Big Data Security and Privacy Issues – A Survey
Info: 11746 words (47 pages) Dissertation
Published: 24th Feb 2022
Tagged: Cyber Security
1. Introduction
Expeditious development of Internet technology has connected people across world. Nowadays gathering people virtually is more realistic than physically. This virtual connection of people has led to emergence of Cyber Society. Daily interaction of people in cyber society generates enormous amount of data known as “Big Data”.
Big Data are high-volume, high-velocity and high-variety information, which demands new forms of processing to enhance decision making, insight discovery and process optimization [1]. Data set can be called “Big Data”, if capturing, analysis, storing, filtering and visualization of data is difficult for traditional or current Technologies [2]. In general, “Big Data” technology includes process of collecting, storing, and inferring valuable insights from data as shown in Fig. 1.1.
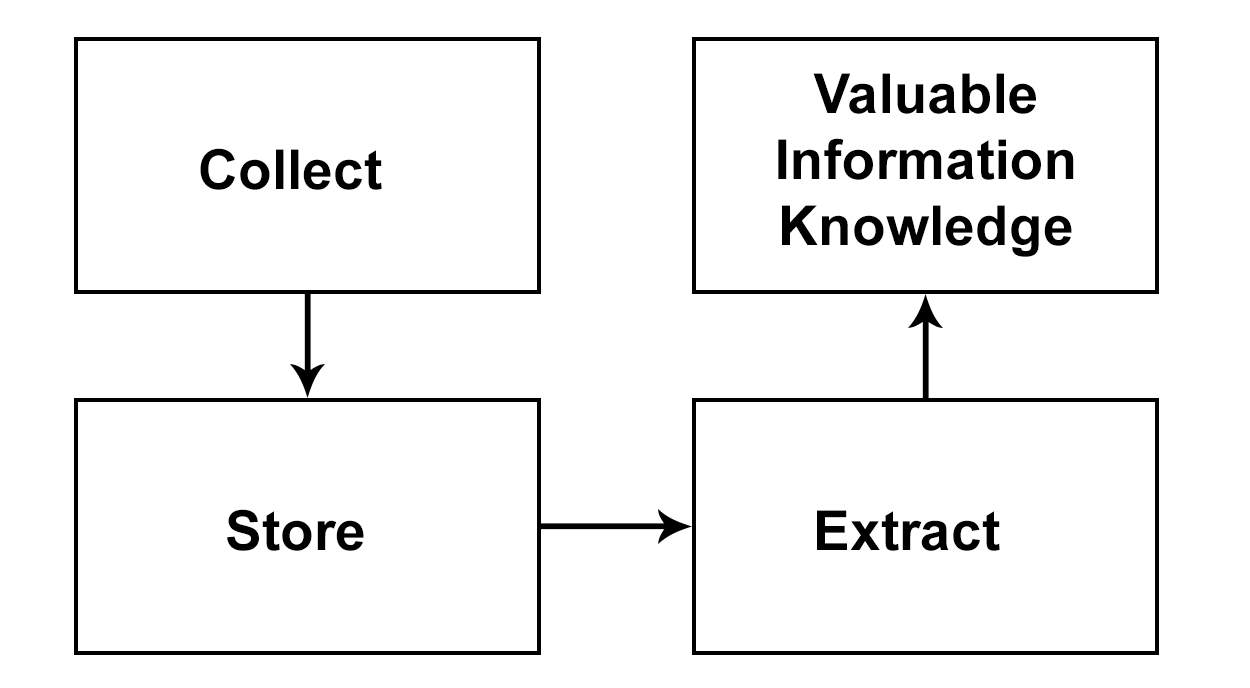
Fig. 1.1 Big Data technology process [4]
It is predicted that data will increase from 130 exabyte in 2005 to 40,000 exabyte in 2020 [5]. “Big Data” provides advantages for defining needs, revenue generation, decision strategy, better services and identifying new trends.
With the healthy pool of advantages “Big Data” also created various serious security and privacy issues to data. Big Data has different characteristics from traditional data. Traditional security mechanism are not able to protect Big Data. Hence, security and privacy issues need to be readdressed with context of Big Data.
Major security and privacy issues of Big Data include confidentiality, integrity, availability, monitoring and auditing, key management and data privacy. Confidentiality can be achieved by AAA– Authentication, Authorization and Access control. Integrity can be maintained using data provenance, data trustworthiness, data loss and data deduplication.
Big Data have various data sources and large amount of generated data. To reduce the cost and improvement in performance, cloud is widely used as outsourced storage. Access control is required to protect outsourced data to preserve privacy and security. Attribute Based Encryption is widely used to protect outsourced data. Attribute Based Encryption is used as either Key-Policy Attribute Based Encryption and Cipher Text Policy Attribute Based Encryption.
1.1 Outline of Report
The rest of the report is organized as follows:
In chapter 2, we discuss the literature survey in which we have discussed the issues or challenges for Big Data followed by survey of security and privacy issues of Big Data. Furthermore, we have studied various access control scheme and analysed them. We have also explained offline attribute guessing attack.
In chapter 3, we have proposed access control scheme.
In chapter 4, implementation of public key generation, Master secret key and generation of attribute bloom filter are shown.
In chapter 5, we have explained Electronic Health record (EHR) system followed by action plan in chapter 6.
Conclusion and future work have explained in chapter 7.
2. Literature Survey
In our Literature survey, we have started from Big Data characteristics followed by issues or challenges of Big Data such as Heterogeneity, Data Life Cycle Management, Data Processing, Scalability, Data Security – Privacy and Data visualization. We have carried out survey on Security and Privacy issues of Big Data such as confidentiality, integrity, availability, key management, monitoring and auditing. Furthermore, we have studied various Big Data access control schemes to enhance our literature survey. Overview of security and privacy issues, parametric comparison of literature survey and analysis of various Attribute Based Encryption are also carried out in brief literature survey. Furthermore, we have identified shortcoming of current access control scheme against offline attribute guessing attack. Preliminaries such as Linear Secret Sharing Scheme and Bloom Filter are covered under literature survey to enhance the quality of proposed system.
2.1 Big Data Characteristics
Big Data has different characteristics and nature compare to traditional data sets. HACE theorem and 5 V’s of Big Data can define big Data characteristics.
2.1.1 HACE Theorem
According to HACE (Heterogeneous, Autonomous, Complex and Evolving) theorem discussed in [6], consider the situation where, blind men are trying to examine huge elephant that we can be treated as “Big Data”.
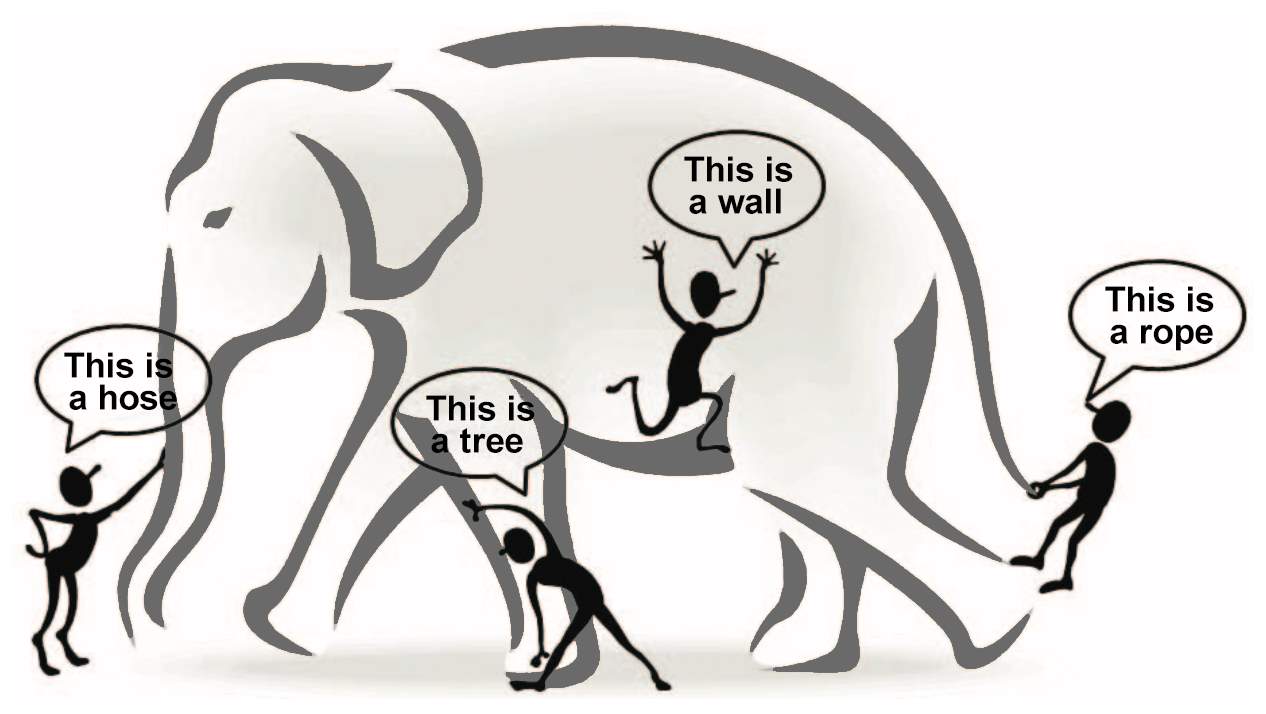
Fig. 2.1 HACE Theorem [3]
It is not surprising that each blind man feels elephant like a rope, a hose or a wall as shown in Fig. 2 because of each of them has limited information of local region. The expected outcome from each blind man is picture of the parts information he collects during examination process. Furthermore, situation will become worst if we consider elephant as rapidly growing size (volume) and constantly changing pose (velocity). It is also possible that one blind man share his feeling to other blind man, which will result into biased, unreliable and inaccurate information sharing. Exploring “Big Data” in this scenario is identical to combining information from various heterogeneous sources (blind men) that indicate variety of data.
2.1.2 5V’s of Big Data
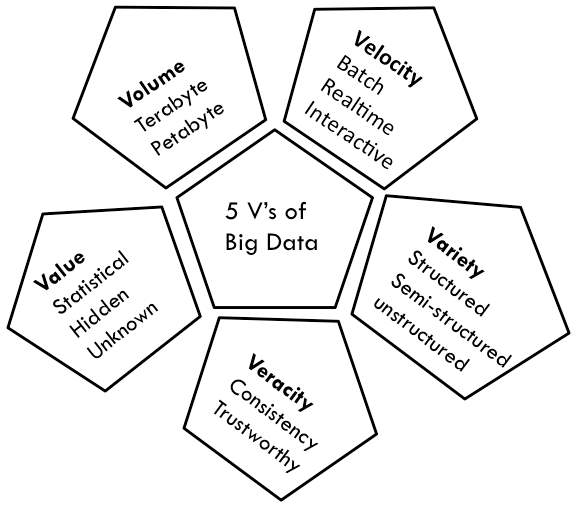
Fig. 2.2 5V’s of Big Data [2]
Big Data can be characterized by 5Vs – volume, velocity, variety, veracity, and value as in Fig. 3. Volume relates with enormous growing amount of data from different sources. Speed of data indicates velocity of Big Data that defines types of processing needed for Big Data such as batch processing, real-time processing and interactive processing.
Heterogeneity of data sources avail variety of data in different formats such as structured data, semi-structured data and unstructured data. Consistency and trustworthiness denotes veracity of Big Data. Value indicates inference of new insights from available datasets. Among 5vs, volume, veracity and variety are security related characteristics [7].
2.2 Issues/Challenges of Big Data
The adoption of Big Data causes high expectation of gleaning new value intuition from available data sources. It also brings new challenges such as heterogeneity, data life cycle management, data processing, scalability, security and privacy and data visualization that are summarized as follows:
2.2.1 Heterogeneity
Variety, one of the significant characteristics of Big Data, emerges from virtually unlimited distributed data sources [8]. Data variety includes numerical data, textual data, images, video, sound, and sensor data [9]. Handling of heterogeneous data types and sources are the key future challenges because of difficulty in the conversion of structured and semi structured data into uniform structure data [10]. Big Data alsoincludes metadata. Metadata displays information about data such as location, time, and type of image taken by smartphone. Handling of different metadata formats is also challenging issue [11].
2.2.2 Data Life Cycle Management
In Big Data, data life cycle doesn’t end with completion of analysis. Values inferred from datasets, may be utilized by different users with different perspective. For example, patient’s health record ends its life cycle from patient’s perspective once his/her recovery is done but same health record may still be valuable from doctor’s or researcher’s perspective to infer meaningful information [9][13]. Hence, judging/defining life cycle of data needs to be re-addressed.
2.2.3 Data Processing
Data collected from various sources may include redundant data that needs to be pre-processed before actual analysis. Redundant data can be processed for further research with the help of data re-utilization, data re-organization and data exhaust [13]. Data exhaust is may be resulting from incorrect data generated during data for improving mining results.
2.2.4 Scalability
Scalability is directly related to Volume. Scalability is capability of the storage to handle increasing amount of data in relevant manner [8]. The word Big is in the name “Big Data” requires handling of large and increasing volume of data that demands further improvement.
2.2.5 Security and Privacy
Typical security solutions are not more likely capable to protect Big Data because ofdifferent characteristics. Hence, widely adoption of Big Data in various day-to-day activities causes security issues that need to be readdressed. Furthermore, outsourced sensitive information creates privacy issues. Privacy of data needs to be maintained during either data acquisition or data storage of personal sensitive data [3][8-9][13].
2.2.6 Data Visualization
Better visualization improves decision making from data. Data visualization forms user-friendly man-machine interface for presentation of data. Variety and velocity make correlation of data more complex. To provide clear view, visualization of complex data is needed. Effective data visualization methods should be addressed for prominent value inference [3][9].
2.3 Security and Privacy Issues in Big Data
Appearance of any risk denotes the security and privacy loopholes. Dynamic nature of new security and privacy risk makes data security and privacy protection challenging. Data is most crucial part in Big Data. Hence, assuring data security and privacy during either data transition or data storage is the core need of Big Data.
Generally, data is preferred as secure, when CIA (Confidentiality, Integrity, Availability) is satisfied [14]. PAIN (Privacy, Authentication, Integrity, Non-repudiation) is another measure to ensure data security and privacy benchmark [15]. Data may contain Personally Identifiable Information (PII). Security applied to PII, ensures privacy. Classical security mechanisms/solutions are deficient with respect to Big Data to ensure security and privacy. Hence, favouring the literature study, main security and privacy issues of Big Data are confidentiality, integrity, availability, monitoring and auditing, key management and data privacy that are expatiated in consequence of literature.
2.3.1 Confidentiality
Confidentiality relates to applying some rules and restrictions to data against illegal disclosure. Limiting access to the data and various cryptographic techniques are widely used to sustain confidentiality.
One of following way is used to ensure confidentiality in typical security mechanism [15]:
- Data is encrypted during transition and stored as plaintext.
- Authentication is used on stored plain text data to grant access.
- Data is encrypted when stored and decrypted when in use.
Confidentiality is assured using Authentication, Authorization and Access control (AAA) [15]. Authentication is referred to as user identity establishment. Authorization is used to grant resource access to the authenticated user. Access control refers to enforcing resource access permission for authorized use to authenticated users.
Various encryption techniques for confidentiality protection of data, confidentiality protection for searching, sharing, numerical comparison, query and confidentiality protection using hardware are elaborated in [14].
2.3.1.1 Authorization
Authorization is related to check either access to particular resource is allowed to user or not. Authorization determines about the resources that any authenticated user can or cannot have access to resources [15].
2.3.1.2 Authentication
Jeong et el. [16] propose efficient authentication scheme for seamless data. Property based protocol for mobile users with initialization process, user movement process and authentication process is explored for assurance of confidentiality.
2.3.1.3 Access Control
Access control is related to granting access to particular data. Authenticated user need to be authorized to use particular data or file. Author in [15] has mentioned various research directions for access control such as access control policy merging, access control policy enforcement for Big Data stores and heterogeneous multimedia data, automation for granting permission and authorization for Big Data.
Efficient and fine-grained access control scheme is elaborated in [17] using Cipher Text Policy Attribute Based Encryption (CPABE) scheme. Access control is carried out in four steps: system setup, key generation, data encryption and data decryption. Attribute bloom filter is used to hide plain text access policy to preserve the leakage of privacy. However, this scheme suffers from offline attribute guessing attack.
2.3.2 Integrity
Data integrity provides protection against altering of data by an unauthorized user in an unauthorized manner. Hardware errors, user errors, software errors or intruders are main reasons for data integrity issues [15]. Salami attacks, data diddling attacks, trust relationship attacks, man in the middle attack, and session hijacking attacks are most well-known attacks on data integrity [18].
Xu et el. [14] has expounded various approaches such as data integrity protection with digital signature, Big Data query integrity protection, data storage integrity protection and integrity protection with help of hardware. Integrity protection with digital signature is further explained with homomorphic signature and MAC. Query integrity protection can be achieved with the help of dual encryption, extra records and integrity preserving query in dynamic environment.
Puthal et el. [23] has proposed approach for real time security verification of streaming data. Dynamic key length is used to provide end-to-end security and integrity. Proposed approach of consists of system setup, handshaking, rekeying and security verification. However, development of strategy for moving target for Internet of Things (IoT) is mentioned as open research direction.
Integrity can be maintained using data provenance, data trustworthiness, data loss and data deduplication.
2.3.2.1 Data Provenance
Data provenance is related to information about creation process as well as sources of data through which it is transformed. It is the process to check all states of data from initial state to current state. Debugging, security and trust models are various applications of data provenance [11-12]. Without data provenance information, user never come to know from where the data came, what and which transformations have applied on data. This affects the value of data [19].
2.3.2.2 Data Trustworthiness
Decision-making is well known application area for Big Data. However, data trustworthiness affects accurate analysis of decisions, predictions, and actions. Lack of protection from malicious users and error free data make data trustworthiness difficult. Data correlation and source correlation techniques need to be explored for assurance of data trustworthiness [3].
2.3.2.3 Data Loss
Data theft or data leakage and data loss also affect data integrity. Data, once copied, it could be tampered and released to create confusion and integrity issues [21]. Data Loss Prevention (DLP) techniques are widely used for avoidance of data loss.
To address the issue of data leakage in hadoop, Gao et el. [20] propose haddle framework. This framework is composed of automatic analytical methods and on-demand data collection methods. However, better mechanism for log collection of hadoop to improve performance is mentioned as open research direction.
2.3.2.4 Data Deduplication
Data deduplication is a data compression technique that eliminates duplicate copies of data fromdata storage. Furthermore, it improves utilization of available storage and reduces the number of bytes that must be sent. Data deduplication can be classified into different types such as based on granularity, location and ownership. Based on granularity, it is classified in file level deduplication and block level deduplication. Based on location, it is divided in Client side deduplication and server side deduplication. Data duplication based on ownership is classified as one user deduplication and cross user deduplication [22].
2.3.3 Availability
Data availability ensures that data must be available for use when authorized users want to use. High Availability (HA) systems are the solution for satisfying data availability [15]. Backup servers, replication and alternative communication links are widely used to design HA system. However, emergence of cloud computing has narrow downed issues of data availability for Big Data due to high uptime of cloud. Although Denial of Service (DoS) attack, Distributed Denial of Service (DDoS) attack and SYN flood attack are known attacks to breach data availability that need revised solutions [18].
2.3.4 Key Management
Key Management and key sharing between users, servers and data centres are emerging security issues for Big Data. Wen et el. [22] has explained various approaches for key management such as secret sharing, server aided approach, and encryption with signature. In key management with Ramp secret sharing scheme (RSSS), users don’t need to maintain any key on their own but instead of they have to share secrets among multiple servers. Key can be reconstructed using minimum defined number of secrets as in (Fig. 4) using RSSS.
2.3.5 Monitoring and Auditing
Auditing and monitoring provides active security to detect abnormal activity or intrusion from Big Data network security system. Monitoring of suspicious and non-suspicious data behaviour is essential in Big Data. With enormous amount of data, conventional approach of blocking data on server and verifying data on client for data auditing is not feasible for Big Data.
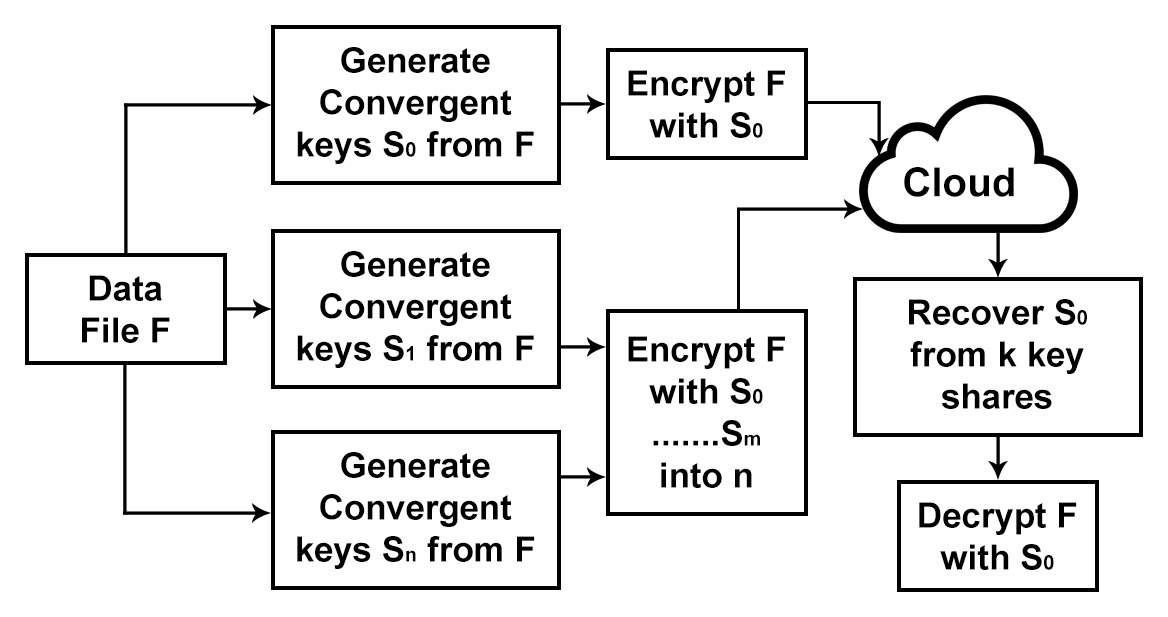
Fig. 2.3 Key management with RSSS [22]
Kim et el. [24] has discussed abnormal behavior detection technique based on cyber targeted attack response system to detect abnormal behavior proactively. Dynamic nature of Big Data makes auditing complicated. However, healthy attempt to audit dynamic data storage using novel Merkle Hash Tree (MHT) based public auditing approach is elaborated in [25]. Proposed auditing method solves the communication overhead problem and authentication problem.
2.3.6 Data Privacy
Recently we capture high amount of traceable data that were never taken and stored in the past. Data privacy issues crop up as a result of this traceable data that was anonymous. Data privacy intents to assure Personally Identifiable Information (PII) should not be shared without informed assent to related data owner. Even after sharing, use of PII is often restrained to specific reason. For example, to develop effective treatment or medicine, study of patient’s medical record is essential. Hence, PII of patient must be anonymized to protect privacy.
A methodological approach to ensure security of NoSQL data with privacy protection is elaborated in [26]. Authors have proposed approach to encrypt data of NoSQL database. The proposed approach consists of pre-treatment phase, identification of sensitive attribute phase, sensitive data fragmentation phase and data reconstruction phase.
Rahman et el. [27] has discussed generic framework PriGen for privacy preservation of healthcare data in cloud. PriGen works based on data partitioning mechanism that analyzes and separates sensitive data. Key management, implementation of framework and deployment of framework on real time healthcare application are mentioned as future research directions.
Xu et el. [14] has reviewed privacy protection approaches such as privacy protection using k-anonymity, l-diversity and t-closeness. Furthermore, Big Data privacy protection using differential privacy and privacy protection on user side is also elucidated. The core idea of differential privacy includes transformation of original data or addition of noise or extra records. Privacy protection at user side includes effective way to control copying, viewing, altering or executing work or task on data at user side.
Table 2.1 Big Data Security and Privacy Issues in Literature
| Issues | [3] | [11] | [14] | [15] | [16] | [17] | [20] | [22] | [23] | [25] | [27] |
| Confidentiality | – | – | Yes | Yes | – | – | – | – | – | – | – |
| Authentication | – | – | – | Yes | Yes | – | – | – | Yes | Yes | – |
| Authorization | – | – | – | Yes | – | – | – | – | – | – | – |
| Access Control | – | – | – | Yes | – | Yes | – | – | – | – | – |
| Integrity | – | Yes | Yes | Yes | – | – | Yes | – | Yes | – | – |
| Data provenance | – | Yes | – | – | – | – | – | – | – | – | – |
| Data Trustworthiness | Yes | – | – | – | – | – | – | – | – | – | – |
| Data leakage / Data loss | – | – | – | – | – | – | Yes | – | – | – | – |
| Data Deduplication | – | – | – | – | – | – | – | Yes | – | – | – |
| Availability | – | – | – | Yes | – | – | – | – | – | – | – |
| Monitoring and Auditing | – | – | – | – | – | – | – | – | – | Yes | – |
| Key management | – | – | – | – | – | – | – | Yes | – | – | – |
| Data Privacy | – | – | Yes | Yes | Yes | Yes | – | – | – | – | Yes |
2.4 Big Data Access Control
Big Data generally have large amount of volume with a mixture of various data formats, and high velocity. To reduce the cost and achieve high performance, outsourcing of data to cloud is most convincing. Some access mechanism is needed to add to the outsourced data to the cloud to protect privacy and maintain security of data.
As shown in Fig. 2.4, various data sources generate enormous amount of data which is captured by data acquisition systems such as online transaction, batch processing or any other complex event data processing. Generated data is most likely outsourced to the cloud. Data consumers or users use data from cloud, which is uploaded by data owner. Some access control mechanism is needed to be apply at outsourced data to avoid unauthorized use of outsourced data.
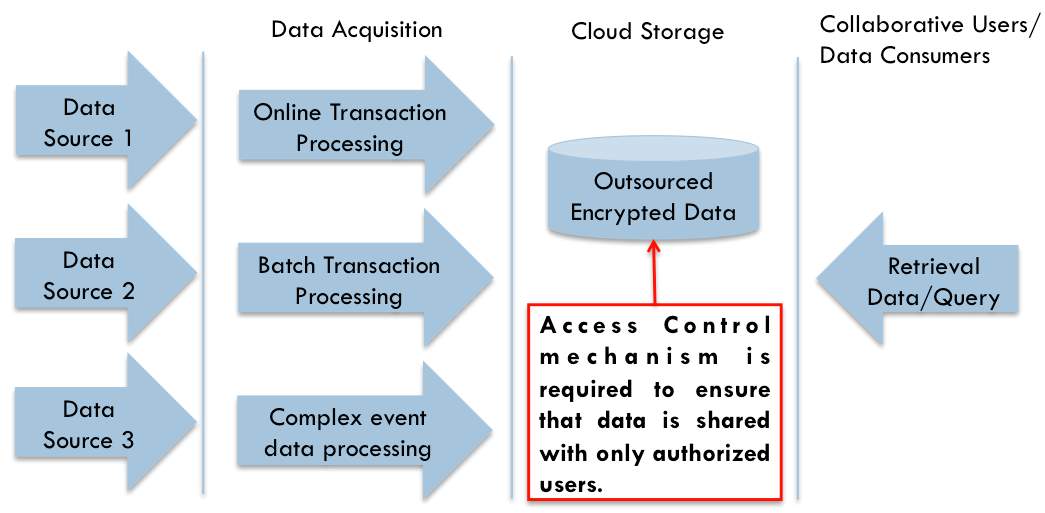
Fig. 2.4 Big Data Access Control [28]
Attribute-based encryption (ABE) is widely used as encryption technique for outsourced cloud data access control. Features such as lightweight encryption, which supports both, access policy enforcement and encryption makes attribute based encryption as first choice for encryption and access control. It achieves flexible one-to-many encryption instead of one-to-one. Various Attribute Based Encryption techniques are proposed such as Key-Policy Attribute-Based Encryption (KP-ABE), Cipher Text Attribute-Based Encryption (CP-ABE), Cipher Text Weighted Attribute-Based Encryption (CP-WABE), Key-Policy Weighted Attribute-Based Encryption (KP-WABE) and Cipher Text Attribute Based Encryption with Privacy preserving Policy.
2.4.1 Key-Policy Attribute-Based Encryption (KP-ABE)
Goyal et el. [29] has proposed a key-policy attribute-based (KP-ABE) scheme. This scheme uses a set of attributes to describe the encrypted data and builds an access policy in user’s private key. If attributes of the encrypted data can satisfy the access structure in user’s private key, a user can obtain the message through decrypt algorithm. In this scheme, there are four algorithms to be executed: Setup, KeyGen, Encrypt, and Decrypt.
In this scheme, the user’s private key is associated with access structure, and the encrypted data with a set of descriptive attributes can be used to be corresponding to the access structure of the user’s private key. Since access control is built in user’s private key, the attributes of the encrypted data satisfy access structure so to let a data user decrypt the encrypted data. However, the access control right is owned by user’s private key, and some people just obtaining this key can let him decrypt data. It means the user’s private key can choose the encrypted data which is satisfied, but the encrypted data cannot choose who can decrypt this data. To overcome this, the Cipher Text Policy Attribute Based Encryption is proposed.
2.4.2 Cipher Text Policy Attribute-Based Encryption (CP-ABE)
Bethencourt et el. [30] has proposed a Cipher Text Policy Attribute-Based scheme, and the access policy in the encrypted data (cipher text). The access control method of this scheme is similar to the key policy attribute-based encryption. In key policy attribute-based encryption, the access policy is in user’s private key, but the access policy is switched to the encrypted data in cipher text policy attribute-based encryption. A set of descriptive attributes are associated with the user’s private key, and the access policy is built in the encrypted data. The access structure of the encrypted data is corresponding to the user’s private key with a set of descriptive attributes. If a set of attributes in user’s private key satisfies the access structure of the encrypted data, the data user can decrypt the encrypted data; if it cannot, the data user cannot obtain the message. There are five algorithms in this scheme, Setup(), KeyGen(), Encrypt(), Delegate(), Decrypt(). The Delegate algorithm is in addition more than above schemes, and it can input user’s private key and regenerate the new one with another attribute which are in a set of attributes of the original user’s private key. And this key is equal to the key generated from the authority.
The CP-ABE builds the access structure in the encrypted data to choose the corresponding user’s private key to decipher data. It improves the disadvantage of KP-ABE that the encrypted data cannot choose who can decrypt. It can support the access control in the real environment. In addition, the user’s private key is in this scheme, a combination of a set of attributes, so a user only use this set of attributes to satisfy the access structure in the encrypted data. However, limitation of this scheme is access policy is attached with cipher text as plain text which leaks privacy of the users and also any one can come to know either he or she can able to decrypt or not by just seeing cipher text.

Fig. 2.5 Cipher Text using CPABE
Figure 2.4 shows example of cipher text using CP-ABE, from which anyone can get idea about cipher text by seeing access policy. “physio” is access policy in above figure, so any one can get information that above cipher text is related to “physio”.
2.4.3 Cipher Text Policy Weighted Attribute-Based Encryption (CP-WABE)
CP-WABE is a generalized form of traditional CP-ABE. In some applications, the importance of each attribute has a different weight and may not be treated as identical. For example, suppose that a head of department wishes to encrypt a document concerning a 40-year-old lecturer in the department of commerce. The access structure {“lecturer” AND “CS department” AND “Age 40”} is used to encrypt the document. A user with the private key must have all three attributes in order to decrypt the document. If the categories were expanded into professor, assistant professor, and associate professor and added to the access structure, the structure becomes too complex, even when not all the possibilities are taken into account. To avoid this, a CP-WABE scheme was proposed by Liu et al. [32] in which attributes was weighted according to their importance in the access control system. The data owner can then encrypt the data with a certain set of attributes with a weighted structure. In the decryption process the set of weighted attributes with the cipher text must match the weighted access structure. For instance, the levels “professor”, “assistant professor”, and “associate professor” can be given weights of “professor (1)”, “professor (2)”, and “professor (3)”, respectively. If the access structure is {“professor (1)” AND “CS department”}, everyone who is a professor in the CS department can decrypt the document. Both professor and associate professor cannot decrypt if the access structure is {“professor (2)” AND “CS department”} because professor (1) has a higher weighting. CP-WABE provides fine-grain access and is mainly used in distribution systems.
2.4.4 Key Policy Weighted Attribute-Based Encryption (KP-WABE)
In the KP-WABE scheme [31], data receiver’s private key has certain kinds of weighted access structure. In order to decrypt the message successfully, the cipher text with a set of weighted attribute must satisfy the weighted access structure. KP-WABE works same as CP-WABE with only difference of association of attributes and access policy to cipher text and private key of user respectively.
However, all above mentioned schemes deal with the access policy as plaintext, so privacy is not preserved from access policy. To overcome above issue, authors in [17] have proposed cipher text attribute based encryption with privacy preserving policy.
2.4.5 Cipher Text Policy Attribute Based Encryption with Privacy Preserving Policy
Authors in [17] have proposed encryption scheme which use CP-ABE and access policy is not used as plain text. Instead authors have used Linear Secret Sharing Scheme (LSSS) for access policy and Attribute Bloom Filter (ABF) to hide attribute. Proposed scheme includes data owner, data consumer, cloud and attribute authority. encrypt data by providing access policy and upload cipher text with access matrix and bloom filter. Data consumer must pass allocated attributes and secret key to decrypt. Attribute authority maintain key and attribute allocation. Proposed scheme includes four steps such as setup, keygen, encryption and decryption. Encryption and decryption steps have sub steps ABFBUILD and ABFQUERY for bloom filter generation and query. Shortcoming of this proposed scheme is it is not able to cope with “offline attribute guessing attack”, so attacker can continue try to decrypt cipher text by guessing attributes of other or attribute which is not owned by self.
Table 2.2 Comparison of access control schemes
| Approach | Privacy Preservation in Access Policy | Association of Attributes | Association of Access policy | Type of Access Structure | Centralized / hybrid |
| Key-Policy ABE [29] | No | With cipher text | With key | Non-weighted | Centralized |
| Cipher Text-Policy ABE [30] | No | With key | With cipher text | Non-weighted | Centralized |
| Cipher Text Policy ABE with Privacy Preserving Policy [17] | Yes | With key | With Cipher text using Bloom filter | Linear Secret Sharing Scheme | Centralized |
| Cipher text – Policy weighted ABE [32] | No | With key | With cipher text | Weighted | Centralized |
| Key-Policy weighted ABE [31] | No | With cipher text | With key | Weighted | Centralized |
2.5 Offline Attribute Guessing Attack
In Cipher Text Attribute Based Encryption with Privacy Preserving Policy, LSSS scheme and Bloom Filter is used to avoid privacy leakage of access policy. Data consumer has to download cipher text with bloom filter, access matrix and bloom filter from cloud. Data consumer has to pass set of attributes allocated to self from attribute authority. If data consumer passes attributes, which satisfy the policy defined by data owner, then successful decryption is done.
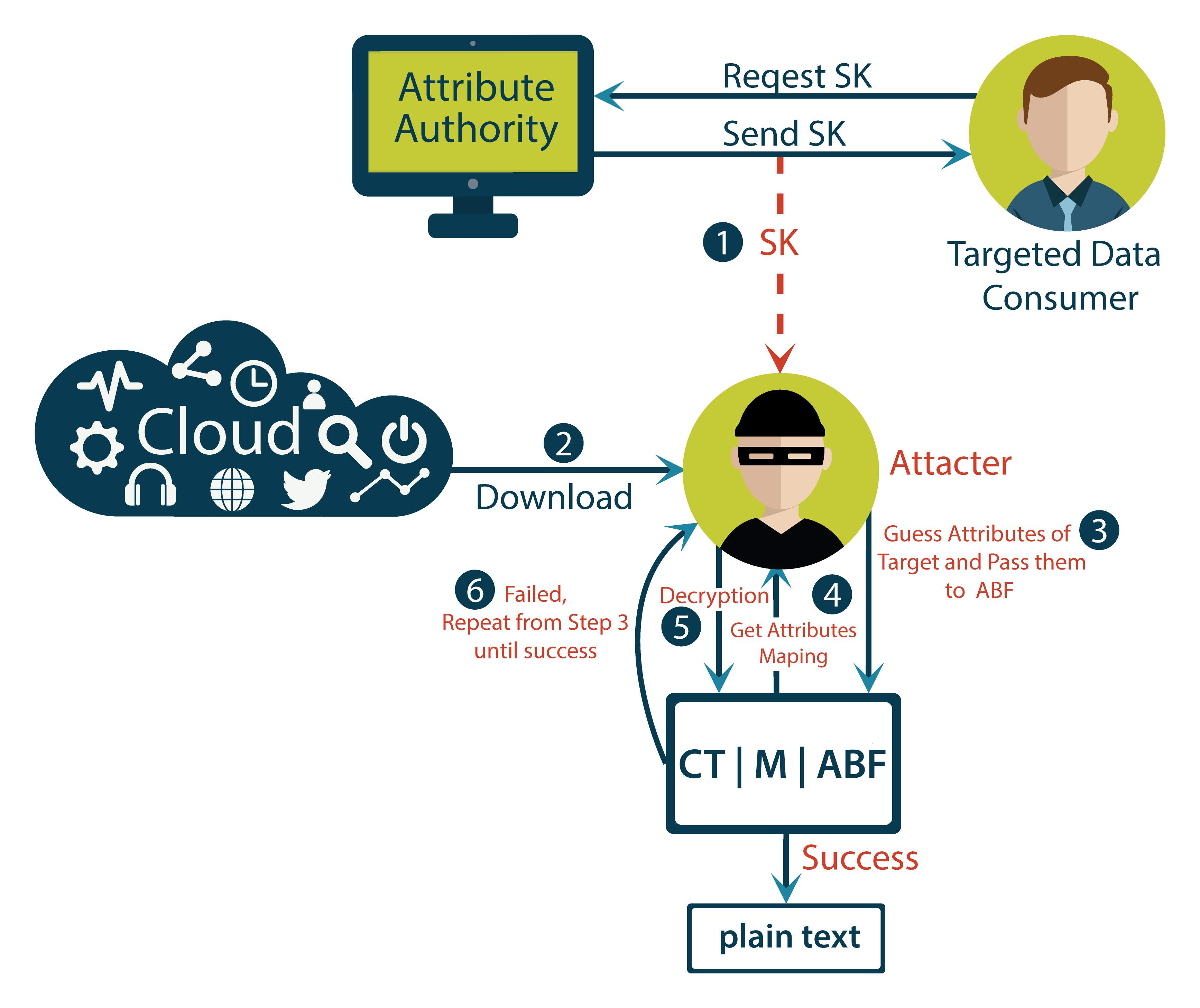
Fig. 2.6 Offline Attribute Guessing Attack Scenario
Fig. 2.6 delineates scenario of “offline attribute guessing attack”. Attribute authority generates the secret key based on attributes allocated to data user. Now if attacker get the secret key of any authenticated user, attacker needs to pass set of attributes allocated to that user for decryption of cipher text. Attacker will guess the attributes and pass guessed attributes to cipher text and bloom filter. Based on passed attributes attacker will get mapping function and new mapping function will be used for decryption.
If attacker is succeeded to guess right set of attributes, then attacker will gain illegal access to the cipher text and get plain text. So, once attacker get secret key of user then attacker can continue guess the attributes and try to decrypt data. This causes the possibility of “offline attribute guessing attack”. Until attacker doesn’t succeed to decrypt cipher text by guessing attributes, there is high possibility of offline attribute guessing attack.
2.6 Linear Secret Sharing Scheme (LSSS)
Secret sharing is also known as secret splitting.It includes distribution of a secret amongst participants. Each of participants has share of the secret. The secret can be reconstructed only when a sufficient number of share which is distributed amongst participants are available. Secret shared with each participant is of no use on his or her own.
Linear Secret Sharing Scheme, shares secret linearly among participants and also have ability to reconstruct [17]. Access policy can be easily converted in LSSS matrix as explained in below example.
Let’s take attribute policy defined by data owner is, (CardiologistSurgeon OR Patient) OR [(Anesthesiologist OR Technician) AND CardiologistHospital].
A = “CardiologistSurgeon”,
B = “Patient”
C = “Anesthesiologist”
D = “Technician”
E = “CardiologistHospital”
(A OR B) OR ((C OR D) AND E ) will be equivalent to above policy. If OR is mentioned by 1 and AND is mentioned by 2 then, above policy can be written as,
(A, B, ((C, D, 1), E, 2), 1), LSSS for this access policy will be as shown in Fig. 2.7
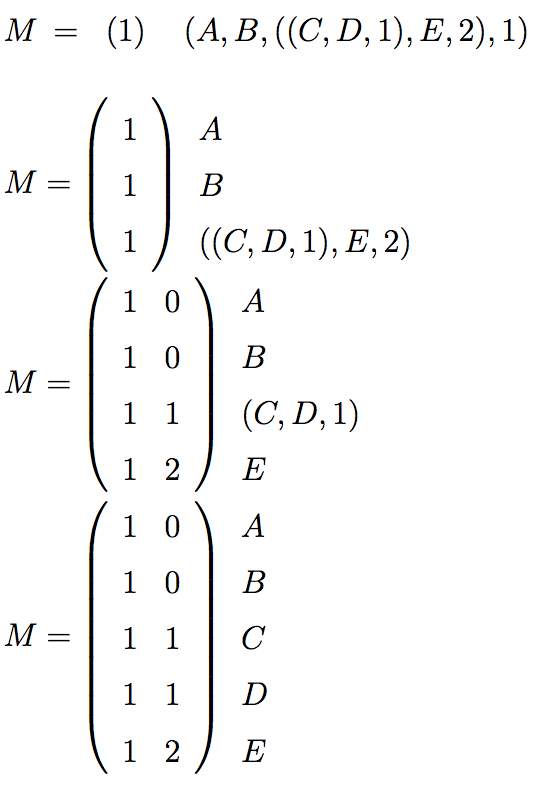
Fig. 2.7 Linear Secret Sharing Scheme [33]
2.7 Bloom Filter
Bloom filter is data structure, which is used to test the membership of the element stored in it [34]. A Bloom Filter is a data structure, which is, depends on probability. It can give an answer whether element exists in a set. Bloom filter can return false positives but never return false negatives. False positive means bloom filter can return yes even though when answer is no [34].
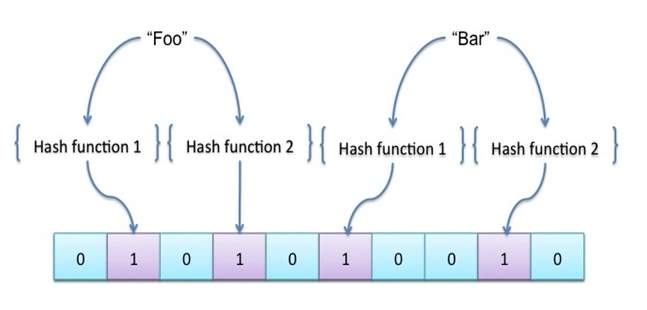
Fig. 2.8 Bloom Filter [34]
Initially bloom filter array is set to value 0. When a new element comes in, it is hashed which will decide which array bit/s need to be set. As shown in Fig. 2.8, “Foo” and “Bar” value of element is hashed first using various hashing function. Based on result of hash function bit is set to 1 for related element. We can query bloom filter about either element is present or not and determine membership of element [34].
3. Proposed Scheme
We have proposed Big Data access control scheme, which give protection against offline attribute guessing attack by querying attribute bloom filter continuously.
3.1 Scheme Overview
Workflow of our proposed access control scheme includes data owner, cloud provider, attribute authority and data consumer/data user as shown in Fig. 3.1
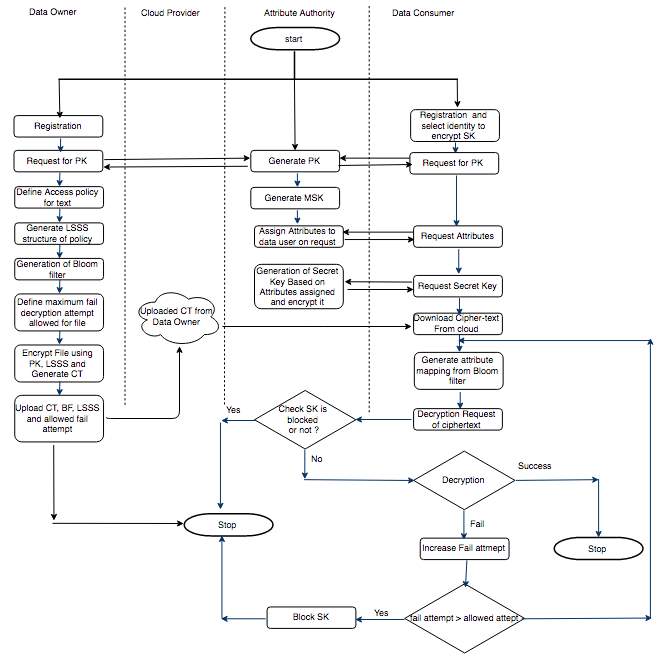
Fig. 3.1 Workflow of Proposed Scheme
3.2 Algorithms of Proposed Scheme

Algorithm 3.1 provides pseudo code for data owner in our proposed scheme.
Begin
| 1. | Registration of data owner with attribute authority. |
| 2. | Request for public key (PK) from attribute authority. |
| 3. | Define attribute access policy for file and convert it into Linear Secret Sharing Scheme (LSSS). |
| 4. | Generate attribute bloom filter for attributes used to define policy in step 2. |
| 5 | Define maximum fail attempts allowed for false attempt of decryption by any data user. |
| 6. | Encrypt file using access policy and upload encrypted file to the cloud provider with bloom filter, access policy and maximum allowed fail attempt. |
End
Algorithm 3.1 Pseudo Code for Data Owner
Initially data owner will register with attribute authority and become authenticated user. Data owner will request for public key to attribute authority, which is used for encryption at later stage. After the equitation of public key, data owner has to define attribute policy or rules, which is used to encrypt file. Attribute policy defines some rules, which is much satisfied by data consumer before decryption. Defined attribute policy is transferred in Linear Secret Sharing Scheme (LSSS). Attribute bloom filter is generated for the attributes used in generation of LSSS. Maximum allowed fail attempt of decryption is decided by data owner, which is followed by encryption of file using attribute policy. Encrypted file is uploaded to cloud provider along with attribute bloom filter, access policy and allowed fail attempt for decryption.
Algorithm 3.2 explains steps for attribute authority. Attribute authority will generate public key and issues to data owner or data consumer on demand. Master secret key (MSK) is used to generate secret key (SK) for data consumer. Attributes will be assigned to data consumer, which is followed by generation of secret key (SK) for particular data consumer. Block status of secret key (SK) is verified by attribute authority on request. Blocking of secret key (SK) is performed if data consumer tries to decrypt file above allowed fail attempt for decryption.

Algorithm. 3.2 provide pseudo code for attribute authority in our proposed scheme.
Begin
| 1. | Generate public key (PK) and issues to data owner or data consumer on request. |
| 2. | Generate master secret key (MSK). |
| 3. | Allocate attributes to data consumer and generate secret key (SK) for particular data consumer based on allocated attribute and encrypt that key. |
| 4. | Check blocking status of secret key (SK) on request. |
| 5 | Blocking of secret key (SK), if maximum allowed fail decryption attempts for file are exceeded by data consumer. |
End
Algorithm 3.2 Pseudo Code for Attribute Authority

Algorithms 3.3 provide pseudo code for data consumer in our proposed scheme.
Begin
| 1. | Registration of data consumer with attribute authority. |
| 2. | Request for public key (PK), attributes and secret key (SK) based on allocated attribute by attribute authority. |
| 3. | Download encrypted file from cloud with attribute bloom filter and access policy. |
| 4. | Pass attributes allocated in step 2, to generate attribute mapping from bloom filter, which is followed by decryption of file using secret key (SK). |
| 5 | Perform decryption based on status of secret key and output of step 4 increase fail attempt count in case of fail decryption attempt. |
End
Algorithms 3.3 Pseudo Code for Data Consumer
Data consumer will be user who wants to access encrypted file, which is uploaded to the cloud by data owner. As per algorithm 3.3, data consumer will register with attribute authority and provide identity to encrypt secret key. Data consumer will request for attributes and secret key (SK). Data consumer will download encrypted file from cloud and pass attributes to generate mapping function from attribute bloom filter. Secret key (SK) is checked for validation and if decryption is not succeeding, then fail attempt is increased. Decrypted file will be generated if attributes of data consumer are satisfying the policy defined by data owner at time of encryption.
Existing scheme is not able to handle offline attribute guessing attack and data consumer can continuously pass attributes of other users or attributes which is not owned by self. Proposed scheme maintains the record for fail attempt and block particular attacker or user with secret key, so that no guessing attempt of attributes will be possible beyond maximum attempt provided by data owner.
Main steps of scheme [17] include steps as setup, keygen, encryption and decryption. Encryption steps have two sub routine as Enc and ABFBuild. Decryption has two sub steps as ABFQuery and Dec.
Setup (1λ): The setup algorithm is run by central authority which inputs security parameter 1λ. It will generate the public PK and master key MSK as output after the Setup algorithm run completely. Public key is generated as
PK =
⟨g, ê
(g, g)α,
ga,
Latt,
Lrownum,
LABF,
h1,
h2,….
hU,
H1( ),
H2( )….
Hk ( ) ⟩. Where, Let G and GT be multiplicative groups of prime order p, and ê:
G × G→ GT be a bilinear map, random element
α, a
∈ Zp*,
h1,
h2….
hU is random element for each attribute,
Lrownum is maximum bit length of row in access matrix,
Latt is maximum bit length of attribute,
LABF is size of Bloom filter. MSK is generated as
gα.
KeyGen (PK, MSK, S): Each data consumer must get authenticated from attribute authority. Attribute authority assigns attribute by evaluating role of data consumer. It will generate SK secret key for data consumer. Secret Key is associated with set of attributes given by attribute authority to data consumer. SK is generated as SK =
⟨K, L,
{ Kx } x∈S,S
⟩. Where K=
g∝ gat,L =
gt, { Kx = hxt} x∈S.
Enc (PK, m, (
M,
ρ): This subroutine of encryption generates cipher text CT using public key, message and access structure of policy. To avoid privacy leakage from cipher text, authors have avoided to upload mapping function
ρand bloom filter is used to hide that. To generate bloom filter ABFBuild subroutine is used. The algorithm first chooses an encryption secret s
∈ Zp*,randomly and then selects a random vector
→V= (s, y2,…,yn), where y2,…,yn are used to share the encryption secret s. For i = 1,…,l, it calculates
λi=
Mi.
→V. CT is generated as CT=
⟨C= mê
(g,g)∝s C’=
gs,{ Ci = gaλi h(i)-s} i=1,…,l ⟩.
ABFBuild (M,
ρ): This steps outputs bloom filter with attributes mapping. ABF is further used for querying the bloom filter and generate mapping function at the time of decryption. Access policy is used to generate attribute bloom filter as shown in Fig 3.2.
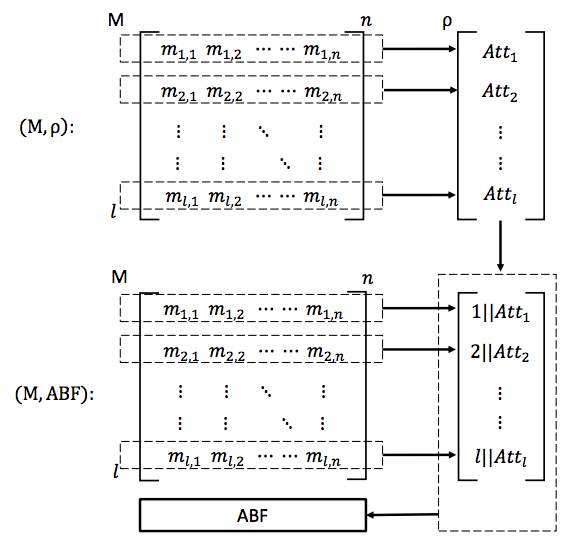
Fig. 3.2 The LSSS Access Policy and Attribute Bloom Filter [17]
ABFQuery (S, ABF, PK): This step is used to generate mapping function
ρ’ from given set of attribute S. This set of attributes S is passed by data used when they want to decrypt.
Thischeck for the presence of each attribute in ABF and then make new mapping function
ρ’.
Dec (SK, CT, (M,
ρ’)): For decryption of cipher text, secret key SK, mapping function
ρ’ and access matrix which are used to generate plain text. If generated mapping function
ρ’ and access matrix M does not satisfy attributes associated with secret key of data user. Cipher Text is decrypted using m = C/ ê
(g, g)αs, where ê
(g, g)αs = ê (C’,K)Πi∈I (ê Ci ,Lê(C’,Kρ’i))ci.
To avoid the offline attribute guessing attack, secret key of user will be encrypted and fail attempt of decryption for particular secret key will be monitored. Data owner can define allowed fail attempt for particular information at time of outsourcing to the cloud.
4. Implementation
We have studied JPBC (Java Pairing Based Cryptography) library [35], which is available on the web. We have implemented Public Key generation (PK) and Master Secret Key Generation (MSK) for proposed scheme. We have also implemented Bloom Filter Generation for attributes.
We have done the experiment of key generation and bloom filter generation on a Macbook Pro with macOS sierra, an Intel Core i5 CPU at 2.5GHz and 8.00 GB 1600 MHz DDR3 RAM. The code uses the java Pairing-Based Cryptography (PBC) in NetBeans 8.2.
Public key generation: We have generated public key for different numbers of attributes. We have taken three cases as attributes numbers as: 5 attributes, 10 attributes and 20 attributes. We have taken result for 10 trials and have taken mean for Average time for public key generation. Fig. 4.1 shows content of generated public key. Table 4.1 shows total time taken for public key generation. Fig 4.2 and Fig 4.3 shows graphical representation of PK generation.
Fig. 4.1 Public Key Content
Table 4.1 Time for Public Key generation
| Trial No. | Time (5 Attributes) (sec.) | Time (10 Attributes) (sec.) | Time (20 Attributes) (sec.) |
| 1 | 1.196 | 1.587 | 2.247 |
| 2 | 1.579 | 1.644 | 1.834 |
| 3 | 1.365 | 1.678 | 1.796 |
| 4 | 1.268 | 1.727 | 1.890 |
| 5 | 1.863 | 1.649 | 1.831 |
| 6 | 1.640 | 1.900 | 1.613 |
| 7 | 1.485 | 1.982 | 1.829 |
| 8 | 1.195 | 1.506 | 1.757 |
| 9 | 1.281 | 1.690 | 1.449 |
| 10 | 1.120 | 1.695 | 1.789 |
| Average | 1.399 | 1.705 | 1.803 |
Master Secret Key Generation: We have generated master secret key (MSK) for different numbers of attributes. We have taken three cases as attributes numbers as: 5 attributes, 10 attributes and 20 attributes. We have taken result for 10 trials and have taken mean for Average time for public key generation. Fig. 4.4 shows content of generated master secret key. Table 4.2 shows total time taken for public key generation. Fig 4.5 and Fig 4.6 shows graphical representation of MSK generation.
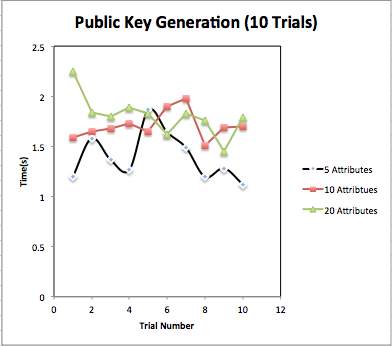
Fig. 4.2 Comparison of Public Key generation for different number of attributes
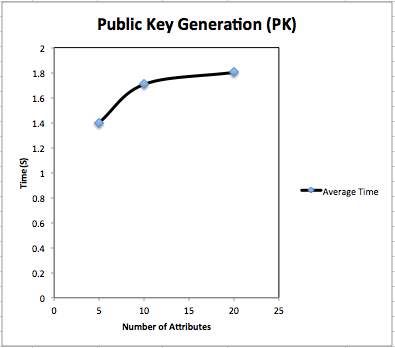
Fig. 4.3 Average time for Public Key generation
Fig. 4.4 Master Secret Key Content
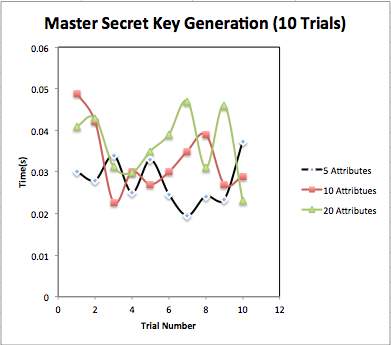
Fig. 4.5 Comparison of Master Secret Key generation for different number of attributes
Table 4.2 Time for Master Secret Key generation
| Trial No. | Time (5 Attributes) (sec.) | Time (10 Attributes) (sec.) | Time (20 Attributes) (sec.) |
| 1 | 0.030 | 0.0489 | 0.0410 |
| 2 | 0.0280 | 0.0420 | 0.0429 |
| 3 | 0.0340 | 0.0227 | 0.0312 |
| 4 | 0.0250 | 0.0300 | 0.0298 |
| 5 | 0.0329 | 0.0270 | 0.0350 |
| 6 | 0.0246 | 0.0300 | 0.0390 |
| 7 | 0.0195 | 0.0350 | 0.0470 |
| 8 | 0.0242 | 0.0390 | 0.0310 |
| 9 | 0.0234 | 0.0270 | 0.0660 |
| 10 | 0.0373 | 0.0290 | 0.0230 |
| Average | 0.0278 | 0.0330 | 0.0365 |

Fig. 4.6 Average time for Master Secret Key generation
Attribute Bloom Filter Generation: We have implemented Bloom filter with attributes in it. Attributes are randomly selected from attribute space which contains attributes {“physio”, “medical”, “Medicare”, “care”, “nursing”, “medicine”, “doctor”, “sanitation”, “Doctor”, “treatment”, “caring”, “wellness”, “dental”, “patients”, “pharma”, “pharmacy”, “radiology”, “biomedical”, “insurance”, “care taker”, “health care”, “mental health”, “dental health”, “bio science”, “clinic”, “drug”, “effective”, “seeking”, “consumer”, “safety”}. We have recorded bloom filter generation time for 5 attributes, 10 attributes and 20 attributes. Fig. 4.9 shows content of bloom filter after adding attributes. Fig 4.7 and 4.8 show graphical representation of bloom filter generation time. Table 4.3 shows bloom filter generation time.
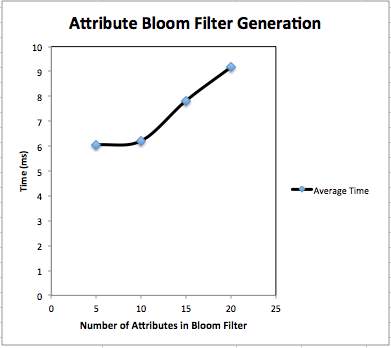
Fig. 4.7 Average time for Attribute Bloom Filter generation
Table 4.3 Time for Attribute Bloom Filter generation
| Trial No. | Time (5 Attributes) (sec.) | Time (10 Attributes) (sec.) | Time (20 Attributes) (sec.) |
| 1 | 7.761 | 9.980 | 8.620 |
| 2 | 4.350 | 4.660 | 8.550 |
| 3 | 7.070 | 8.173 | 9.546 |
| 4 | 6.230 | 4.020 | 10.770 |
| 5 | 4.860 | 4.247 | 8.378 |
| Average | 6.054 | 6.216 | 9.1728 |
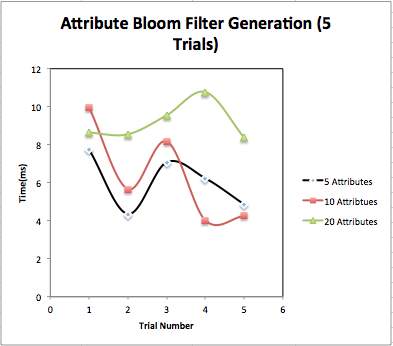
Fig. 4.8 Comparison of Attribute Bloom Filter generation for different number of attributes
Fig. 4.9 Attribute Bloom Filter content
5. Application
Attribute Based Encryption (ABE) can be used in various applications such as online social media photo sharing and Electronic Health Record (EHR) system. Our proposed scheme can also apply to EHR systems to manage access control of health records of patient.
Paper based health record is expensive and not patient friendly when patient want to share health records to other doctor, researcher or insurance company. Using EHR, patient can transfer health records easily and with almost no manpower [36].
However, moving from paper based health record to electronic health record required attention towards various security issues. Patient’s privacy [27] is also need to maintain to protect patient’s sensitive information.
So, patients want more privacy when health record is transferred to digital electronic health record (EHR) and upload it to cloud. Cipher-text attribute based encryption (CPABE) can be applied on health record and encrypted health records are uploaded on cloud. By using CPABE, security and privacy of electronic health records (EHR) will be preserved.
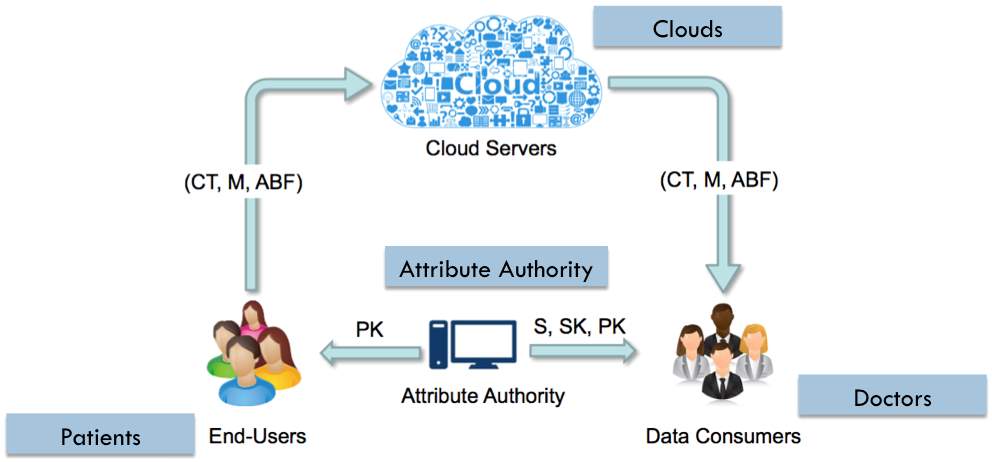
Fig. 5.1 Electronic Health Record (EHR) System [17]
As mentioned in our proposed scheme, there are 4 entities such as data owner (End Users in Fig. 5.1), cloud servers, attribute authority and data consumers. As shown in Fig. 5.1, Electronic Health Record (EHR) system also consist four parties, patients will be data owner of the Electronic Health Record (EHR), cloud and attribute authority will be same as proposed scheme and doctor, researcher or insurance company can be taken as data consumer, who want to access health records of patients.
6. Action Plan
Table 6.1 Action Plan
| Sr. No. | Month | Topic Covered, broadly |
| 1 | July |
|
| 2 | August |
|
| 3 | September |
|
| 4 | October |
|
| 5 | November |
|
| 6 | December |
|
| 7 | January |
|
| 8 | February |
|
| 9 | March |
|
7. Conclusion and Future Work
We have surveyed and summarized various issues/challenges of Big Data. Furthermore, we have expanded survey to study security and privacy issues such as confidentiality, integrity, availability, key management, monitoring and auditing.
Big Data access control schemes such as KP-ABE, KP-WABE, CP-ABE, CP-WABE and CPABE with privacy preservation policy are studied in detail. We have observed that existing scheme of cipher text policy attribute based encryption with privacy preservation policy cannot provide the protection against “offline attribute guessing attack”. To overcome this issue, we have proposed access control scheme, which can cope against offline attribute guessing attack. We have studied Electronic Health Record (EHR) system and mapped with our proposed scheme. We have also implemented key generation of public key and master key as well as Attribute Bloom Filter generation from attribute mapping function is also implemented.
In future, we will implement proposed scheme with Electronic Health Record (EHR) system on real healthcare dataset and will evaluate it.
REFERENCES
[1] C. Philip Chen and C. Zhang, “Data-intensive applications, challenges, techniques and technologies: A survey on Big Data”, Information Sciences, vol. 275, 2014, pp. 314-347.
[2] D. Terzi, R. Terzi and S. Sagiroglu, “A survey on security and privacy issues in big data”, 2015 10th International Conference for Internet Technology and Secured Transactions (ICITST), 2015, pp. 202-207.
[3] E. Bertino, “Big Data – Security and Privacy”, 2015 IEEE International Congress on Big Data, 2015, pp. 757-761.
[4] K. Hakuta and H. Sato, “Cryptographic Technology for Benefiting from Big Data”, The Impact of Applications on Mathematics, 2014, pp. 85-95.
[5] B. Matturdi, X. Zhou, S. Li, F. Lin, “Big Data security and privacy: A review”, Big Data, Cloud & Mobile Computing, China Communications vol.11, issue: 14, 2014, pp. 135 – 145.
[6] Xindong Wu, Xingquan Zhu, Gong-Qing Wu and Wei Ding, “Data mining with big data”, IEEE Trans. Knowl. Data Eng., vol. 26, no. 1, 2014, pp. 97-107.
[7] Y. Demchenko, C. Ngo, C. de Laat, P. Membrey and D. Gordijenko, “Big Security for Big Data: Addressing Security Challenges for the Big Data Infrastructure”, Lecture Notes in Computer Science, 2014, pp. 76-94.
[8] I. Hashem, I. Yaqoob, N. Anuar, S. Mokhtar, A. Gani and S. Ullah Khan, “The rise of “big data” on cloud computing: Review and open research issues”, Information Systems, vol. 47, 2015, pp. 98-115.
[9] Weichang Kong, Qidi Wu, Li Li and Fei Qiao, “Intelligent Data Analysis and its challenges in big data environment”, 2014 IEEE International Conference on System Science and Engineering (ICSSE), 2014, pp. 108-113.
[10] [Online] Challenges and Opportunities with Big Data”, Purdue Univesity, 2016. [https://www.purdue.edu/discoverypark/cyber/assets/pdfs/BigDataWhitePaper.pdf. [Accessed: 12- Jan- 2017].
[11] Z. Azmi, “Opportunities and Security Challenges of Big Data”, Current and Emerging Trends in Cyber Operations, 2015, pp. 181-197.
[12] B. Glavic, “Big Data Provenance: Challenges and Implications for Benchmarking”, Specifying Big Data Benchmarks, 2014, pp. 72-80.
[13] M. Chen, S. Mao and Y. Liu, “Big Data: A Survey”, Mobile Networks and Applications, vol. 19, no. 2, 2014, pp. 171-209.
[14] L. Xu and W. Shi, “Security Theories and Practices for Big Data”, Big Data Concepts, Theories, and Applications, 2016, pp. 157-192.
[15] S. Sudarsan, R. Jetley and S. Ramaswamy, “Security and Privacy of Big Data”, Studies in Big Data, 2015, pp. 121-136.
[16] Y. Jeong and S. Shin, “An Efficient Authentication Scheme to Protect User Privacy in Seamless Big Data Services”, Wireless Personal Communications, vol. 86, no. 1, 2015, pp. 7-19.
[17] K. Yang, Q. Han, H. Li, K. Zheng, Z. Su and X. Shen, “An Efficient and Fine-grained Big Data Access Control Scheme with Privacy-preserving Policy”, IEEE Internet of Things Journal, 2016, pp. 1-8.
[18] “Types of Network Attacks against Confidentiality, Integrity and Avilability”, Omnisecu.com, 2017. [Online]. Available: http://www.omnisecu.com/ccna-security/types-of-network-attacks.php. [Accessed: 23- Jan- 2017].
[19] R. Alguliyev and Y. Imamverdiyev, “Big Data: Big Promises for Information Security,” 2014 IEEE 8th International Conference on Application of Information and Communication Technologies (AICT), Astana, 2014, pp. 1-4.
[20] Y. Gao, X. Fu, B. Luo, X. Du and M. Guizani, “Haddle: A Framework for Investigating Data Leakage Attacks in Hadoop,” 2015 IEEE Global Communications Conference (GLOBECOM), San Diego, CA, 2015, pp. 1-6.
[21] “SANS Institute InfoSec Reading Room”, Sans.org, 2017. [Online]. Available: https://www.sans.org/reading-room/whitepapers/dlp/data-loss-prevention-32883. [Accessed: 24- Jan- 2017].
[22] Y. Jeong and S. Shin, “An Efficient Authentication Scheme to Protect User Privacy in Seamless Big Data Services”, Wireless Personal Communications, vol. 86, no. 1, 2015, pp. 7-19.
[23] D. Puthal, S. Nepal, R. Ranjan and J. Chen, “A Dynamic Key Length Based Approach for Real-Time Security Verification of Big Sensing Data Stream”, Lecture Notes in Computer Science, 2015, pp. 93-108.
[24] H. Kim, I. Kim and T. Chung, “Abnormal Behavior Detection Technique Based on Big Data”, Lecture Notes in Electrical Engineering, 2014, pp. 553-563.
[25] C. Liu, R. Ranjan, C. Yang, X. Zhang, L. Wang and J. Chen, “MuR-DPA: Top-Down Levelled Multi-Replica Merkle Hash Tree Based Secure Public Auditing for Dynamic Big Data Storage on Cloud,” in IEEE Transactions on Computers, vol. 64, no. 9, 2015, pp. 2609-2622.
[26] H. Heni and F. Gargouri, “A Methodological Approach for Big Data Security: Application for NoSQL Data Stores”, Neural Information Processing, 2015, pp. 685-692.
[27] F. Rahman, S. Ahamed, J. Yang and Q. Wang, “PriGen: A Generic Framework to Preserve Privacy of Healthcare Data in the Cloud”, Inclusive Society: Health and Wellbeing in the Community, and Care at Home, 2013, pp.77-85.
[28] S. Fugkeaw and H. Sato, “Privacy-preserving access control model for big data cloud”, 2015 International Computer Science and Engineering Conference (ICSEC), 2015, pp. 1-6.
[29] V. goyal, O. pandey, “Attribute based Encryption for fine grain access control of encrypted data,” 13th ACM 1 conference on computer and communication security, 2006, pp. 89-98.
[30] J. Bethencourt, A. Sahai, B. Waters, “Cipher text-Policy Attribute-Based Encryption”, IEEE Security and Privacy, SP ‘07. IEEE Symposium, Berkeley, CA, 2007, pp. 321 – 334.
[31] X. Liu, H. Zhu, Ji. Ma, Ju. Ma, S. Ma, “Key-Policy Weighted Attribute Based Encryption for Fine-Grained Access Control”, IEEE Communications Workshops (ICC), 2014 IEEE International Conference, Sydney, NSW, 2014, pp. 694 – 699.
[32] X. Liu, J. Ma, J. Xiong, Q. Li, Ju Ma, “Cipher text-Policy Weighted Attribute Based Encryption for Fine-Grained Access Control”, IEEE 5th Intelligent Networking and Collaborative Systems (INCoS), 2013 5th International Conference on , Xi’an , 2013 pp.51 – 57.
[33] Y. Kanbara, T. Teruya, N. Kanayama, T. Nishide and E. Okamoto, “Software Implementation of a Pairing Function for Public Key Cryptosystems,” 2015 5th International Conference on IT Convergence and Security (ICITCS), Kuala Lumpur, 2015, pp. 1-5.
[34] Using a bloom filter to reduce expensive operations like disk IO « kellabyte”, Kellabyte.com, 2016. [Online]. Available: http://kellabyte.com/2013/01/24/using-a-bloom-filter-to-reduce-expensive-operations-like-disk-io/. [Accessed: 22- Jan- 2017].
[35] Caro, A.: JPBC – Java Pairing-Based Cryptography Library: Introduction, http://gas.dia.unisa.it/projects/jpbc/. [Accessed: 01- Feb- 2017].
[36] D. Williams, I. Addo, G. Ahsan, F. Rahman, C. Tamma and S. Ahamed, “Privacy in Healthcare”, Computer Communications and Networks, 2015, pp. 85-110.
Appendix A – Publication Details
| Paper Title | Big Data Security and Privacy Issues – A Survey |
| Publication | IEEE Digital Explore library |
| Conference Name | International Conference on Innovations in Power and Advanced Computing Technologies (Scopus Indexed-IEEE Digital Library) |
| Conference ID | 40628 |
| Paper Status | Accepted / Presented |
| Conference Date | April 21-22, 2017 |
| Conference Venue | VIT, Chennai, INDIA |
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Cyber Security"
Cyber security refers to technologies and practices undertaken to protect electronics systems and devices including computers, networks, smartphones, and the data they hold, from malicious damage, theft or exploitation.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: