are stored in multilevel store memory buffers are used. So when input/output operation happens information will be transferred from disk to buffer and buffer to disk.
3.3.2 Single Level storage
To access information in both main memory and the disks virtual addressing is used [3]. The virtual addressing mode enables users to access information in transparent manner. The single level storage mechanism can be used to provide shared memory abstraction.
4. Distributed operating systems
Authors of the paper [12] are presenting a distributed operating system named 2K. This operating system addresses major issues in distributed systems such as resource management, dynamic adaptability and configuration of component based distributed applications [12]. In the following section we will describe selected few important features of the 2K system model.
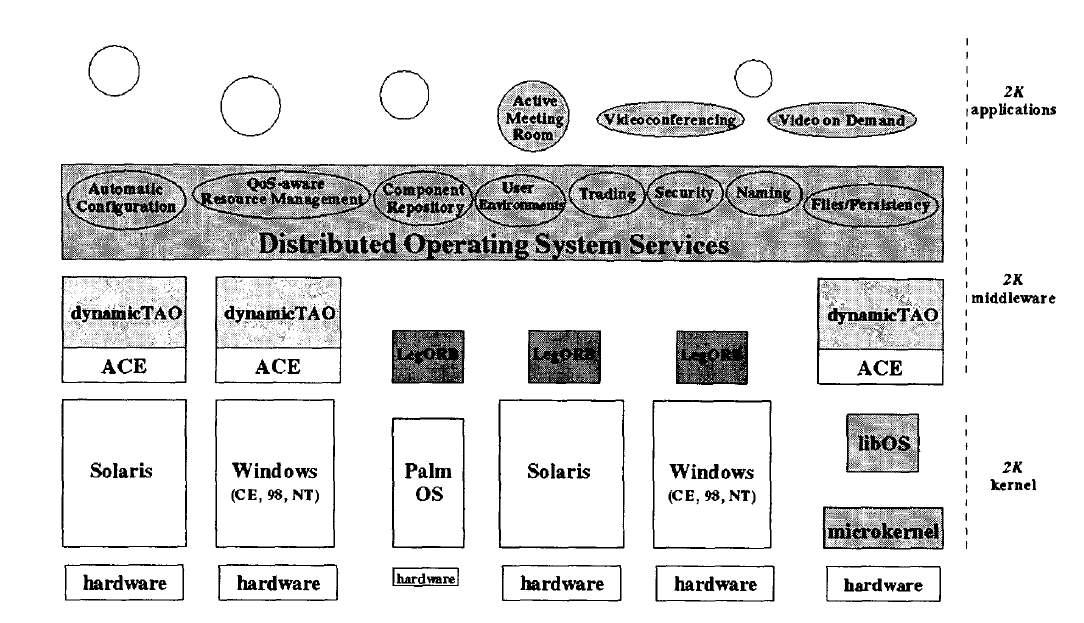
Figure 4: Overall 2K system architecture [12].
4.1 Dynamic Dependencies
2K uses the concept of CORBA object to encapsulate the distributed hardware in the system and it uses CORBA services to encapsulate the distributed services. 2K system has component repository. When one component is requested it fetches that component from the component repository and then the component code will be loaded dynamically in to the 2K runtime. 2K system builds the runtime representation of component dependencies using the prerequisite specifications. COBA objects named as “ComponentConfigurators” are used to build these representations [12].
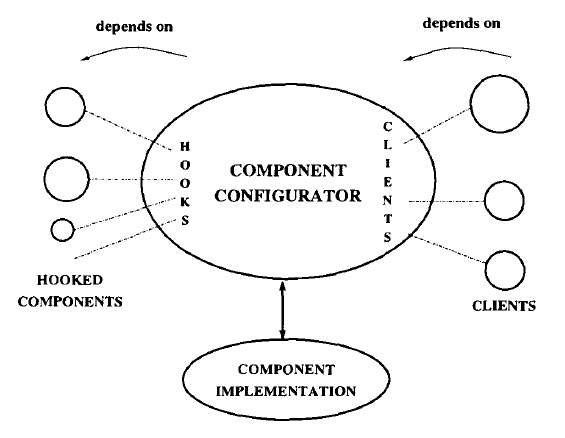
Figure 4: Component dependencies in 2K system [12].
4.2 Mobile configuration agents
2K system uses mobile push based mobile agent implementation to fetch components from the component repository. These mobile agents consist of command to load configurations. By using pull based and push based configuration loading mechanism 2K system provides more flexible infrastructure.
4.3 Dynamic security
Dynamic security is another important feature in 2K system. CORBA interfaces are used as restrictions for 2K services. In 2K prototype Cherubim security framework [13] is used to support dynamic security policies. The security policies of the 2K system can be changed based on the situation.
In the 2K system the security configurations can be change dynamically. This supports for lot of applications to run on top of the 2K system architecture.
5. Security in distributed systems
Security is one of the major aspect of distributed systems. It is critically important as distributed systems are accessible and share information through network medium. If such system does not meet robust access control policy, it can cause for information leakage. The authors of the paper Security in distributed systems [3] are describing three major access control policies with regard to distributed systems. These access control policies are mandatory access control, discretionary access control. In addition to these security control policies security in network environment is also critically important [3].
5.1 Mandatory Access Control
Mandatory access control or MAC is an access control mechanism where the operating system controls the access on object or target. Typically, subject can be an object or thread. MAC is controlled by a security policy administrator. The other users do not have any privileges to override the policy. They cannot issue access to files. MAC allows policy administrators to implement security policies for whole organization [3]. Under MAC users except administrative users cannot override or modify this policy, either accidentally or intentionally. This allows security administrators to define a central policy that is guaranteed (in principle) to be enforced for all users.
5.2 Discretionary Access Control
Discretionary Access Control or DAC is an access control policy where access to objects are restricted based on the subjects or groups where those objects belong [3]. The control of access is discretionary because a subject with a certain access permission is capable of passing the permission to any other subject. With DAC, we can transfer subject among each other.
5.3 Security in networked environments
Distributed systems use networks as a communication medium. Network of a distributed system also needs to be secured. The network can be in physically in physically protected closed environment or an unprotected open environment.
5.3.1 Labeling
Multi-level of information needs to be set across the network. Messages which are sent through the network needs to be labeled. These labels should include the security level. The integrity of labels must be ensured. When the communication is happening though an open network the integrity of labels cannot be guaranteed. Therefore, a mechanism like Crypto Sealing needs to be used
5.3.2 Encryption
When data communication happens across an open network data encryption is essential for the protection. This encryption can be performed at the link or packet level. Multi-level data requires the use of data encryption equipment that meet COMSEC requirements [3].
5.3.3 Kernel authentication
In a networked environment, it is essential to have a kernel level authentication. Typically distributed operating systems are functioning across broadcast networks therefore public key system can be used for the mutual authentication.
6. Distributed databases and data stores
A distributed data store is a data storage mechanism where it store data in more than one node in a replicated fashion. This either can be a distributed database which replicates data in multiple instances or a peer to peer accessible computer nodes which can store user information.
Distributed databases are usually referred as non-relational databases which has performance of querying capabilities and available in number of distributed nodes which also can be replicated in to multiple instances. While some distributed databases provides rich querying capabilities some databases are limited to key-value store semantics. Google’s BigTable is a distributed database which has more features than distributed file system or a peer to peer network. Amazone’s Dyanamo DB and Windows Azure Storage are more example for distributed databases.
6.1 Transaction Handling
Distributed transaction handling occurs when two or more network hosts are involved. Transaction manager and transaction resources are the main two entities as far as distributed transactions are concerned. Transaction manager is responsible for managing and creating global transactions involved with transaction resources. Distributed transactions also have ACID (Atomicity, Consistency, Isolation, and Durability) properties like any other transactions. Various implementations of distributed databases employ different mechanism to handle transactions. Spanner: Google’s Globally-Distributed Database [6] uses timestamp based technique to manage distributed transactions.
6.2 Consistency and Fault Tolerance
Synchronizing every node in the network including cache if available with the latest modifications to data is crucial for distributed data storages. This also can be described as the consistency. Ability of a system to function in the event of a partial failure can be named as fault tolerance. Even though the system continue to function, overall performance might get affected. Fault tolerance is mainly achieved by replication and check points. Main idea of replication is to access data in an absence of a node due to a failure from another node. Preserving stable state of the system in a stable storage is named as check pointing. In a case of failure system it is restored into its previous stable state which saves useful information.
6.3 Performance
Performance of a distributed system is mainly rely on communication latency and I/O latency. Different systems have implemented many techniques to improve aforementioned latency points in the favor of the performance of the system. In-memory cache mechanisms plays a major role in distributed data store’s performance which has been described next.
6.4 Caching
Distributed data stores and databases heavily rely on in memory cache data same like traditional concept of locale cache. In a distributed data store or a database cache may can span up to many servers which are remotely located. Main memory has become cheaper enabling caching a viable solution for gaining performance. TAO’s caching layer provides intermediary between client and databases providing good read performance [5].
6.5 Workload Balancing
Workload balancing is another importance task carried out by distributed database systems. Load balancing is a way of distributing load units across multiple nodes based on a threshold value. By load balancing it is expected to make every node busy equally to finish the work approximately same time. It maximizes resource utilization with higher throughput. I also enable the extensibility and incremental growth.
7. Communication in distributed systems
A distributed system and a uniprocessor system can be differentiated mainly by the inter process communication. Uniprocessor systems mainly relies on shared memory when it comes to inter process communication. Example for that is producer-consumer problem. At the absence of shared memory distributed systems relies on message passing. No shared memory inter process communication happens in distributed systems.
7.1 Protocols in Communication
Protocols can be categorized in to layers defined in OSI reference model
- Lower-level protocols: Define protocols in Physical, Data link and Network layers
- Transport protocols: Transfer messages between clients, including breaking them
In to packets, controlling low (TCP & connectionless UDP).
- High-level protocols: Define protocols in Session, Presentation and Application layers
7.2 Types of communication
- Persistent or transient
- Asynchronous or synchronous
- Client/server
- Discrete or streaming
7.3 Remote Procedure Call
Remote Procedure Call (RPC) is a function or subroutine call happening between different computers in a network without having to understand the network’s details. RPC are normally happened to request a service from one program which is running on a different computer.
7.3.1 Asynchronous RPCs
Asynchronous RPC model provides capabilities to maintain multiple outstanding RPC calls within a single threaded client by separating return values. In the traditional synchronous RPC calls a client is blocked in a remote procedure call until the call returns which is a limitation of synchronous remote procedure calls.
7.3.2 Reliable RPCs
Define handling mechanisms for remote procedure calls failures.
- Client cannot locate server
- Client request is lost
- Server crashes
- Server response is lost
- Client crashes
7.3.3 Message Oriented Communication
Inter processes communication can be facilitated by message oriented communication which correspondent to events. Inter process communication happens regarding events. Event data is delivered via messages. There are main two categories for message oriented communication. Those are synchronous or asynchronous communication and transient or persistent communication. In the synchronous communication both sender and receiver have to be engaged in exchange simultaneously. Asynchronous communication does not need both receiver to be active while the message is being sent. They are loosely coupled. Transient or persistent nature of message oriented communication determines the amount of time messages are stored. Transient communication allow messages to be alive only when both processes are being executing. On the other hand persistence communication stores the messages until the recipient receives it.
7.4 Broadcast Protocols for distributed systems
7.4.1 Introduction
Typical local area network can intend to use broadcast communication. Sometimes processors normally selects broadcast communication to use as a communication medium among processors. Broadcasted messages may or may not be received by all other processors. Broadcast messages are assumed to satisfy the requirements of the Trans and Total protocols described below [7].
7.4.2 The Trans and Total broadcast protocol
The Trans protocol, which ensures that every message broadcast or received by any working processor and it is an efficient protocol. The Total protocol, which with high probability promptly places a total order on broadcast messages, ensuring that even in the presence of faults all working processors agree on exactly the same sequence of broadcast messages [7].
8. Distributed File Systems (DFS)
Distributed File Systems (DFS) enables users to operate with files which are physically located in different machines / remote disks. (User usually sees files in remote systems as those are in local disk). Since file does stored in specific client machine, this enables multiple users to access the file. Multiple clients who access same file should be managed and consistency and reliability must be assured. And Homogeneity of hardware and software is not required to operate with DFS.
In addition to above main purposes, DFS has advantages such as improved reliability (Information is replicated over multiple servers hence files are accessible and information is not lost even if one or more servers are down) and diskless workstations. (DFS enables clients to operate with files without a disk which is concept / model existed earlier. Even though diskless workstations are used today, concept of file access from diskless work stations is depreciated. [10] Discusses on implementation of diskless workstations which are connected to file servers using local area network)
Most popular Distributed File Systems are as follows and their behaviors of operation and design decisions are discussed.
- NFS (Network File System)
- AFS (Andrew File System)
8.1 Design decisions in Distributed File Systems
- How to name files / transparency (How mounting occurs)
- Remote Access / Caching decisions
- Stateless / state-full Server
8.1.1 Naming and Transparency
Location transparency – Name of the file should not indicate the physical location of the file. So the user sees all files are stored in his computer’s disk and can access files without the knowledge of physical location of the file.
Location Independence – If the location of the file is changed, whether the name of the file needs to be changed. Usually DFSs does not have the property of location independence since the name of the file is used by the file system to find the physical location (or locations if the file is scattered) and changing the physical location will result in the change of the name of the file. (e.g: -NFS)
8.1.2 Absolute naming
File name consist of the server name and path actual file. In this approach user can distinguish local files and remote files. Also this eliminates the property of fault tolerance since the file name contains the server name (name of the remote machine where the file resides) and if that particular machine is inaccessible due to an issue (a crash or a network problem), and then the file is not accessible by the client. Hence, basic requirements of a DFS cannot be achieved using absolute naming method.
8.1.3 Mount points
Mapping between name used to identify the file used by client and physical sever (and path) where file resides is maintained. (Such mapping information is maintained in a specific directory and mappings are known as mount points). This mechanism has location transparency and location independence (applied after a rebooting of client) (e.g; – Network File System)
8.1.4 Global Namespace
All client use the same file name (unlike NFS where clients can use different names for the same remote file). Client retrieves the file names structure from server. (e.g:- Andrew File System)
8.1.5 Remote Access and Caching
In remote access method, RPCs (Remote Control Procedures) are used to read and write data to remote file. (Hence, file or a part of the file is not kept in client memory or disk).
In caching method, copy of block of the file or whole file is maintained at client side. Reading and writing is done from / to the local copy in cache in the local machine. Caching model is performance friendly since reads and writes are done using the cached copy in local machine and not affected by network latencies (in RPC model, network latency is always affects the performance). Also for the server caching model is performance friendly compared to RPC model since in RPC, server has to perform reads and writes according to the client requests.
8.1.6 Stateless / state-full Server
In stateless servers, server does not keep track of clients connected to read/write files and their connectivity statuses. Therefore when client issues RPC to read/write operations and server reads from / writes to the relevant file block and reply is sent to the client. For each read / write request, server needs to open the relevant file.
In state-full servers, server keeps track of opened files from clients. Therefore concurrent updates to same file from different clients should be detected and handled by the server. And upon a restart of the server (after a crash), server needs to rebuild the state (or inform the clients so that clients can re-apply and resend the changes done locally)
8.2 NFS (Network File System)
NFS is introduced by Sun Micro Systems and widely used in UNIX distributed systems. Earlier versions of NFS (up to version 3), stateless protocols were used and in version 4. In NFS, each machine can act as a server and a client.
UNIX systems which uses NFS uses an interface layer called Virtual File system (VFS) which provides an abstraction to the user so that user doesn’t see a differences between local files and remote files. When a client issues and I/O operation through System Call interface, Virtual File system checks whether the issued call is intended for a local file or a remote file. If it is intended to a local file, call will be redirected to the local file system (UNIX file system). Else, the call is redirected to NFS module, and NFS module will issue a RPC to server to perform actual I/O operation and server will send the reply.
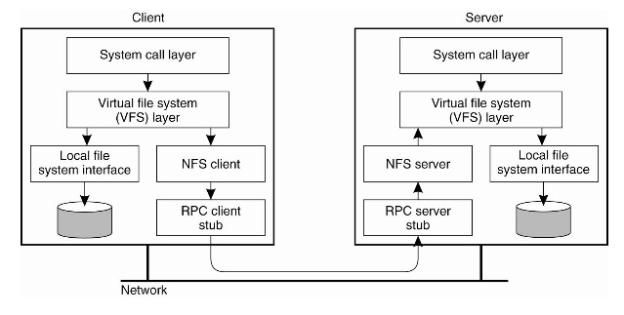
Figure 5 : RPC handling in Network File System Architecture
8.2.1 Caching in NFS
To improve performance, NFS maintains an in-memory local cache in client where recently accessed disk blocks are saved. This improves the performance of the distributed file system, but adds additional overheads such as managing cache inconsistencies. Also if the client is crashed before sending changes to the remotes server, their updates in cache will be lost.
8.2.2 Cache inconsistency
Cache inconsistency occurs when multiple clients operate with the same file. Some particular clients write to the file and server applies changes sent by these clients. Since other clients operate with their local copies of file or file blocks in cache, these clients could be referring to invalid / outdated data.
To overcome this issue, client synchronizing with server should occur in a controlled manner. Following two methods are used to minimize cache inconsistency.
Client initiated consistency – Client has the responsibility of checking for inconstancies. (Checking can be done periodically or for each and every disk block access)
Server initiated consistency – When a particular client changes the file, server pushes the changes to clients using a callback mechanism (e.g :- Andrew File Systems)
8.2.3 Cache update models
Write though
In this model, as soon as an update is applied to the cache, update is pushed to the server. This increases the network traffic and affected by network latency which results in lower performance. Performance advantage is yield only when read calls are issued. (Read is done from cache)
Delayed write
Updates are applied to the cache, but not pushed to the server. Changes are pushed to server upon an event such as file closure. Writing process is not affected from network latency since process continues after writing to the cache. Drawback of the model is that if the client crashes before pushing the update to the server, changes will be lost. (In DFS’s such as Andrew File System, caching is done at disk level. Therefore this drawback is not applicable for such file systems)
8.3 Andrew File System (AFS)
Andrew file system is developed mainly focusing on scalability (Initial version targeted over 5000 subscribers). When developing this model, assumptions / observations such as “file read operations are done frequently than write operations” and “most of the files are small in size when compared the distribution” are made. (AFS does not yield significant advantages when above assumptions are invalid for a particular system).
Also AFS is superior to other distributed file systems such as NFS in terms of performance and security. After the initial implementation of AFS (initial implementation was done as a part of university distributed file system), based on this model is OpenAFS and IBM-Transarc distributed files systems were developed as commercial products.
AFS uses a state-full server where information about open file connection from each client is kept track in the server. (In AFS server is called as “Vice” and client is called as “Venus”). Also AFS uses disk local cache to keep a complete copy of the remote file for reading and writing. (In NFS, in memory cache is used to copy file blocks). This feature enables client to work on the local cache one the file is copied to the local disk without using communication mechanisms request data from server. All the reads and writes are done from / to local cache (local disk I/O overhead is still there). As a result of this, performance of AFS is better than other traditional distributed file systems. If the client does read operations only, when compared to RPC based DFS, AFS promise to provide superior performance. (But AFS requires client to copy the entire file to local disk before operating with the file. If the file size is considerably high, this initial copying could introduce significant delay whereas other traditional file systems such as NFS does not have such as issue since they are operated using RPCs and only disk blocks needs to be copied to the client cache)
Since, there are not RPC’s used, server has minimum interrupts from clients which facilitates the scalability. (Server can handle higher number of clients since load of operations at server side is reduced due to local disk caching).
Also this model enables client to work without the existence of sever since client operates with the local copy and if the server crashes, server needs to rebuild the state by loading client connection details accordingly. Also, if the client crashes before sending the update file to server (or changes are not applied at server side due to network disruptions), all the clients changes will be lost. And client can restart and continue to work on the cached copy saved in disk before the crash if the cache is still valid. (Cache validation request is sent to server by client upon a restart of client)
Client’s local changes are applied to the server when client closes the file. After applying these changes, server sends the updated copy to all other clients through a callback mechanism known as callback promise and other clients can update the file accordingly. But simultaneous updates from different clients are usually not handled successfully. (Update from the last client is stored in server overriding the changes of other clients). Due to this property, AFS is not recommended for database files.
In AFS, security is also considered as an important aspect. AFS uses Kerberos protocol to authenticate clients and clients are checked against access control lists (Hence privilege levels can be maintained to directories (usually in AFS, Access controls are not defined for files)).
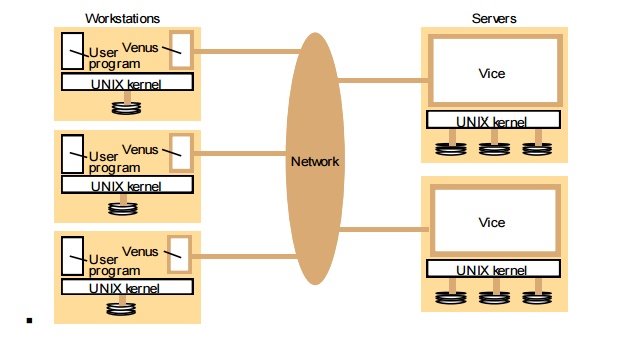
Figure 6 : Andrew File System Architecture
In addition to aforementioned distributed file systems, there are several systems which are in use today. (e.g:- Google File System (GFS), Hardoop Distributed File system (HDFS))
9. Conclusion
This report is mainly intended to discuss major topics in distributed systems covering system architectures, distributed operating systems, security aspects, distributed data stores and databases, communication mechanisms in distributed systems and distributed file systems. Components of distributed systems are located in a network in which communication happen via message passing. By looking at the various aspects of distributed systems, significant characteristics are concurrency control, communication and independent failure handling of components.
Distributed system architectures address key drawbacks of centralized systems such as high sensitivity to failures, lack of scalability. However distributed systems have inherent drawbacks such as complexity and communication overhead due to absence of shared memory. This report also covers main three type of distributed systems client-server systems, integrated file management systems and integrated distributed systems.
Communication among different computational hosts in a network is important aspect when studying distributed systems. The communication mechanisms in modern distributed systems can be categorized into three broad categories as message passing, port mechanism and remote procedure calls. Those are explained in “Hiding distribution in distributed systems” more details.
An architecture for distributed operating system named 2K is explained under “Distributed operating systems”. This operating system addresses major issues in distributed systems such as resource management, dynamic adaptability and configuration of component based distributed applications.
Different aspects of distributed system security is explained in “Security in distributed systems”. It has covered topics such as mandatory access control, discretionary access control, security in networked environments, labeling, encryption and kernel authentication.
Various aspects of distributed databases and data stores are covered in “Distributed databases and data stores”. The difference between distributed databases and data stores with examples along with characteristics such as transaction handling, consistency and fault tolerance, performance, caching and workload balancing also explained.
Distributed system communication protocols and file systems are covered in more details in last 2 sections of the report. Different types of RPCs such as asynchronous RPCs and reliable RPCs are introduced and introduction to Message Oriented Communication is also given. Most popular distributed file systems such as NFS (Network File System) and AFS(Andrew File System) are introduced along with the characteristics.
10. References
[1] M. Banatre, “Hiding distribution in distributed systems,” [1991 Proceedings] 13th International Conference on Software Engineering, Austin, TX, 1991, pp. 189-196.
[2] A.D. Birrell and B.J. Nelson, “Implementing Remote Procedure Call,” in ACM Transactions on Computer Systems, 1984, pp. 39-59.
[3] R. M. Wong, “Issues in secure distributed operating system design,” Digest of Papers. COMPCON Spring 89. Thirty-Fourth IEEE Computer Society International Conference: Intellectual Leverage, San Francisco, CA, USA, 1989, pp. 338-341.
[4] A. Tevanian and R.F. Rashid, MACH A Basis for Future UNIX Development. Technical Report CMU-CS-87-139, Department of Computer Science, Carnegie-Mellon University, Pittsburgh, June 1987.
[5] N. Bronson et al, “TAO: Facebook’s Distributed Data Store for the Social Graph,” in USENIX Annu. Technical Conf., 2013, pp. 49-60.
[6] J. C. Corbett et al, “Spanner: Google’s Globally-Distributed Database,” in the Proceedings of OSDI., 2012, pp. 1-14.
[7] P. M. Melliar-Smith, L. E. Moser and V. Agrawala, “Broadcast protocols for distributed systems,” in IEEE Transactions on Parallel and Distributed Systems, vol. 1, no. 1, pp. 17-25, Jan 1990.doi: 10.1109/71.80121
[8] S. J. Mullender, A. S. Tanenbaum, “The Design of a Capability-Based Distributed Operating System”. Comput J 1986; 29 (4): 289-299. doi: 10.1093/comjnl/29.4.289
[9] David R. Cheriton, Willy Zwaenepoel, “The Distributed V Kernel and its Performance for Diskless Workstations” in Proc. 9th ACM Symposium on Operating Systems Principles, 1983, pp. 129-140
[10] A. Tanenbaum ct R. Van Re-. Distributcd Operating Systcms. ACM Computing Surveys, 17(4):419-470, Dccembcr 1985.
[11] PJ. Leach, P.H. Lcvinc, B.P. Douros, J.A.Hamilton, DL. Nelson, et B.L. Stumpf. Thc architecture of an Integrated Local Network. IEEE Journal on Sclectcd Areas in Communications, 1(5):842–857, November 1983.
[12] F. Kon, R. H. Campbell, M. D. Mickunas, K. Nahrstedt and F. J. Ballesteros, “2K: a distributed operating system for dynamic heterogeneous environments,” Proceedings the Ninth International Symposium on High-Performance Distributed Computing, Pittsburgh, PA, 2000, pp. 201-208.
[13] Dynamic Agent-based Security Architecture for Mobile Computers. In Proceedings of
The Second International Conference on Parallel and Distributed Computing and Networks (PDCN‘98), pages 29 1-299, Australia, December 1998.
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Information Systems"
Information Systems relates to systems that allow people and businesses to handle and use data in a multitude of ways. Information Systems can assist you in processing and filtering data, and can be used in many different environments.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: